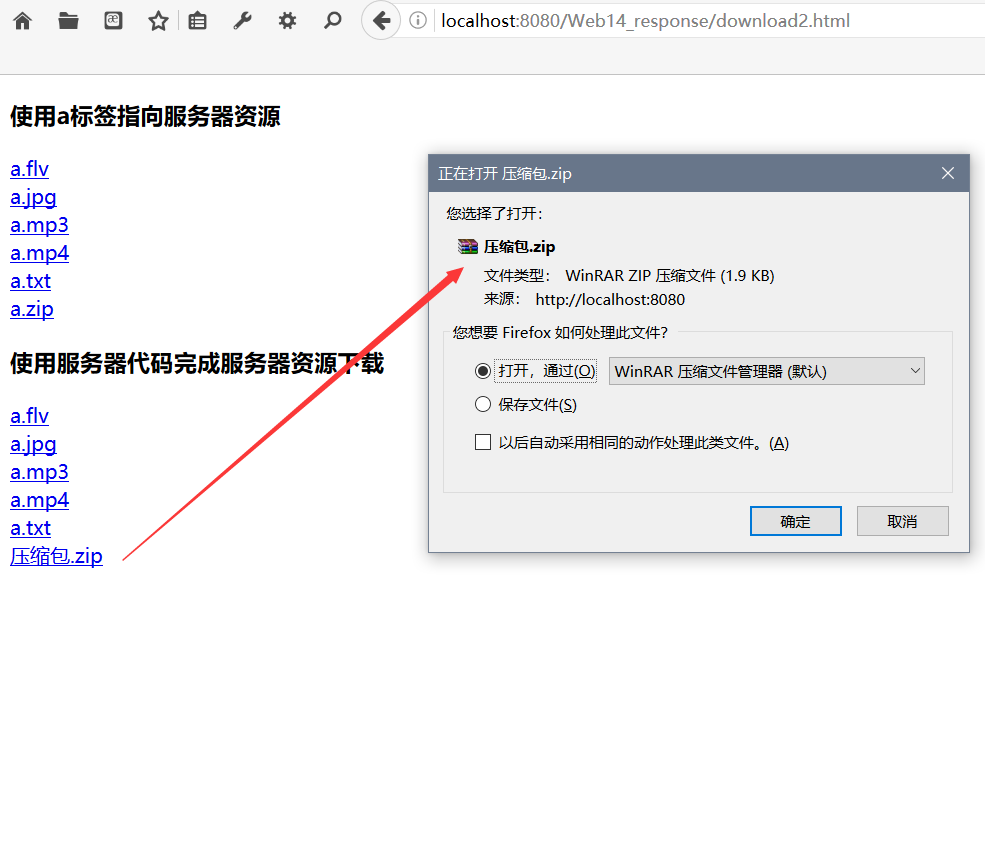
下载中文文件乱码解决方式
关于编码的问题有几点需要说清楚:UTF-8国际编码,GBK中文编码。GBK包含GB2312,即如果通过GB2312编码后可以通过GBK解码,反之可能不成立;英文文字就是26个字母,真正的对应关系就是ASCII码表中的关系,但是如何表示汉字呢?很显然也需要一套对应的码表,于是UTF-8、GBK、GB2312这些编码方式就是为了解决这个问题的。
下面看看正题:首先我的目录是:压缩包即是我要下载的文件
我的下载界面:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3> 使用a标签指向服务器资源 </h3>
<a href="/Web14_response/download/a.flv">a.flv</a><br>
<a href="/Web14_response/download/a.jpg">a.jpg</a><br>
<a href="/Web14_response/download/a.mp3">a.mp3</a><br>
<a href="/Web14_response/download/a.mp4">a.mp4</a><br>
<a href="/Web14_response/download/a.txt">a.txt</a><br>
<a href="/Web14_response/download/a.zip">a.zip</a><br>
<h3> 使用服务器代码完成服务器资源下载 </h3>
<a href="/Web14_response/DownloadServlet2?filename=a.flv">a.flv</a><br>
<a href="/Web14_response/DownloadServlet2?filename=a.jpg">a.jpg</a><br>
<a href="/Web14_response/DownloadServlet2?filename=a.mp3">a.mp3</a><br>
<a href="/Web14_response/DownloadServlet2?filename=a.mp4">a.mp4</a><br>
<a href="/Web14_response/DownloadServlet2?filename=a.txt">a.txt</a><br>
<a href="/Web14_response/DownloadServlet2?filename=压缩包.zip">压缩包.zip</a><br>
</body>
</html>
提供文件下载的Servlet:
package com.xpu.content;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import sun.misc.BASE64Encoder;
public class DownloadServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 这个主要是下载中文的
// 获取要下载的文件的名称
String filename = request.getParameter("filename");
// 解决获得中文参数的乱码
filename = new String(filename.getBytes("ISO8859-1"), "UTF-8");
// 设置头信息
response.setContentType(getServletContext().getMimeType(filename));
String agent = request.getHeader("User-Agent");
String filenameEncoder = "";
if (agent.contains("MSIE")) {
// IE浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
filenameEncoder = filename.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filenameEncoder = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
}
response.setHeader("Content-Disposition", "attachment;filename=" + filenameEncoder);
System.out.println(filename);
// 获取文件的绝对路径
String path = getServletContext().getRealPath("/download/" + filename);
// 获取该文件的输入流
InputStream is = new FileInputStream(path);
// 获取输出流
ServletOutputStream os = response.getOutputStream();
// 文件拷贝的模板代码
int len = 0;
byte[] bys = new byte[1024];
while ((len = is.read(bys)) != -1) {
os.write(bys, 0, len);
}
is.close();
}
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
下载效果: