LinkHashMap与LRU
Android 为我们提供了 LruCache 类,LruCache提供了一种使用LRU缓存的数据结构,里面本质还是对LinkedHashMap的封装。如果你深入研究 LinkedHashMap 的实现原理,就会发现其中就用到了双向链表这种数据结构。LRU (Least Recently Used) 的意思就是近期最少使用算法,它的核心思想就是会优先淘汰那些近期最少使用的缓存对象。
LinkedHashMap
JDK文档地址:https://docs.oracle.com/javase/9/docs/api/java/util/LinkedHashMap.html
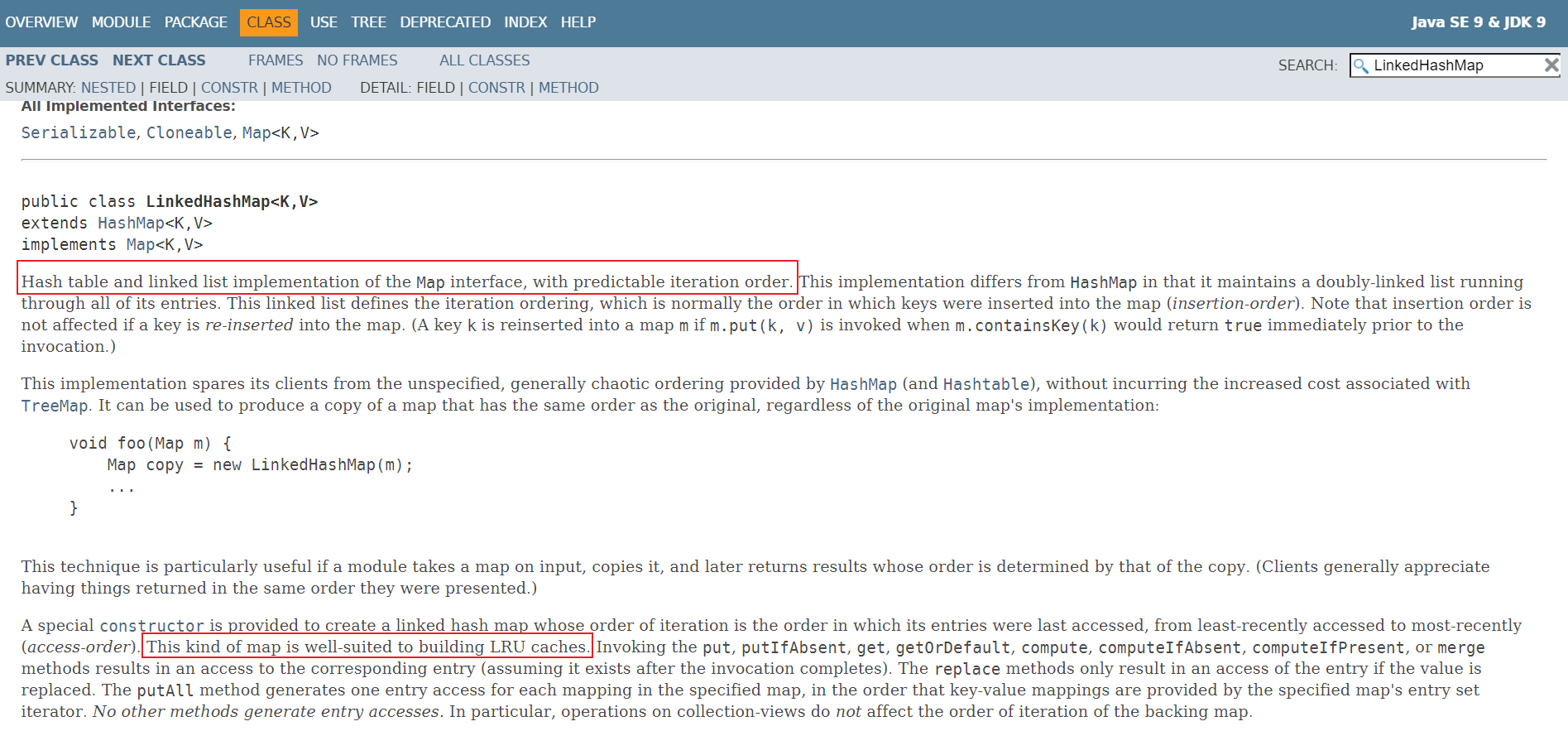
通过查看LinkedHashMap的文档我们不难得出以下结论:
1、LinkedHashMap继承自HashMap,同时通过双向链表维持迭代元素的有序性(默认插入顺序迭代)
2、 如果在映射中重新插入键,则插入顺序不受影响(如果在调用 m.put(k, v) 前 m.containsKey(k) 返回了 true,则调用时会将键 k 重新插入到映射 m 中)
3、 LinkedHashMap这种结构很适合用来构建LRU 缓存
4、由于底层是HashMap,所以也支持null Key
5、 由于增加了维护链接列表的开支,其性能很可能比HashMap稍逊一筹,不过迭代时间比HashMap快,因为HashMap需要迭代table中的null,而LinkedHashMap直接迭代链表就行
6、底层是HashMap,所以线程也不安全
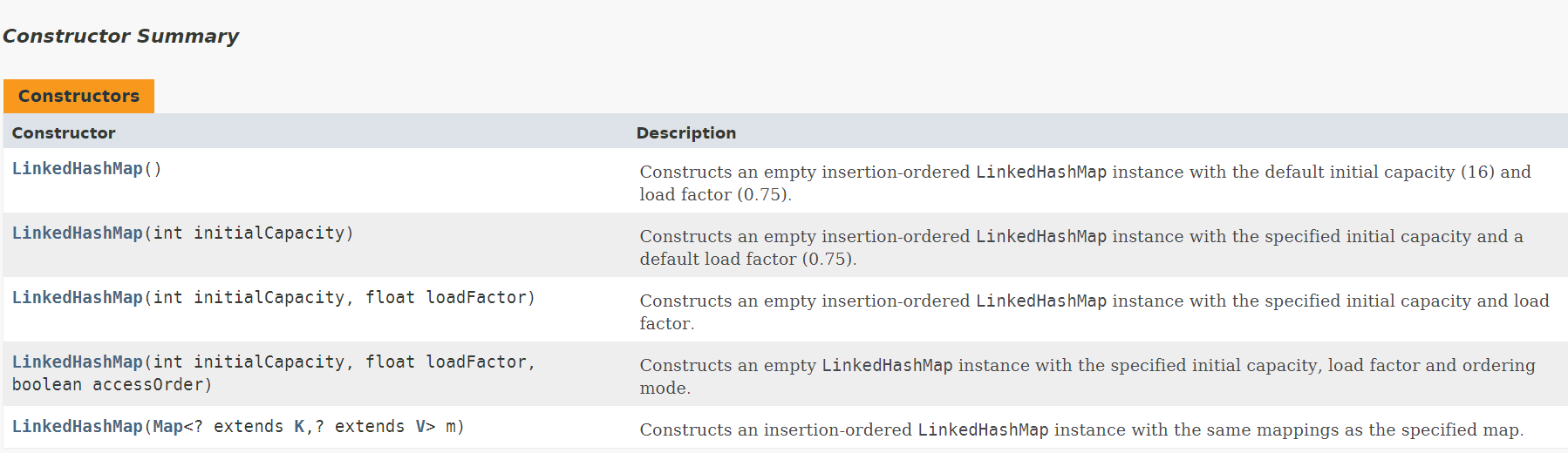
构造方法
构造方法一共有5个:
// true 表示访问顺序、 false表示插入顺序
final boolean accessOrder;
// 默认插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 给HashMap指定初始化容量
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 给HashMap指定初始化容量和负载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 根据另一个Map初始化自己
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 指定容量、负载因子、排序方式
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
put()方法
其实put()方法调用的是父类HashMap的put()方法,但是其中的newNode()方法被LinkedHashMap重写了,所以LinkedHashMap只不过是重写了newNode从而实现了链表的功能:
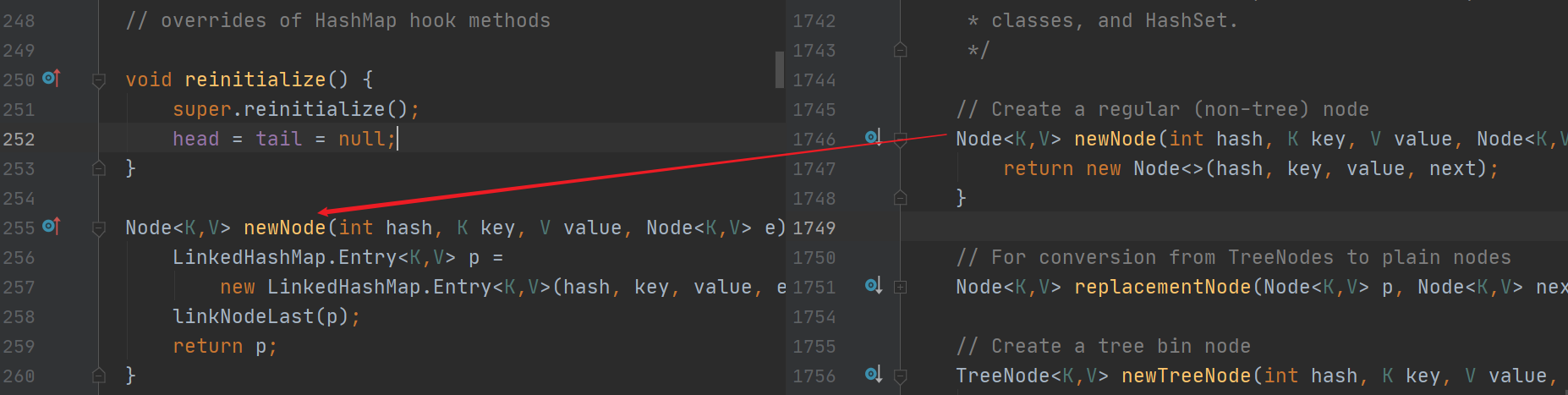
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
这个tail就是双向循环链表的末尾,由此可见p这个entity被插入到了链表的末尾。
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
在put过程中,如果遇到key已经存在的情况,会调用afterNodeAccess()方法,先替换value,然后把节点移到链表的末尾,这也就印证了第二点:如果在映射中重新插入键,则插入顺序不受影响(如果在调用 m.put(k, v) 前 m.containsKey(k) 返回了 true,则调用时会将键 k 重新插入到映射 m 中)。
然后调用了afterNodeInsertion()进行老旧节点的淘汰:
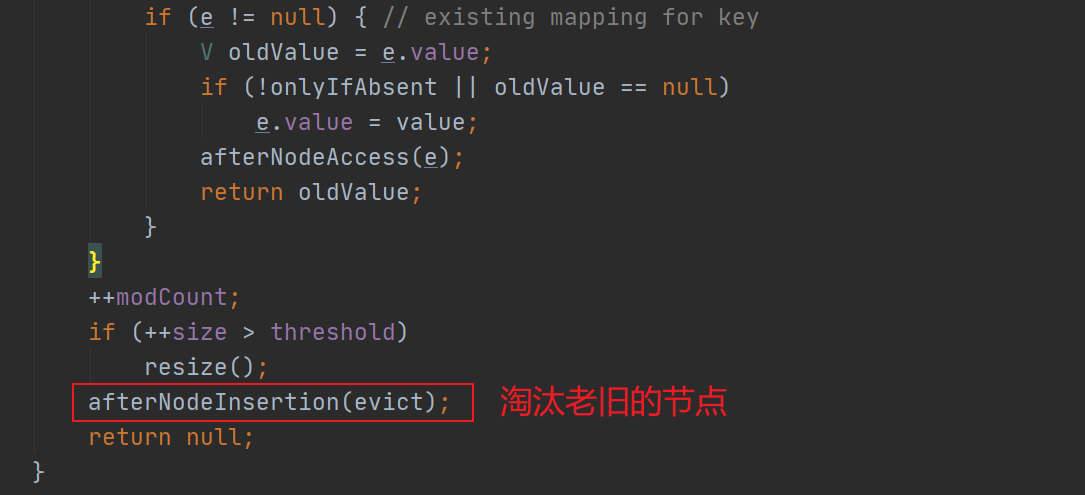
关于afterNodeInsertion()方法,可以看remove()方法介绍中的代码!
get()方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
这个getNode是HashMap中的方法,用Key快速查找对应的value,不存在则返回null;如果找到了,就判断当前链表排序方式是否是按照访问顺序排序,如果是的话,需要把节点放在链表的末尾。
// move node to last(把节点放在链表的末尾)
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
remove()方法
remove()其实也是HashMap中的方法,本质是调用了removeNode()方法,在这个removeNode()方法中我们可以看到,调用了afterNodeRemoval()方法:
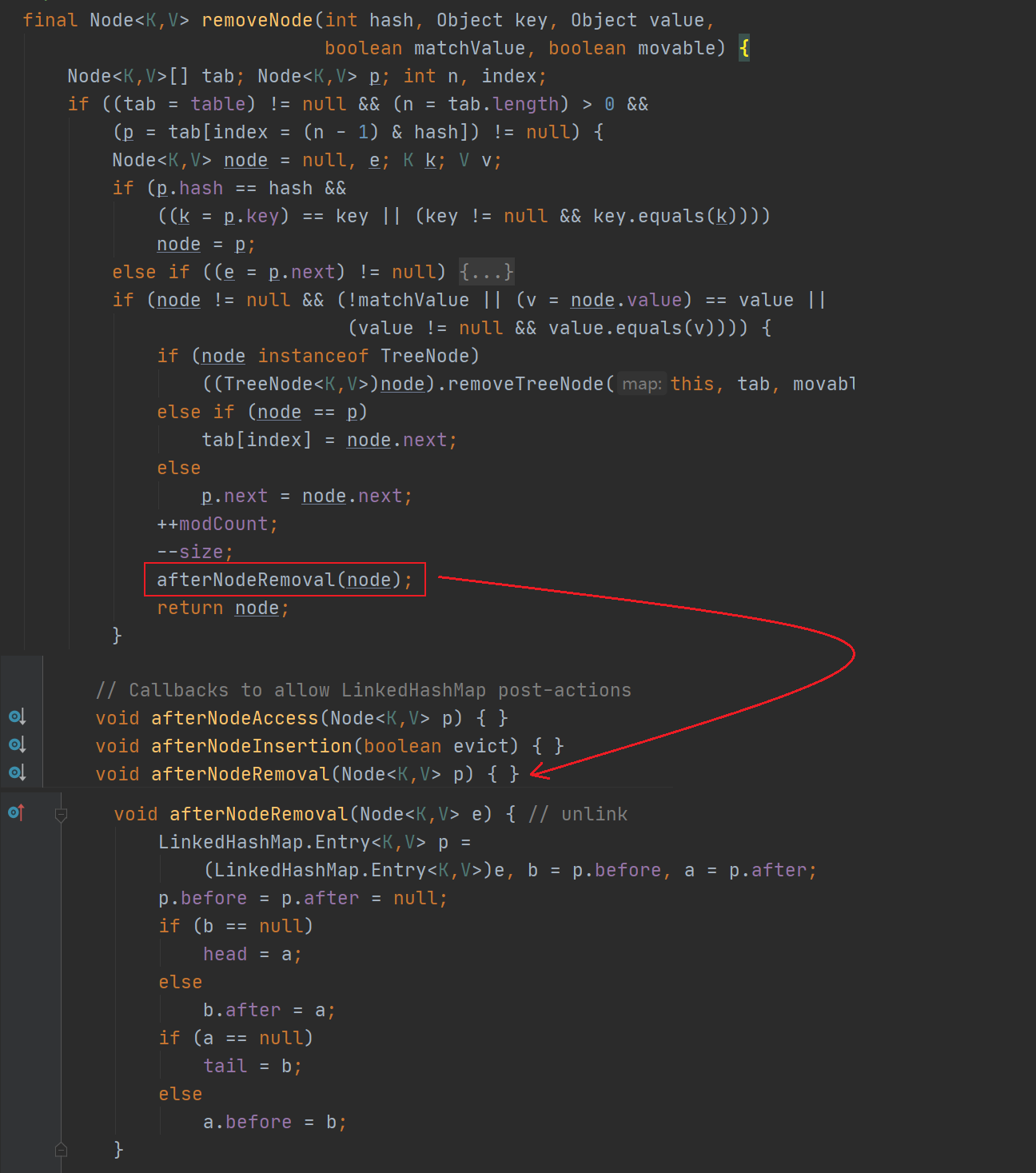
所以,LinkedHashMap的remove操作。首先把它从table中删除,即断开table或者其他对象通过next对其引用,然后也要把它从双向链表中删除,断开其他对应通过after和before对其引用。
既然已经看了afterNodeRemoval()方法,自然再看看afterNodeInsertion()方法与afterNodeAccess()方法,afterNodeInsertion()方法如下:
// possibly remove eldest(可能移除最老旧的节点)
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
在LinkedHashMap(本质还是HashMap进行put)调用put的时候,不但使用了LinkedHashMap重写的newNode()方法,最后还调用了afterNodeInsertion()方法。LinkedHashMap中被覆盖的afterNodeInsertion方法,用来回调移除最早放入Map的对象,可以看removeEldestEntry()方法的实现:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
其实这个就是实现LRU的关键了,通过重写该方法,我们可以通过自己设定的规则去判断是否达到了移除元素的时机,如果开启逐出模式(evict = true),并且头节点不为空,而且满足了移除元素的条件,那么就会把最老旧的节点进行移除。afterNodeAccess()方法在上面已经说过了,不再赘述。
Iterator
LinkedHashMap的哈希映射具有两个影响其性能的参数:初始容量和加载因子。它们的定义与 HashMap 极其相似。要注意,为初始容量选择非常高的值对此类的影响比对 HashMap 要小,因为此类的迭代时间不受容量的影响。这句话也就是说你的LinkedHashMap的初始容量跟迭代时间没有关系,为什么呢?我们需要其查看LinkedHashMap的迭代器:
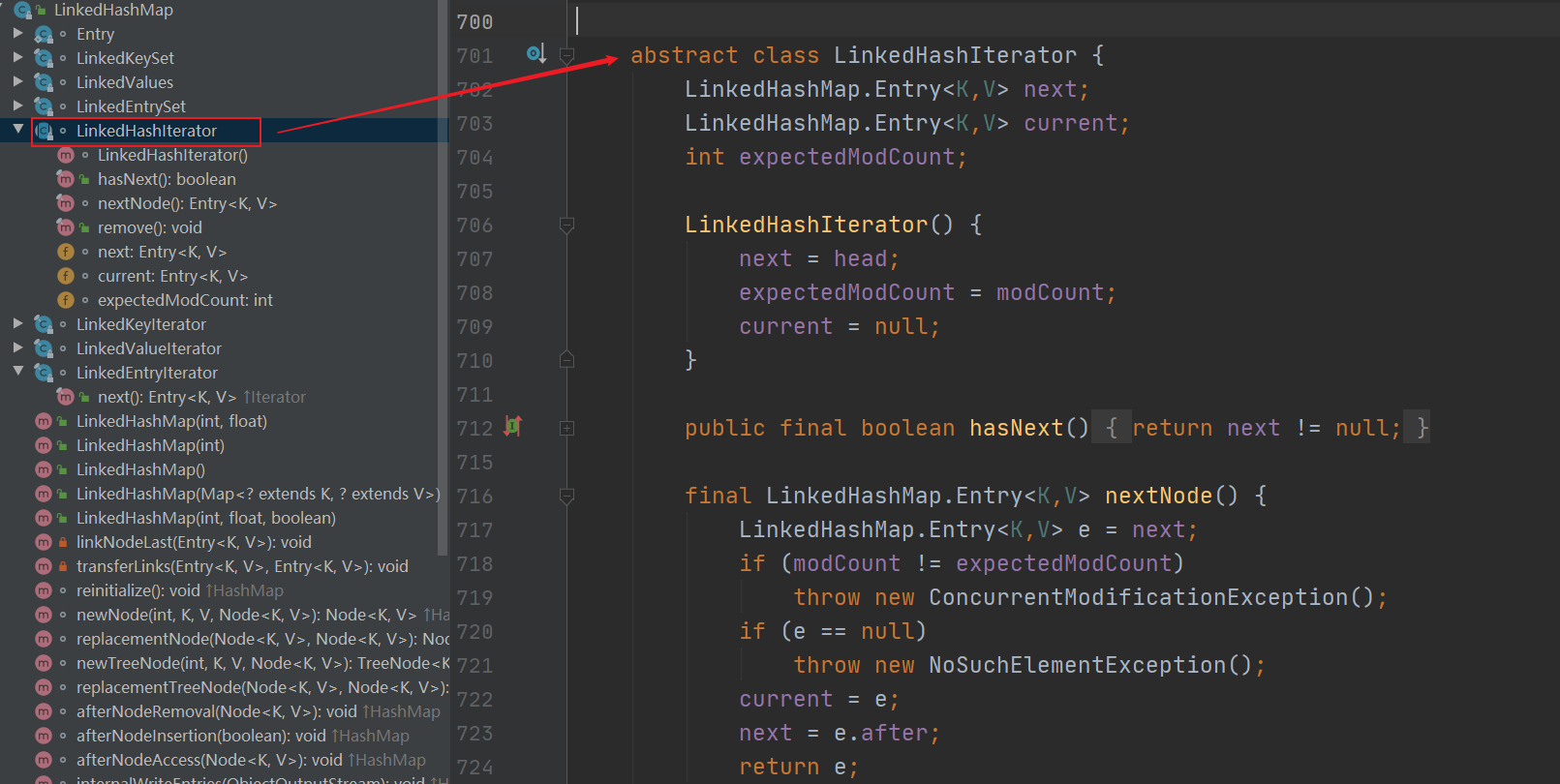
因为它遍历的是LinkedHashMap内部维护的双向链表,而不是散列表,但是双向链表的元素都来源于散列表的,所以无论初始化多大的LinkedHashMap,遍历的时候依旧是走双向链表的指针,逐个逐个next。
测试LinkedHashMap的顺序
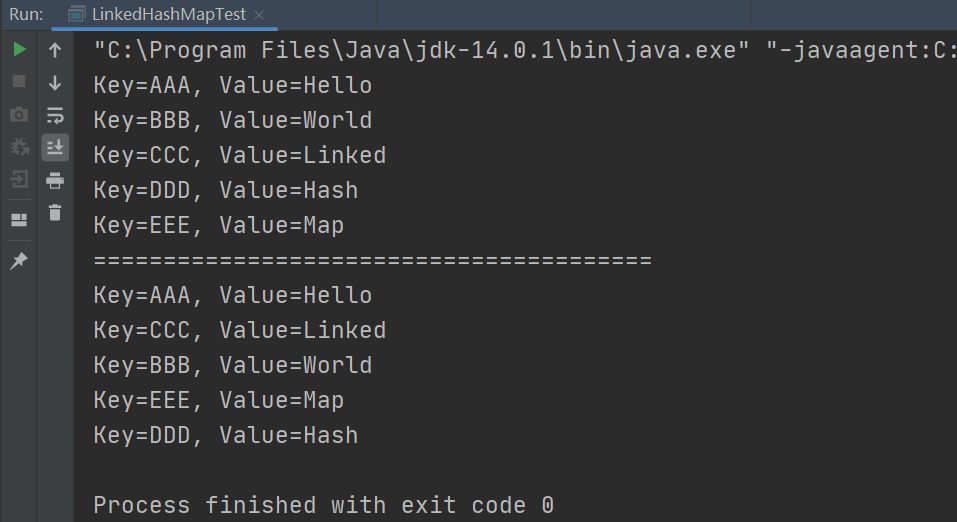
测试LinkedHashMap的顺序和HashMap的顺序:
public static void main(String[] args) {
// 默认是插入顺序
LinkedHashMap<String, String> map = new LinkedHashMap<>();
map.put("AAA", "Hello");
map.put("BBB", "World");
map.put("CCC", "Linked");
map.put("DDD", "Hash");
map.put("EEE", "Map");
Set<String> keySet = map.keySet();
for(String k: keySet){
System.out.println("Key=" + k + ", Value=" + map.get(k));
}
System.out.println("========================================");
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("AAA", "Hello");
hashMap.put("BBB", "World");
hashMap.put("CCC", "Linked");
hashMap.put("DDD", "Hash");
hashMap.put("EEE", "Map");
Set<String> hashKeySet = hashMap.keySet();
for(String k: hashKeySet){
System.out.println("Key=" + k + ", Value=" + map.get(k));
}
}
public static void main(String[] args) {
// 使用访问顺序
LinkedHashMap<String, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("AAA", "Hello");
map.put("BBB", "World");
map.put("CCC", "Linked");
map.put("DDD", "Hash");
map.put("EEE", "Map");
Set<String> keySet = map.keySet();
for(String k: keySet){
System.out.println("Key=" + k + ", Value=" + map.get(k));
}
}
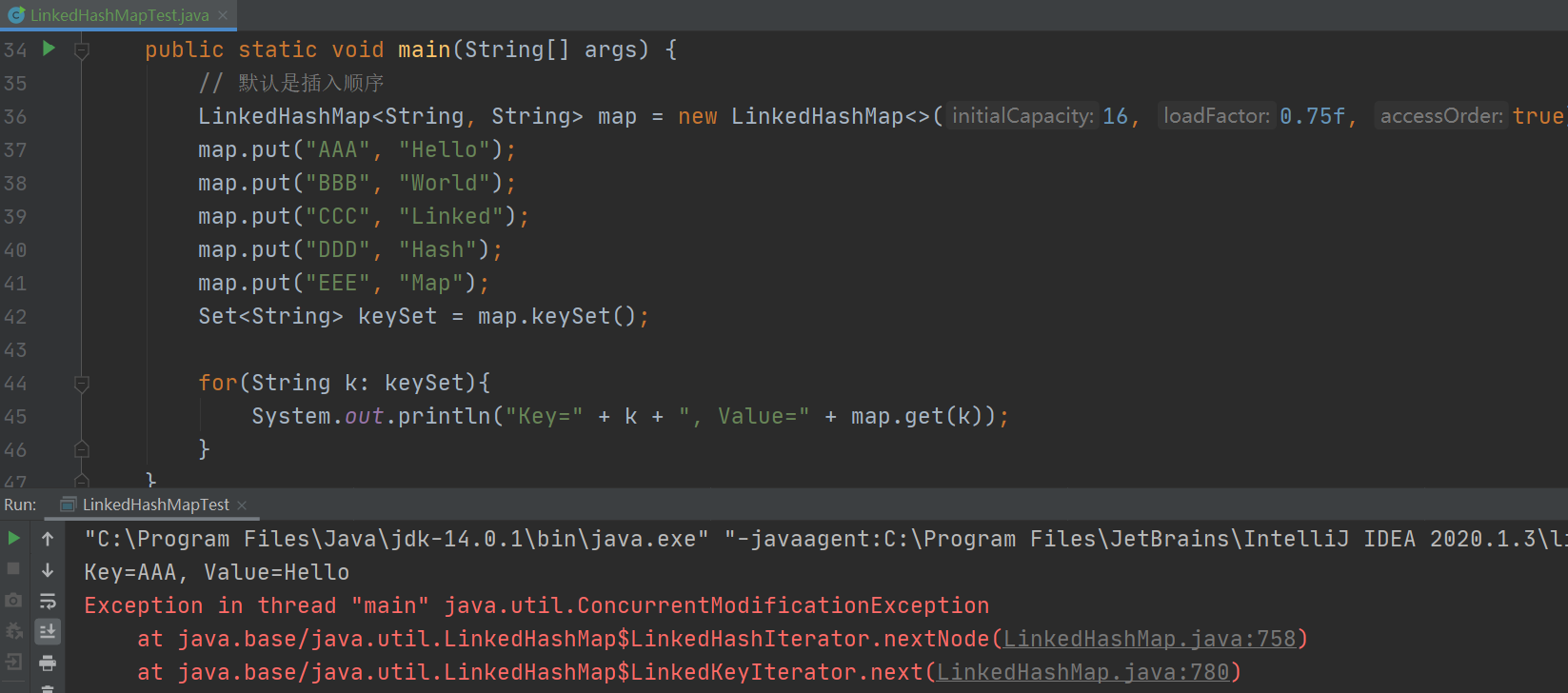
可以看到,当我们使用访问顺序构造LinkedHashMap的时候,在遍历时发生了并发修改异常,这是因为我们在访问第一个元素的时候,由于get()方法检测到accessOrder为true,所以把元素放在了链表的末尾,此时去遍历当然会发生并发修改异常!
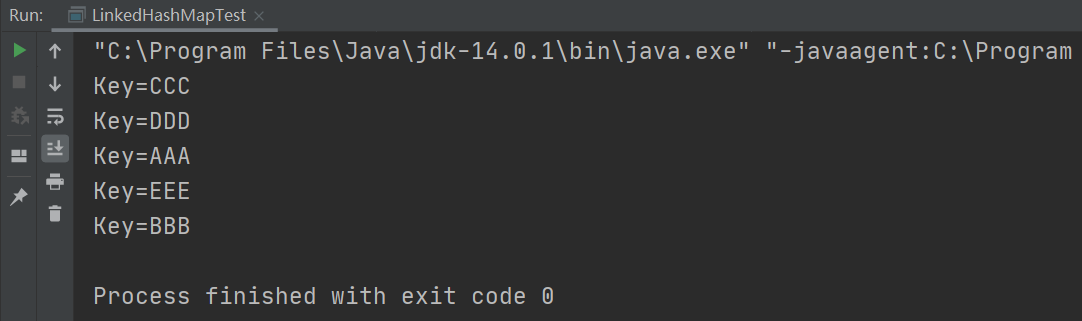
public static void main(String[] args) {
LinkedHashMap<String, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("AAA", "Hello");
map.put("BBB", "World");
map.put("CCC", "Linked");
map.put("DDD", "Hash");
map.put("EEE", "Map");
map.get("CCC");
map.get("DDD");
map.get("AAA");
map.get("EEE");
map.get("BBB");
Set<String> keySet = map.keySet();
for(String k: keySet){
System.out.println("Key=" + k);
}
}
实现自己的LRU
关于LinkedHashMap的知识大致就完了,那么如何基于链表实现 LRU 缓存淘汰算法呢?
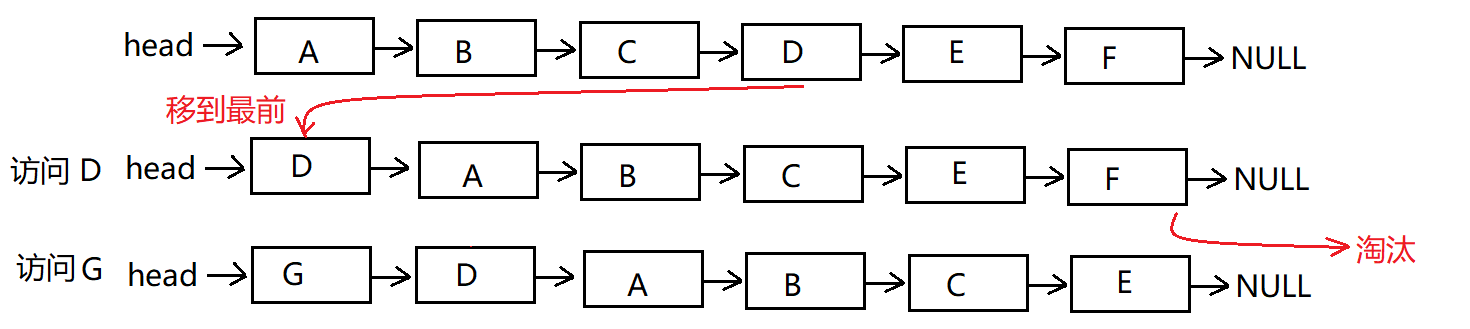
我的思路是这样的:我们维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
1、如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2、如果此数据没有在缓存链表中,又可以分为两种情况:
- 如果此时缓存未满,则将此结点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
这样我们就用链表实现了一个 LRU 缓存,是不是很简单?
这样做虽然可以,但是效率是有问题的,假设我的链表比较长的时候我需要去找我的缓存的对象在不在这个LRU缓存中,需要逐个遍历,时间复杂度为O(n)。有没有一种办法可以很快的判断在不在这个缓存中呢?
那就轮到LinkedHashMap登场了,因为底层是HashMap + 双向链表的数据结构,所以只要通过HashMap来查找就变成了O(logn),甚至O(1)。下面就通过LinkedHashMap实现一个自己的LRU Cache吧:
public class LruCache<K, V> {
// 默认负载因子
private static final float DEFAULT_LOAD_FACTORY = 0.75F;
// 最大缓存数量
private static final int MAX_CACHE_SIZE = 10;
// LinkedHashMap
private final MyLinkedHashMap map;
// 默认size为16
public LruCache() {
map = new MyLinkedHashMap(16, DEFAULT_LOAD_FACTORY, true);
}
public LruCache(int initialCapacity) {
map = new MyLinkedHashMap(initialCapacity, DEFAULT_LOAD_FACTORY, true);
}
public void put(K k,V v){
map.put(k, v);
}
public V get(K k){
return map.get(k);
}
public int size(){
return map.size();
}
public void remove(K k){
map.remove(k);
}
public Set<K> keySet(){
return map.keySet();
}
private class MyLinkedHashMap extends LinkedHashMap<K, V> {
public MyLinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return MAX_CACHE_SIZE < size();
}
}
}
// 测试
public class LruCacheTest {
public static void main(String[] args) {
LruCache<Integer, String> lruCache = new LruCache<>(5);
lruCache.put(1, "AAA");
lruCache.put(2, "BBB");
lruCache.put(3, "CCC");
lruCache.put(4, "DDD");
lruCache.put(5, "EEE");
lruCache.put(6, "FFF");
lruCache.put(7, "GGG");
lruCache.put(8, "HHH");
lruCache.put(9, "III");
lruCache.get(1);
lruCache.get(5);
lruCache.put(10, "JJJ");
lruCache.put(11, "KKK");
lruCache.put(12, "LLL");
lruCache.put(4, "MMM");
System.out.println("lruCache.size() = " + lruCache.size());
Set<Integer> keySet = lruCache.keySet();
for(Integer k: keySet) System.out.println("Key = " + k);
}
}
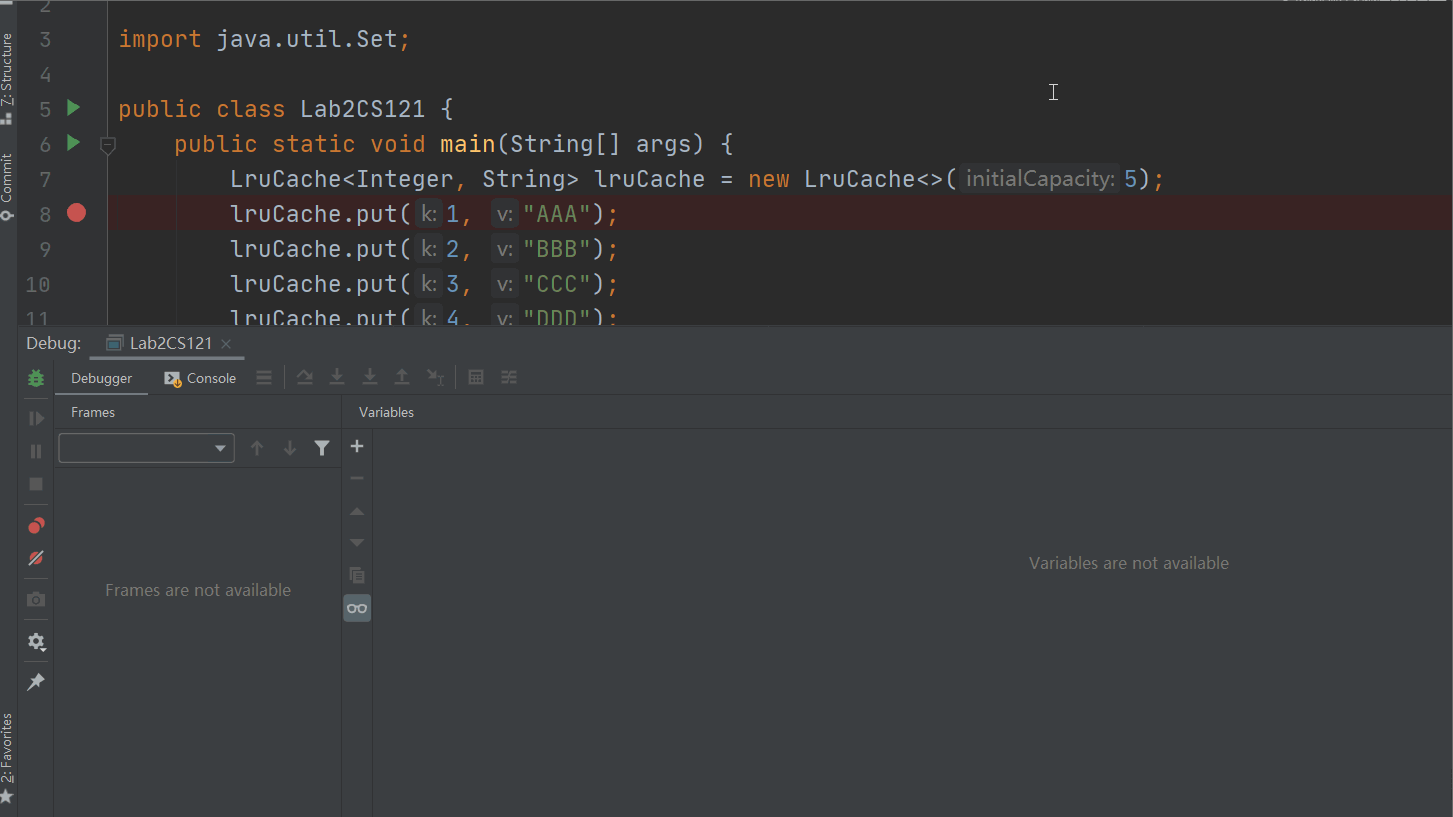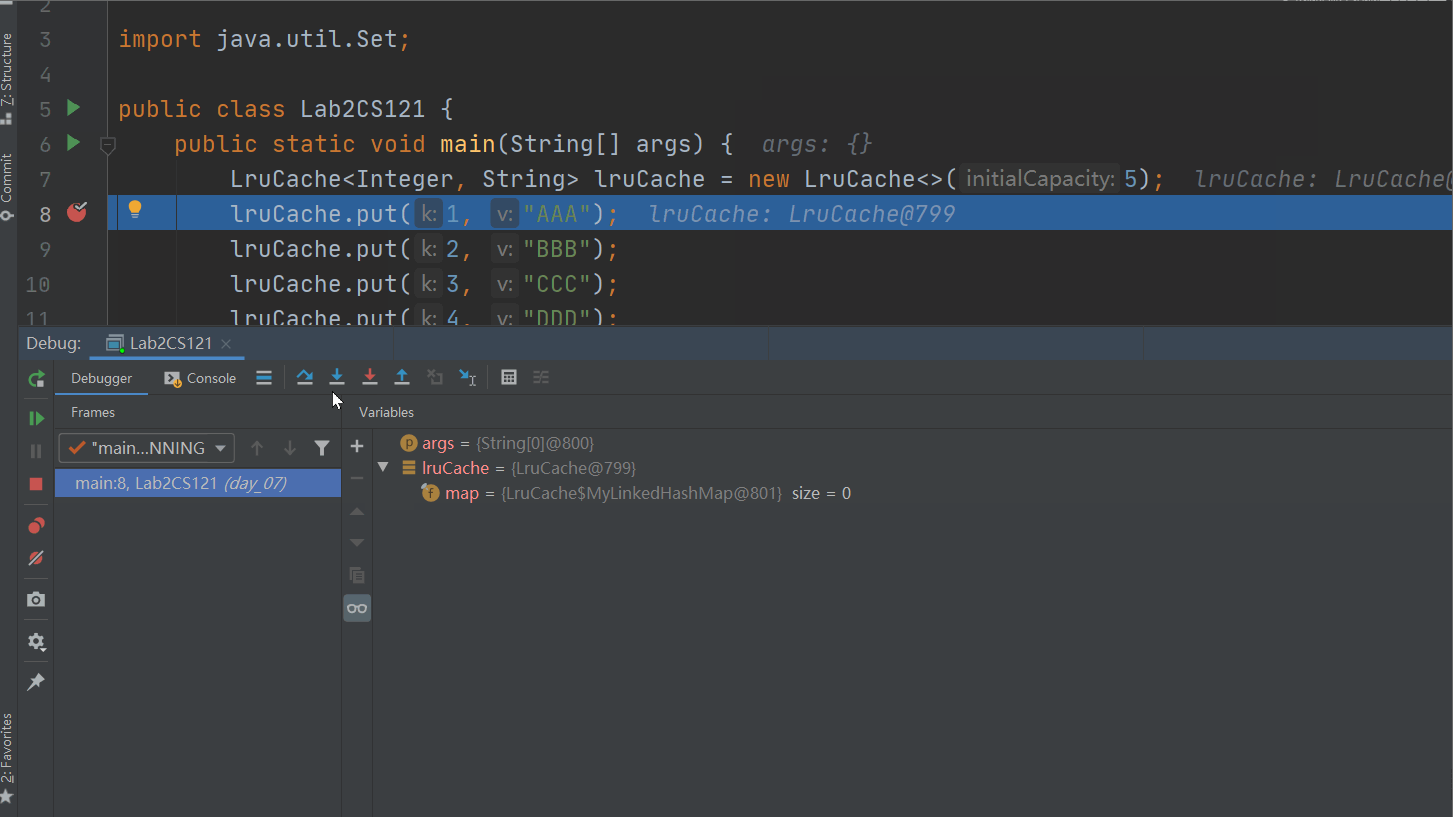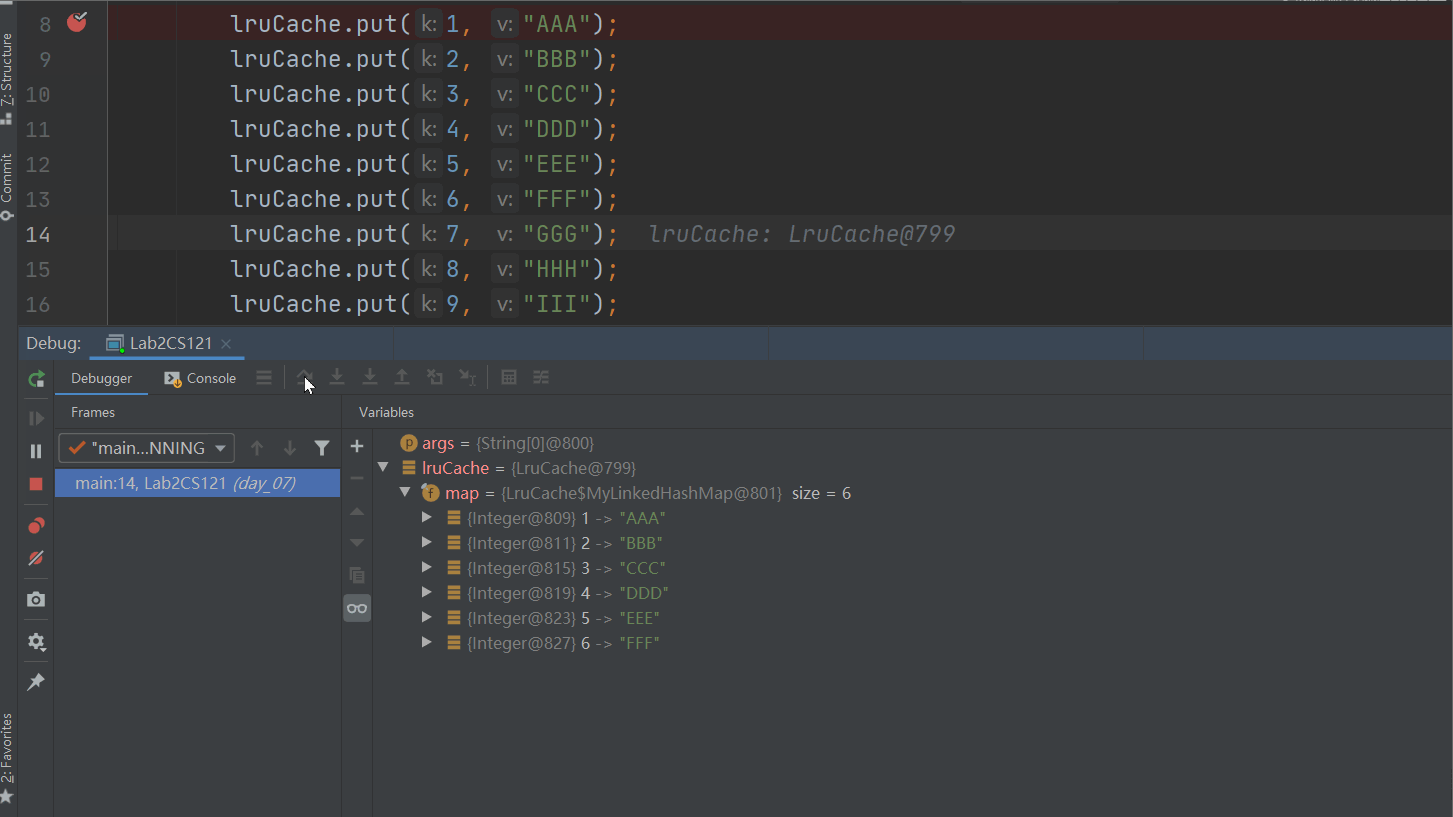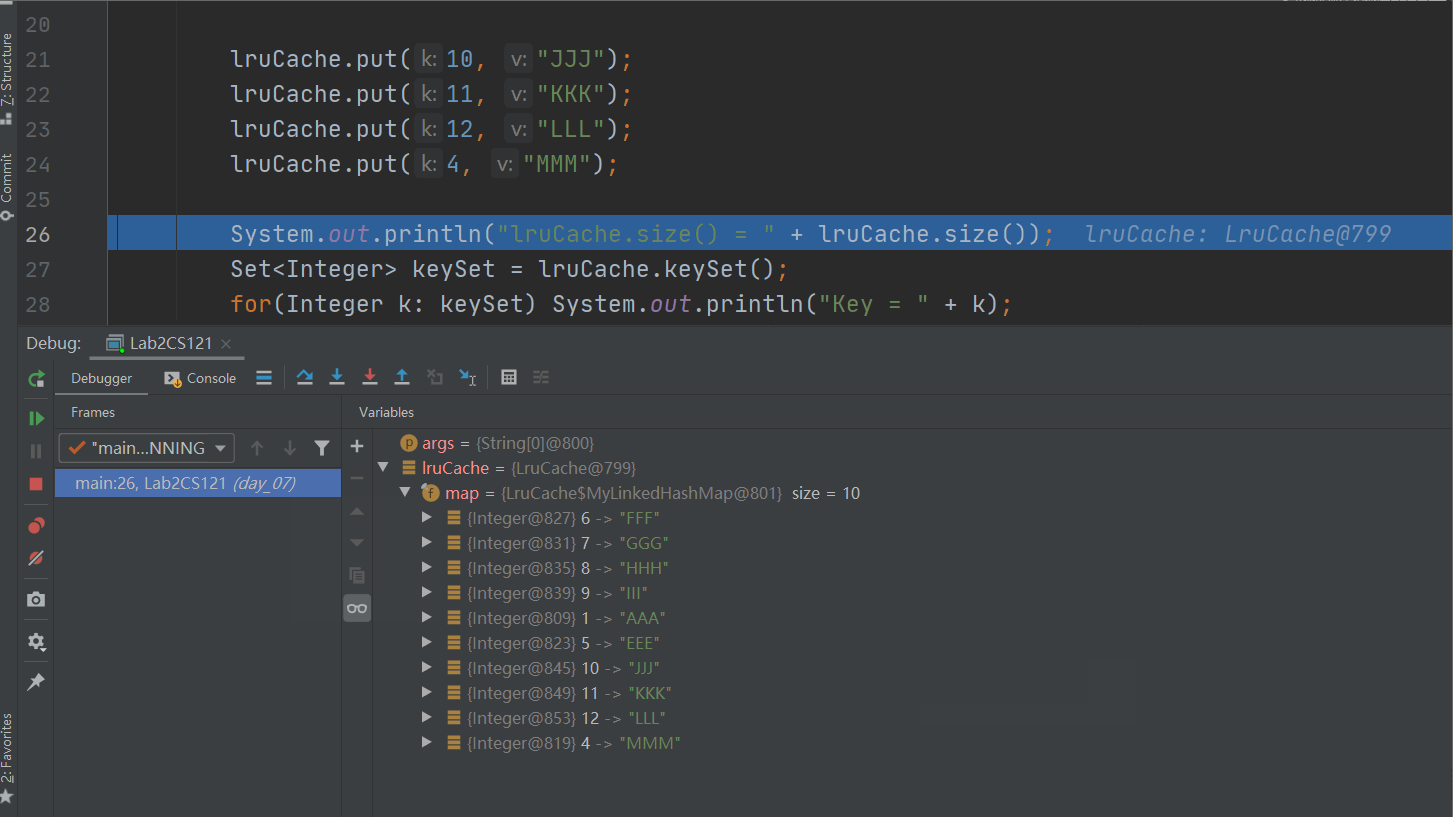
通过调试我们确实不难发现,整个LRUCache的淘汰过程。