CNN卷积神经网络(二)
在本节中将继续探讨CNN的核心概念以及一些经典的CNN框架(LeNet、AlexNet、VGG16等),以更好地理解这一强大的图像处理工具。卷积神经网络是一种深度学习模型,广泛应用于图像识别和处理任务。CNN通过卷积层、池化层和全连接层等结构,能够有效提取图像中的特征信息,从而实现分类、检测等任务。
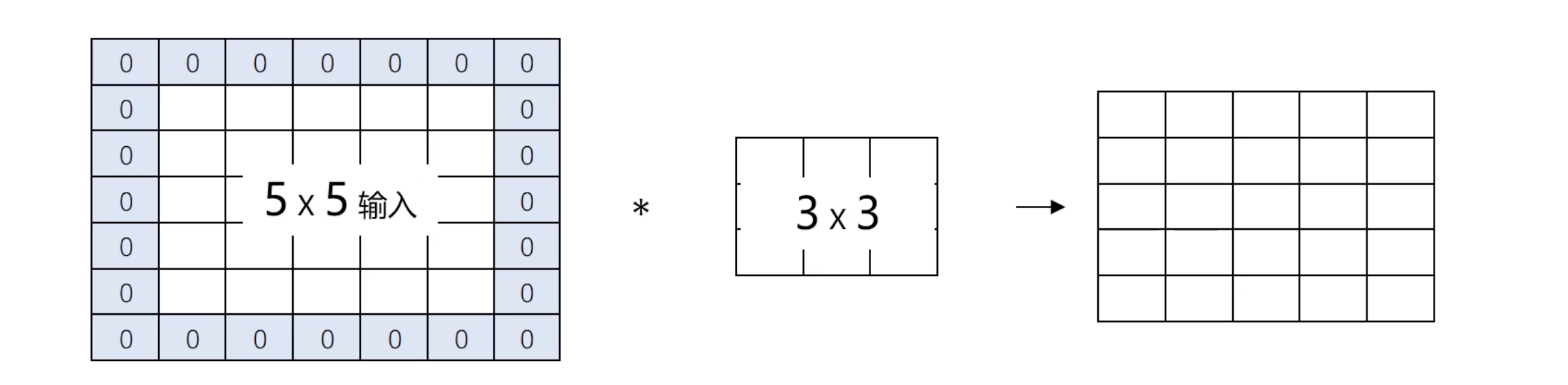
Padding填充技术
卷积是CNN的核心操作之一。通过滑动窗口(卷积核)在输入图像上进行计算,CNN能够提取出图像的边缘、纹理等重要特征。然而,卷积操作也会导致图像尺寸的减小和边缘信息的丢失。
为了避免信息丢失,通常会在图像边缘添加填充(padding),使得卷积后的输出尺寸与输入相同。填充可以是零填充,即在图像的四周添加零值像素,以确保卷积操作不会过多地缩小图像尺寸。
经典的CNN框架
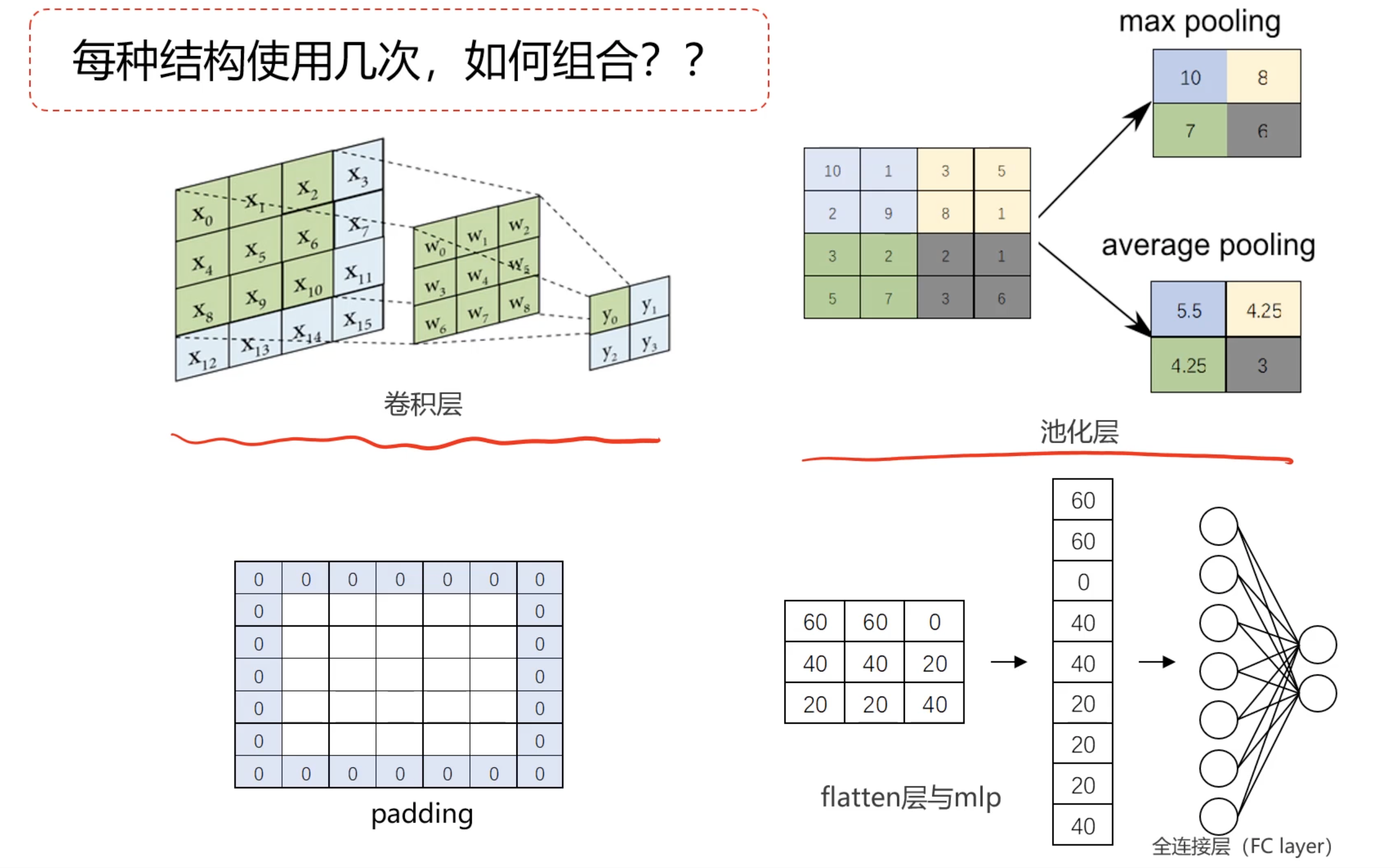
接下来,我们将介绍三种经典的CNN框架:LeNet-5、AlexNet和VGG16。一般来说我们要么通过经典的CNN模型搭建自己新模型,也可以直接使用经典CNN模型结构对图形进行预处理,再建立MLP模型。
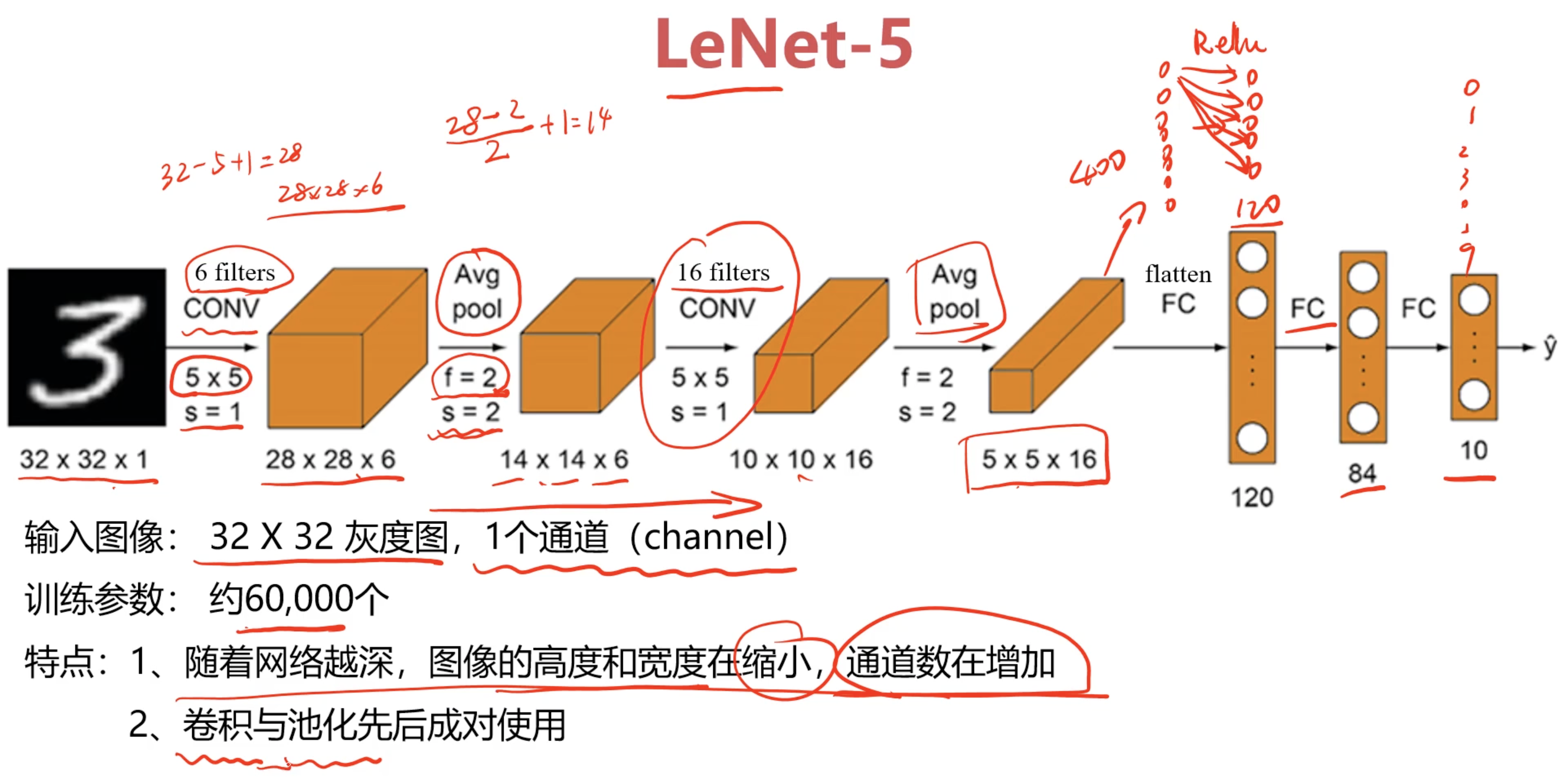
LeNet-5
LeNet-5是最早的卷积神经网络之一,最初设计用于自动读取邮政编码、分类邮件等任务。它的成功为后来的计算机视觉任务奠定了基础。LeNet的特点是参数较少,适合简单的图像分类任务。其结构包括多个卷积层和池化层,最终通过全连接层输出分类结果。
网络层详解:
- C1(卷积层):生成六个特征图,内核大小为 5x5。每个特征图的尺寸为 28x28 像素。
- S2(池化层):对 C1 的输出进行下采样,将特征图的尺寸减半,生成六个新的特征图,每个特征图的尺寸为 14x14 像素。
- C3(卷积层):生成十个特征图,内核大小为 5x5,输出特征图的尺寸为 10x10 像素。
- S4(池化层):对 C3 的输出进行下采样,生成十个特征图,每个特征图的尺寸为 5x5 像素。
- C5(卷积层):生成 120 个特征图,内核大小为 5x5,输出特征图的尺寸为 1x1 像素。
- F6(全连接层):连接到 84 个神经元。
- 输出层:最终输出分类结果。
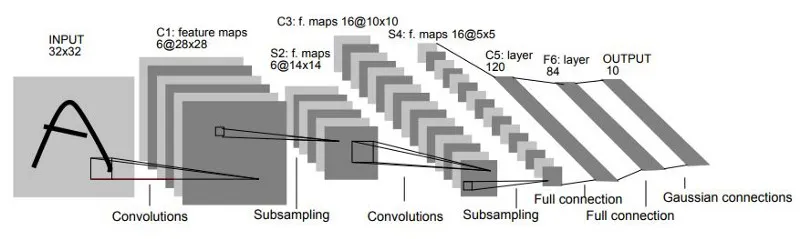
LeNet-5 是卷积神经网络的经典模型,尽管其结构相对简单,但在图像分类任务中表现出色。下图是LeNet-5应用于MNIST 数据集的手写数字识别任务时不断卷积和池化的过程:
AlexNet
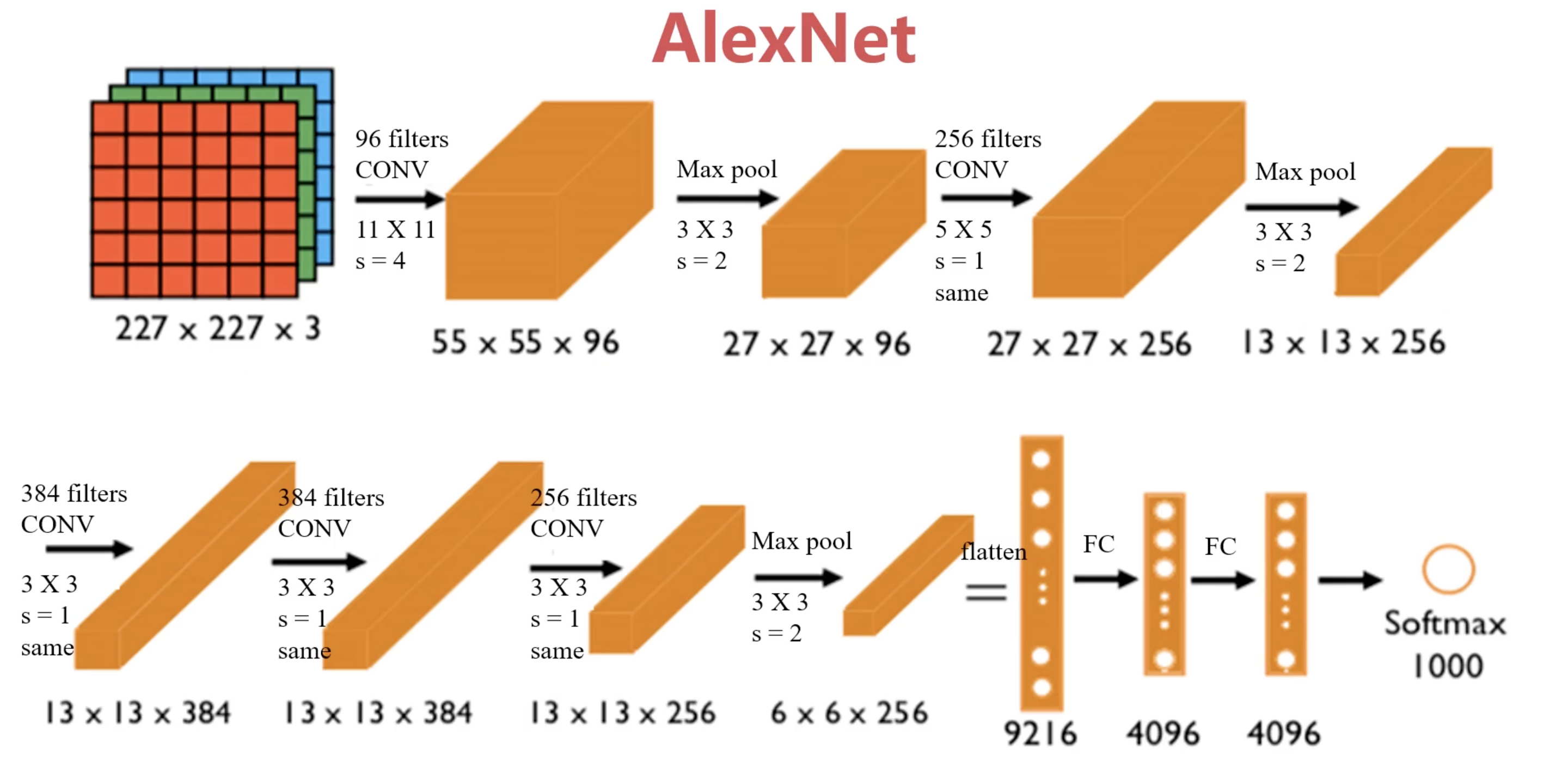
AlexNet是深度学习领域的一个里程碑,标志着CNN在图像识别中的成功应用。其结构较LeNet更为复杂,能够处理RGB彩色图像,训练参数约60000000个。AlexNet的成功在于其使用了Relu激活函数和Dropout技术,有效缓解了过拟合问题。
AlexNet的架构:
AlexNet由五个卷积层和三个全连接层组成,具体架构如下:
- 输入层:输入图像的大小为224x224x3(RGB图像)。
- 卷积层:
- 第一层:使用96个11x11的卷积核,步幅为4,激活函数为ReLU。
- 第二层:使用256个5x5的卷积核,步幅为1,激活函数为ReLU。
- 第三层:使用384个3x3的卷积核,步幅为1,激活函数为ReLU。
- 第四层:使用384个3x3的卷积核,步幅为1,激活函数为ReLU。
- 第五层:使用256个3x3的卷积核,步幅为1,激活函数为ReLU。
- 池化层:在卷积层之间,使用最大池化层(Max Pooling)来减少特征图的维度。
- 全连接层:
- 第一层:4096个神经元,激活函数为ReLU。
- 第二层:4096个神经元,激活函数为ReLU。
- 第三层:使用Softmax激活函数进行分类,输出1000个类别。
ReLU激活函数:在AlexNet中,首次大规模使用了ReLU(修正线性单元)作为激活函数,相较于传统的Sigmoid,ReLU在训练过程中能够更快地收敛,并且有效地减轻了梯度消失的问题。
Dropout正则化:为了防止过拟合,AlexNet引入了Dropout技术。在训练过程中随机丢弃一定比例的神经元,这种方法有效地增强了模型的泛化能力。
VGG16
VGG16是一种更深的卷积神经网络,所有的卷积层均使用3x3的卷积核,步长为1,且在每次卷积后都会进行填充。这种设计使得网络更加稳定。
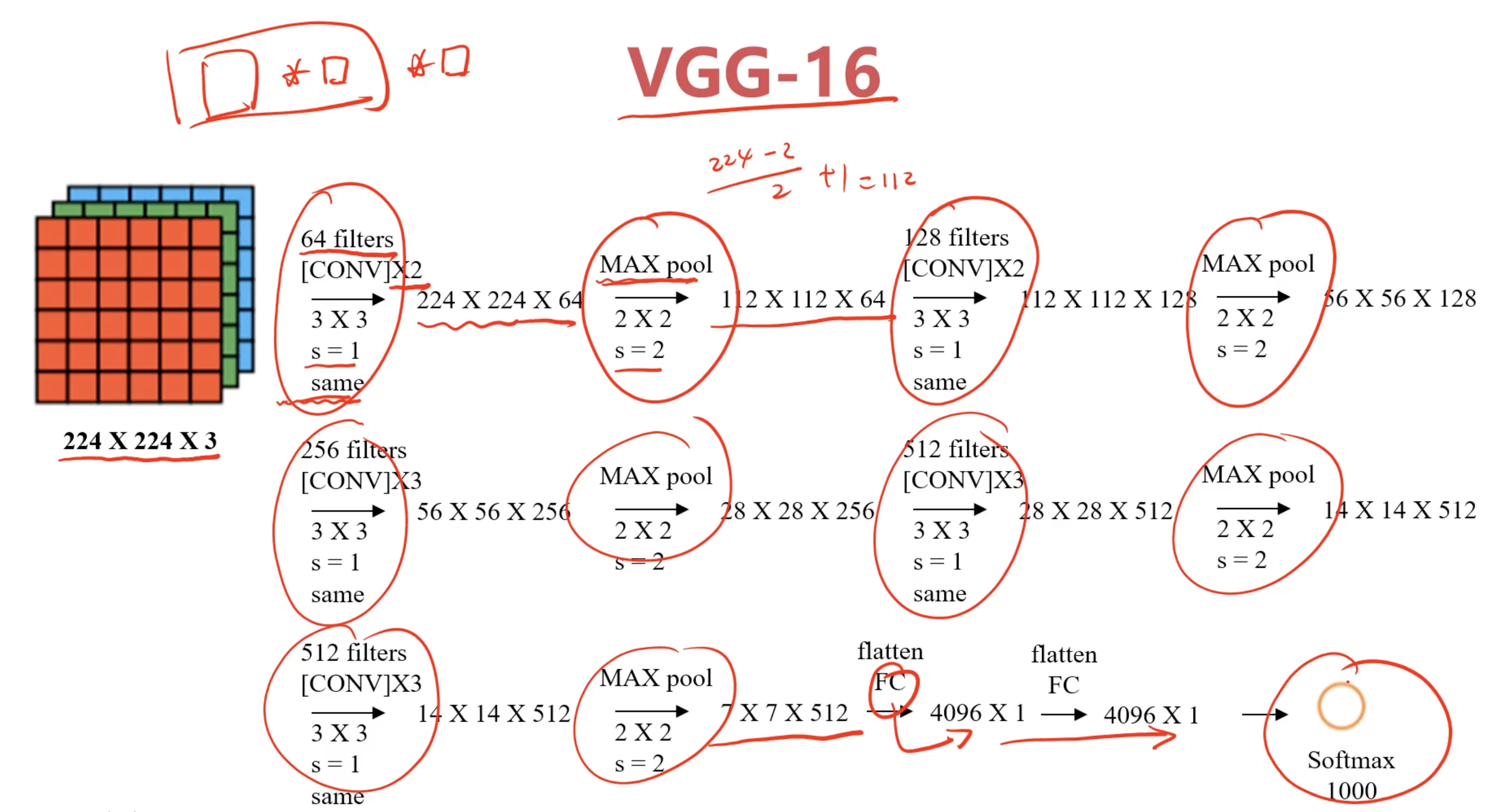
上图演示的VGG16的卷积和池化的过程有点抽象,来个具象的示意图:
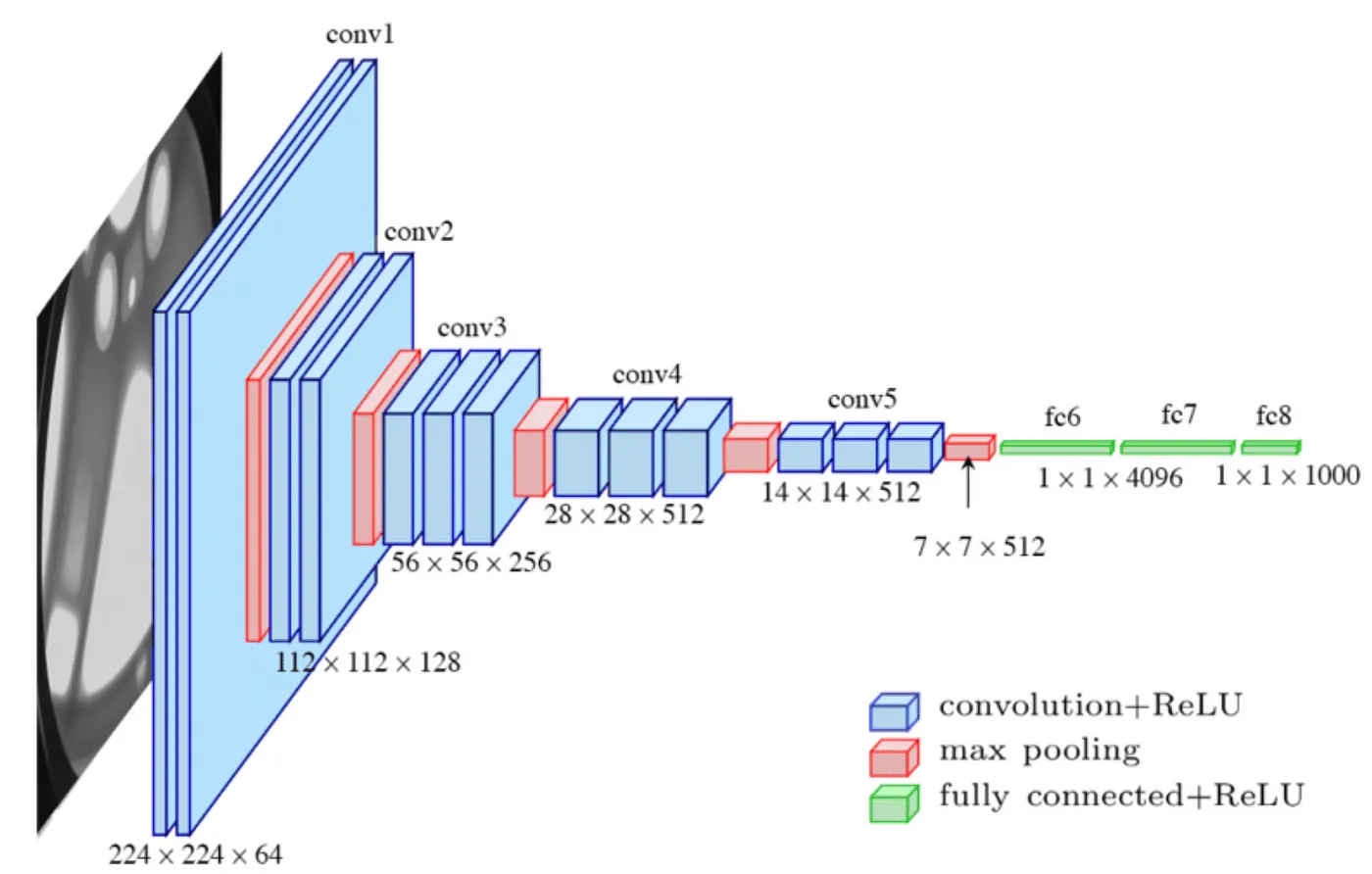
VGG16 由牛津大学的视觉几何组(Visual Geometry Group)在2014年提出。它因其简单而有效的设计在图像分类任务中表现出色。以下是 VGG16 的详细架构:
架构概述:
- 输入层: 接受大小为 224x224x3 的彩色图像。
- 卷积层: 共有 13 个卷积层,所有卷积层使用 3x3 的卷积核,步幅为 1,填充为 1,以保持图像的空间分辨率。
- 激活函数: 每个卷积层后面都跟随一个 ReLU 激活函数。
- 池化层: 使用 2x2 的最大池化层,步幅为 2,用于降低特征图的尺寸。
- 全连接层: 3 个全连接层,其中前两个有 4096 个神经元,最后一个有 1000 个神经元(用于 1000 类分类任务)。
- 输出层: 使用 Softmax 激活函数输出类别概率。
详细层次结构
卷积块1:
- Conv1_1: 64 个 3x3 卷积核
- Conv1_2: 64 个 3x3 卷积核
- Max Pooling
卷积块2:
- Conv2_1: 128 个 3x3 卷积核
- Conv2_2: 128 个 3x3 卷积核
- Max Pooling
卷积块3:
- Conv3_1: 256 个 3x3 卷积核
- Conv3_2: 256 个 3x3 卷积核
- Conv3_3: 256 个 3x3 卷积核
- Max Pooling
卷积块4:
- Conv4_1: 512 个 3x3 卷积核
- Conv4_2: 512 个 3x3 卷积核
- Conv4_3: 512 个 3x3 卷积核
- Max Pooling
卷积块5:
- Conv5_1: 512 个 3x3 卷积核
- Conv5_2: 512 个 3x3 卷积核
- Conv5_3: 512 个 3x3 卷积核
- Max Pooling
全连接层:
- FC6: 4096 个神经元
- FC7: 4096 个神经元
- FC8: 1000 个神经元
其主要特点如下:
- 小卷积核: 采用 3x3 的小卷积核,增加了网络深度,同时保持了较少的参数量。
- 统一结构: 每个卷积块中的卷积层数量和池化层位置固定,易于理解和实现。
- 迁移学习: 由于其预训练的权重在多种数据集上表现优异,VGG16 常用于迁移学习。
VGG16 的设计虽然简单,但在多个计算机视觉任务中表现优异,尤其在 ImageNet 图像分类挑战中取得了良好的成绩。
Reference
通过对LeNet、AlexNet和VGG16的了解,我们可以看到卷积神经网络在图像处理中的强大能力。每种模型都有其独特的设计理念和适用场景,在构建自己的CNN模型时,可以参考这些经典框架,结合实际需求进行调整和优化。接下将深入探讨如何利用这些经典模型进行实际的图像识别任务,以及如何根据具体应用场景设计自己的CNN结构。