MVVM与事件驱动模型
Jetpack中有多组件时专门为了MVVM架构而量身打造的组件,MVVM被广泛应用与Android开发中。Vue通过ViewModel实现了双向绑定(也是一种MVVM架构),而开发者只需要处理和维护ViewModel,更新数据视图就会自动得到相应更新,真正实现了事件驱动编程。那么本篇来看看什么是MVC、MVP、MVVM,以及什么是事件驱动编程。
MVC模式
MVC,即 Model 模型、View 视图,及 Controller 控制器。 View:视图,为用户提供使用界面,也就是CSS+HTML,与用户直接进行交互。 Model:模型,承载数据,并对用户提交请求进行计算的模块。 Controller:控制器,请求转发给相应的 Model 进行处理,提供相应响应,以及路由。
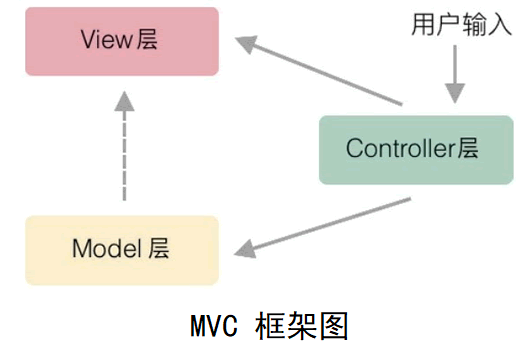
对于MVC模式,只要用过 SpringMVC + 模板引擎的都清楚,MVC 是一个非常好的协作模式,能够有效降低代码的耦合度,为了让 View 更纯粹,还可以使用 Thymeleaf、Freemarker 等模板引擎,使模板里无法写入 Java 代码,让前后端分工更加清晰。
主要缺点就是 MVC 的大部分逻辑都集中在 Controller 层,代码也集中在 Controller 层,这带给 Controller 层很大的压力,而已经有独立处理事件能力的 View 层却没有用到;还有一个问题,就是 Controller 层和 View 层之间是一一对应的,导致 View 无法复用。
MVP模式
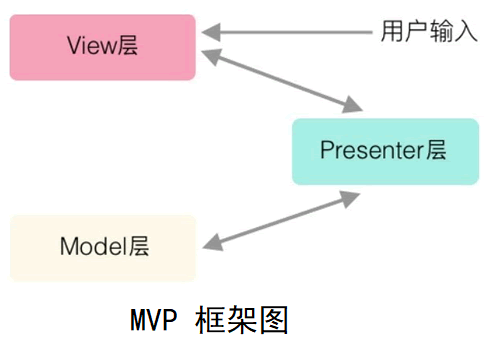
在 MVC 框架中,View 层可以通过访问 Model 层来更新,但在 MVP 框架中,View 层不能再直接访问 Model 层,必须通过 Presenter 层提供的接口,然后 Presenter 层再去访问 Model 层。
因为 Model 层和 View 层都必须通过 Presenter 层来传递信息,所以完全分离了 View 层和 Model 层,也就是说,View 层与 Model 层一点关系也没有,双方是不知道彼此存在的,在它们眼里,只有 Presenter 层,而且View 层与 Model 层没有关系,所以 View 层可以抽离出来做成组件,在复用性上比 MVC 模型好很多。
也正是因为 View 层和 Model 层都需经过 Presenter 层,致使 Presenter 层比较复杂,维护起来会有一定的问题。而且因为没有绑定数据,所有数据都需要 Presenter 层进行 “手动同步” 。
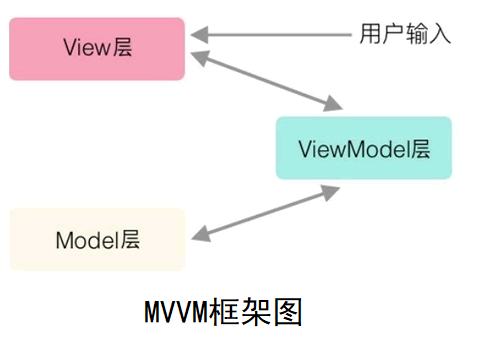
为了让 View 层和 Model 的数据始终保持一致,避免同步,MVVM 框架出现了。
MVVM模式
为了让 View 层和 Model 的数据始终保持一致,避免同步,MVVM 框架出现了。
视图状态和行为都封装在了 ViewModel 里。这样的封装使得 ViewModel 可以完整地去描述 View 层。由于实现了双向绑定,ViewModel 的内容会自动地实时展现在 View 层,这是最激动人心的,因为前端开发者再也不必低效又麻烦地通过操纵 DOM 去更新视图。
MVVM 框架已经把最脏最累的一块做好了,我们开发者只需要处理和维护 ViewModel,更新数据视图就会自动得到相应更新,真正实现事件驱动编程。
事件驱动编程
首先思考一个问题,Vue的ViewModel是如何获取数据的实时变化呢?最简单的方案就是:直接用while(true)暴力轮询即可。虽然这种方式太低效,但实际上这可能是异步情况下唯一的办法。
前端代码要想知道用户输入数据或DOM的实时变化,通过浏览器提供的API注册EventListener即可,Vue、React这类MVVM框架提供了更完善的数据驱动机制,但框架实现也需要注册EventListener。事件回调机制看似不是在轮询,变化直接调用回调函数了,但底层仍是依托于浏览器中的Event Loop轮询任务队列实现的。
可以得出:要知道实时变化,总得有一个 while true。
对于后端服务来说,A服务改了数据X,B服务怎么才能感知到数据X被修改了呢?
方案一:B服务轮询A服务,数据X变了吗?数据X变了吗?数据X变了吗?……
方案二:A直接告诉B,A通过同步的RPC或HTTP调用B(视作Subject通知Observer的观察者模式);
方案三:A把消息放出去,B通过同步或异步的消息队列去订阅(视作发布订阅模式)。
当该业务实现是A服务强依赖B服务并且一定要同步调用时,用方案二是合适的;当A服务不需要强依赖B时,引入消息队列干掉A、B之间的耦合,用方案三是比较好的。
方案二、方案三都不用在业务上轮询了。然而这两种方式中,真的没有"while true"的存在了吗?其实不然,我们可以看看隐藏在BIO、NIO、I/O多路复用中的轮询,其实无论是观察者模式,还是发布订阅模式,这些操作,是把上层数据的变化的事件转换成了底层网络数据包读写的事件,复用了底层的 “I/O事件循环”,进而避免业务层用循环+ Sleep的轮询带来的开销,并具有更高的实时性,下面就是使用epoll的一小段代码:
while (1) {
// 轮询epoll文件描述符
epoll_wait(..)
// process events
}
复用了底层的轮询,上层被抽象成事件模型,在I/O线程的"while true"里干掉了所有非阻塞的事,避免大量线程都在轮询带来的Context Switch白耗CPU。并且,这类底层事件队列的轮询大多数是阻塞式的,比如epoll_wait,没有事件发生时也不占用CPU时间片,因此效率很高,Netty、Nginx均用到了这个特性。
所以归根结底,事件驱动模式底层的核心机制就是轮询事件队列。当我们把可复用的轮询藏到底层时,上层就抽象出了一个强大的事件驱动模型,将该模型应用到软件系统的设计层面,就是事件驱动编程。