多层感知机(MLP)
之前主要学习了常见的机器学习算法,现在开始进入另一个环节:深度学习。首先就是多层感知机模型,Multi-Layer Perception(简称MLP)是标准的全连接神经网络模型,它由节点层组成,其中每个节点连接到上一层的所有输出,每个节点的输出连接到下一层节点的所有输入。本节会从一个简单的分类任务开始,逐步探讨多层感知机的工作原理。
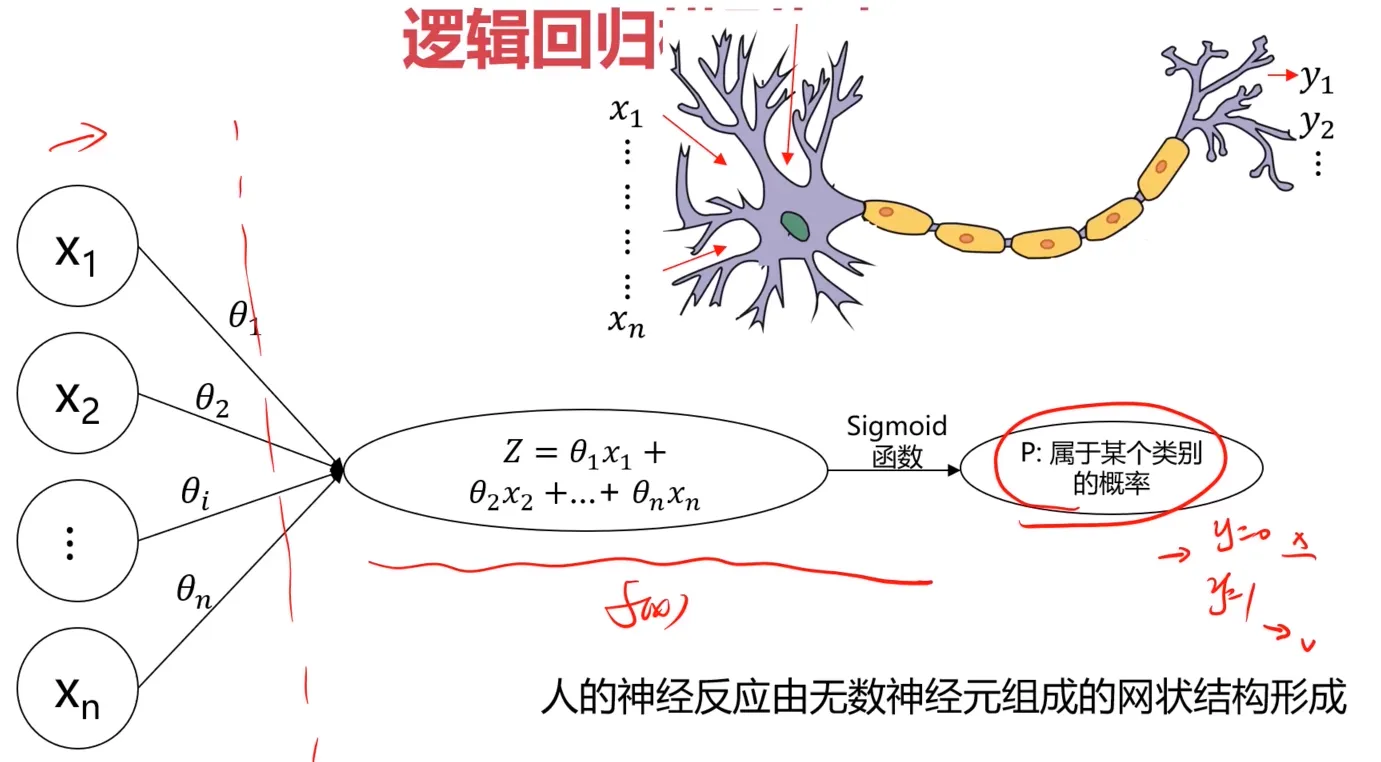
MLP基本概念
尝试建立一个模型,其结构模仿人的思考机制:
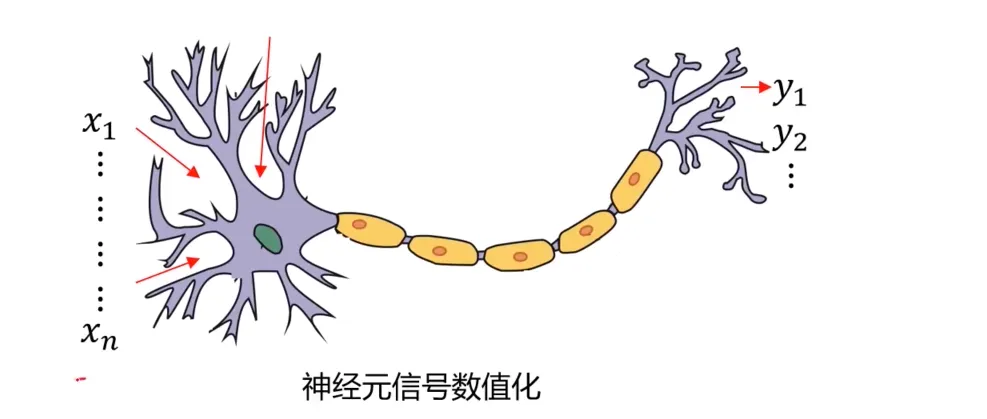 需要注意的是,这里探讨的是早期人工神经网络的实现方式,由sigmoid函数来模仿生物学上的神经元是否激发,但是现代神经网络几乎不使用sigmoid函数了,它已经过时了。ReLU(线性整流函数)是经过验证的更好的选择,但是这里还是从sigmoid函数这种方式来探讨。
需要注意的是,这里探讨的是早期人工神经网络的实现方式,由sigmoid函数来模仿生物学上的神经元是否激发,但是现代神经网络几乎不使用sigmoid函数了,它已经过时了。ReLU(线性整流函数)是经过验证的更好的选择,但是这里还是从sigmoid函数这种方式来探讨。
MLP实现非线性分类
先来看一个简单的分类任务,对于这样的一个分类任务,很显然如果使用逻辑回归来完成,确实能做到,但是肯定需要增加高次项数据,以生成复杂的决策边界,可以回顾
《分类问题与逻辑回归》
中的内容:
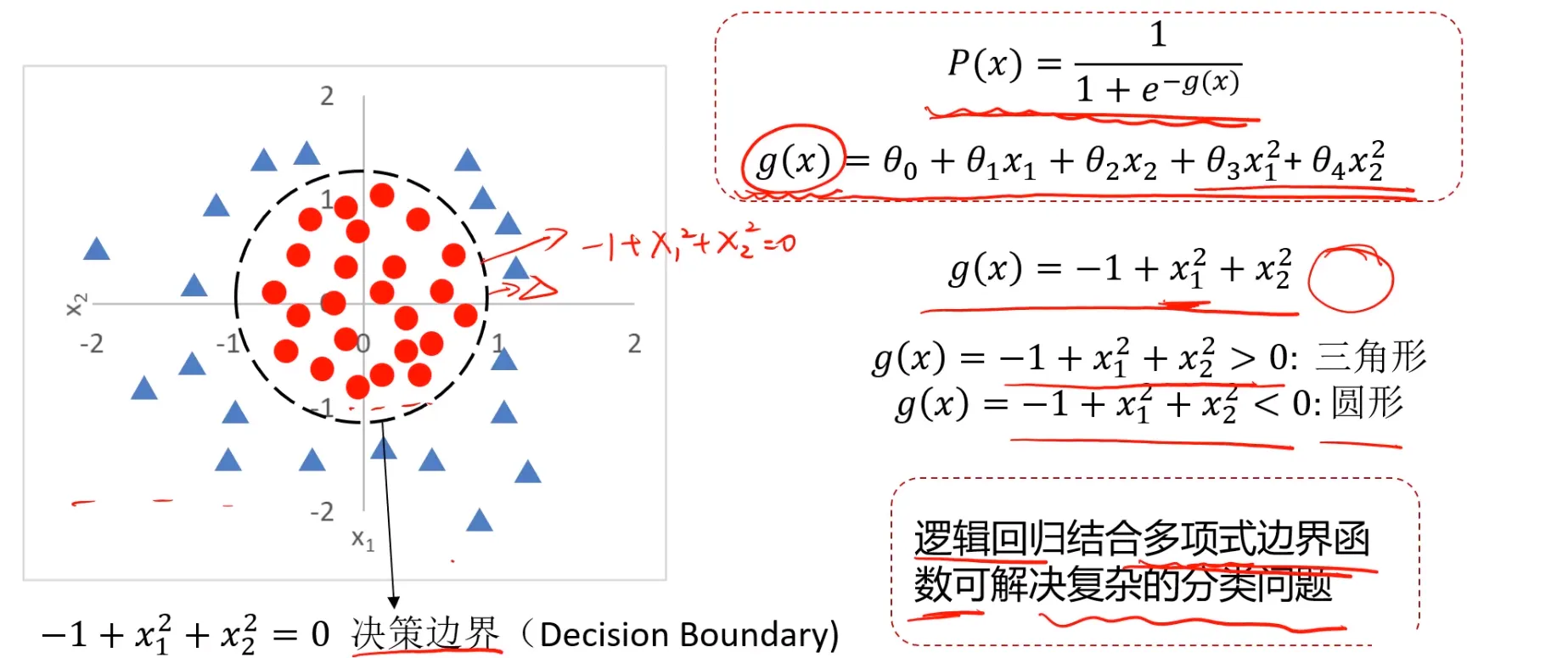
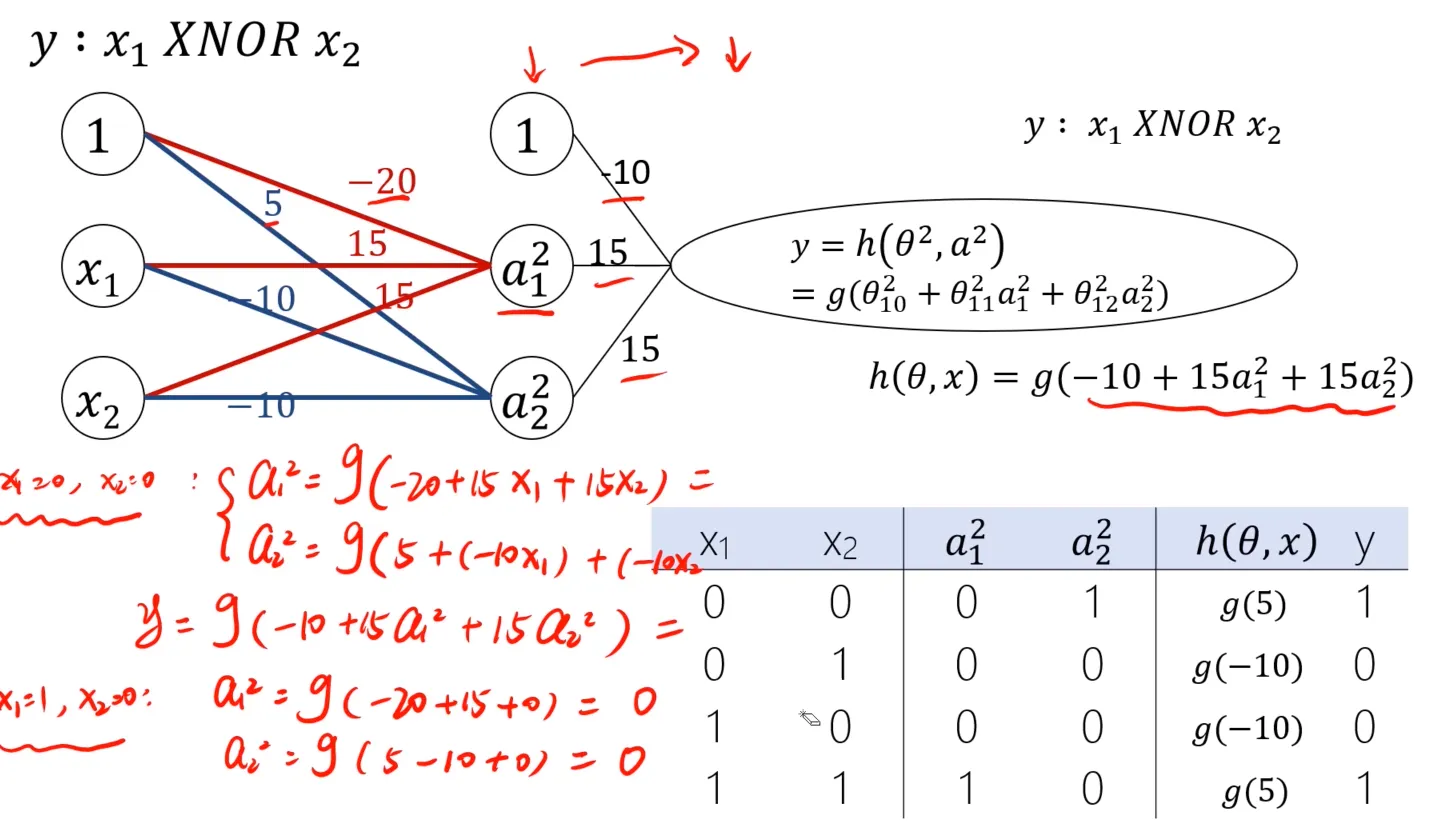
现在呢,数据整体来看,左下角和右上角都是圆圈(Y = 0),左上角和右下角都是叉(Y = 1)。首先尝试简化一下模型,即y为$x_1$和$x_2$的同或门:
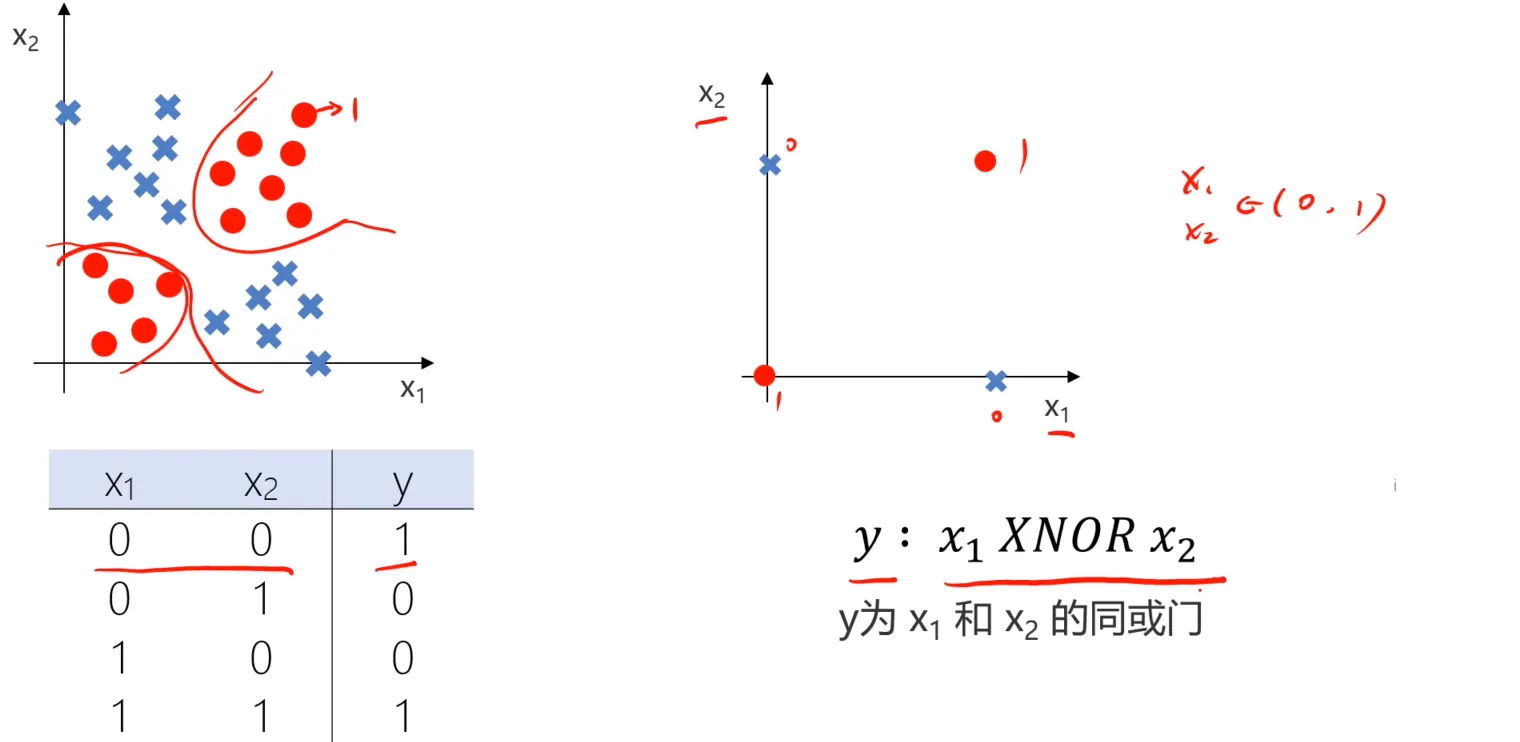
除了同或门,可以再看几个其他的例子:
y为$x_1$和$x_2$的与门:
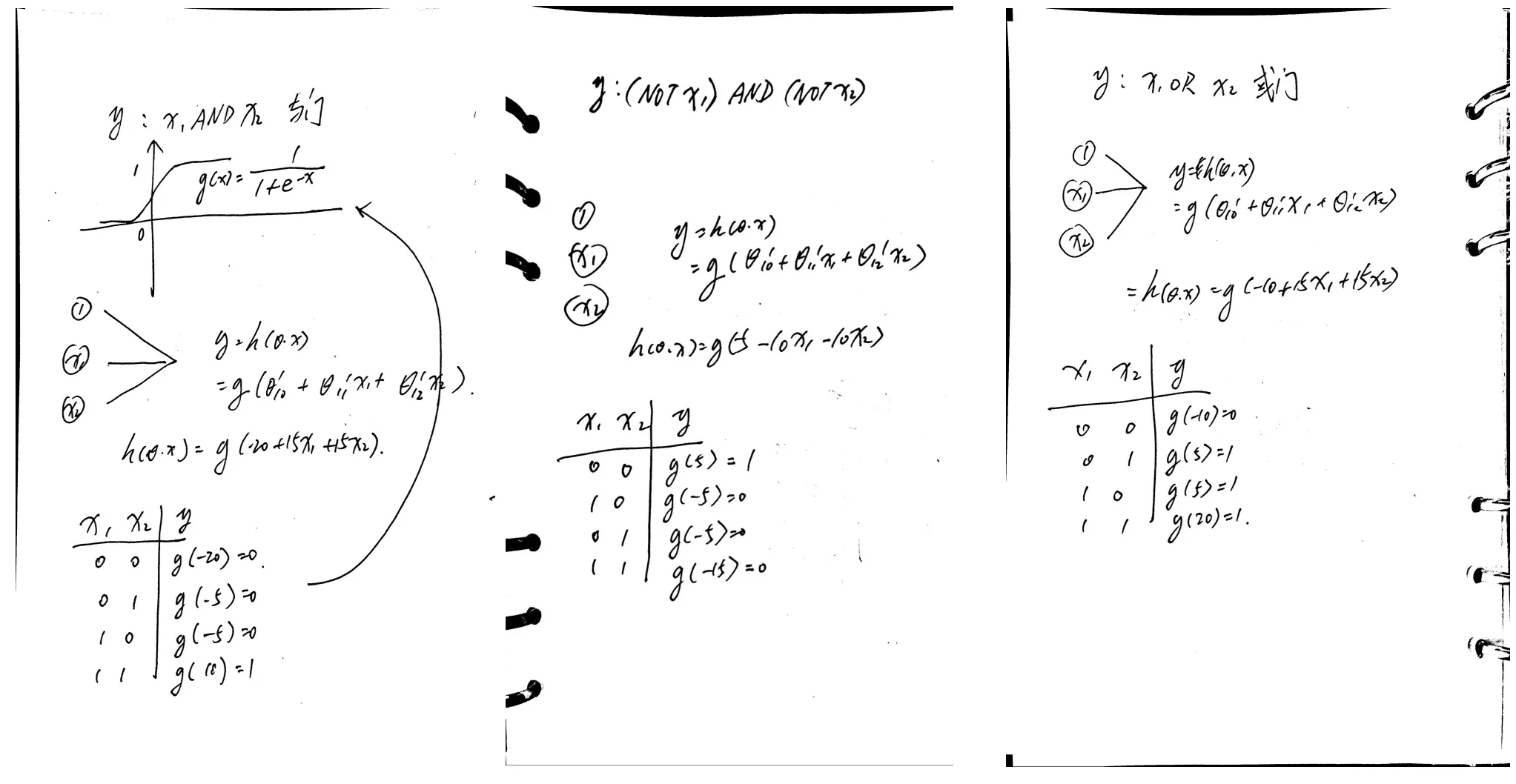
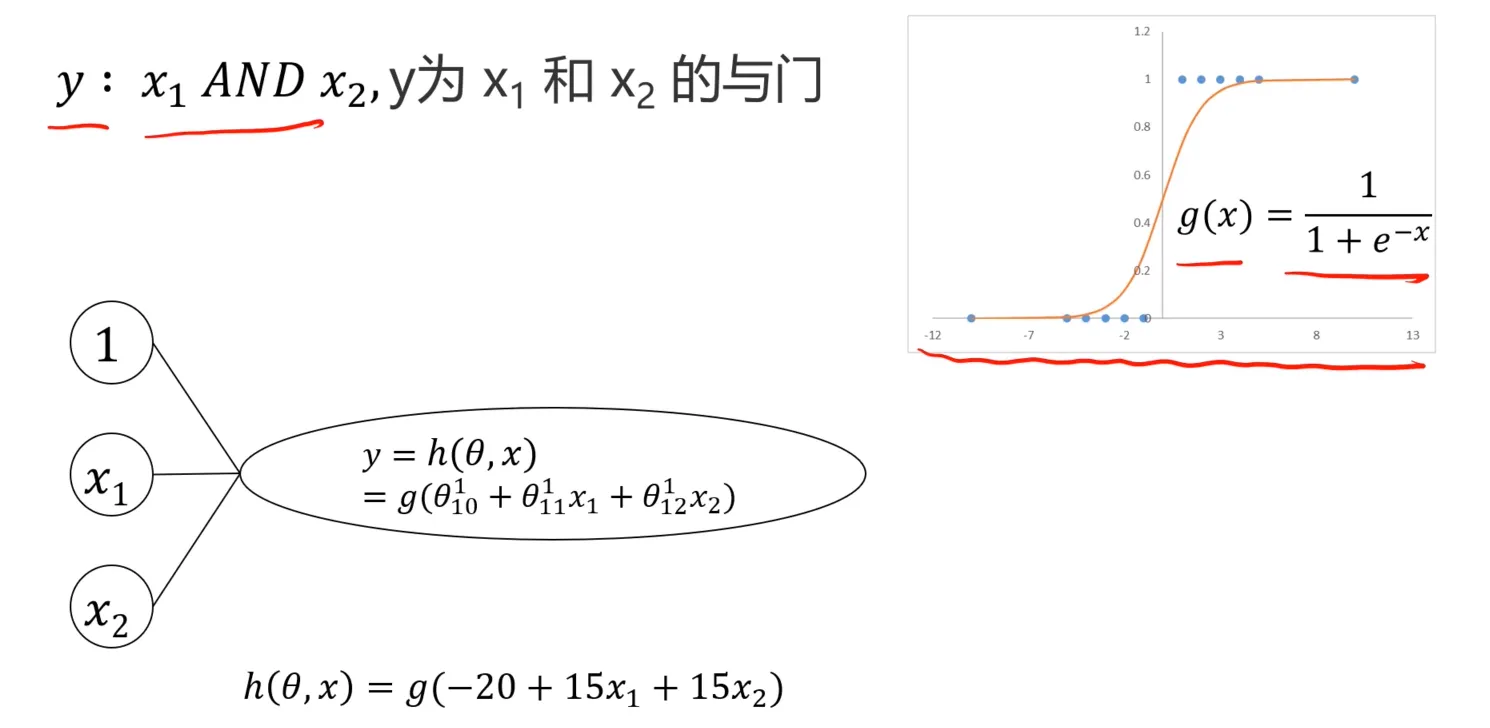 假设我们已经提供了一个边界函数,$h(\theta,x)=g(-20+15x_1+15x_2)$, 可以尝试计算一下,另外呢,下图中也提供了$(NOT x_1) AND (NOT x_2)$、$x_1 OR x_2$:
假设我们已经提供了一个边界函数,$h(\theta,x)=g(-20+15x_1+15x_2)$, 可以尝试计算一下,另外呢,下图中也提供了$(NOT x_1) AND (NOT x_2)$、$x_1 OR x_2$:
把这三个模型组合一下,便可以得到一个复杂模型来处理上面的非线性分类的简化问题:
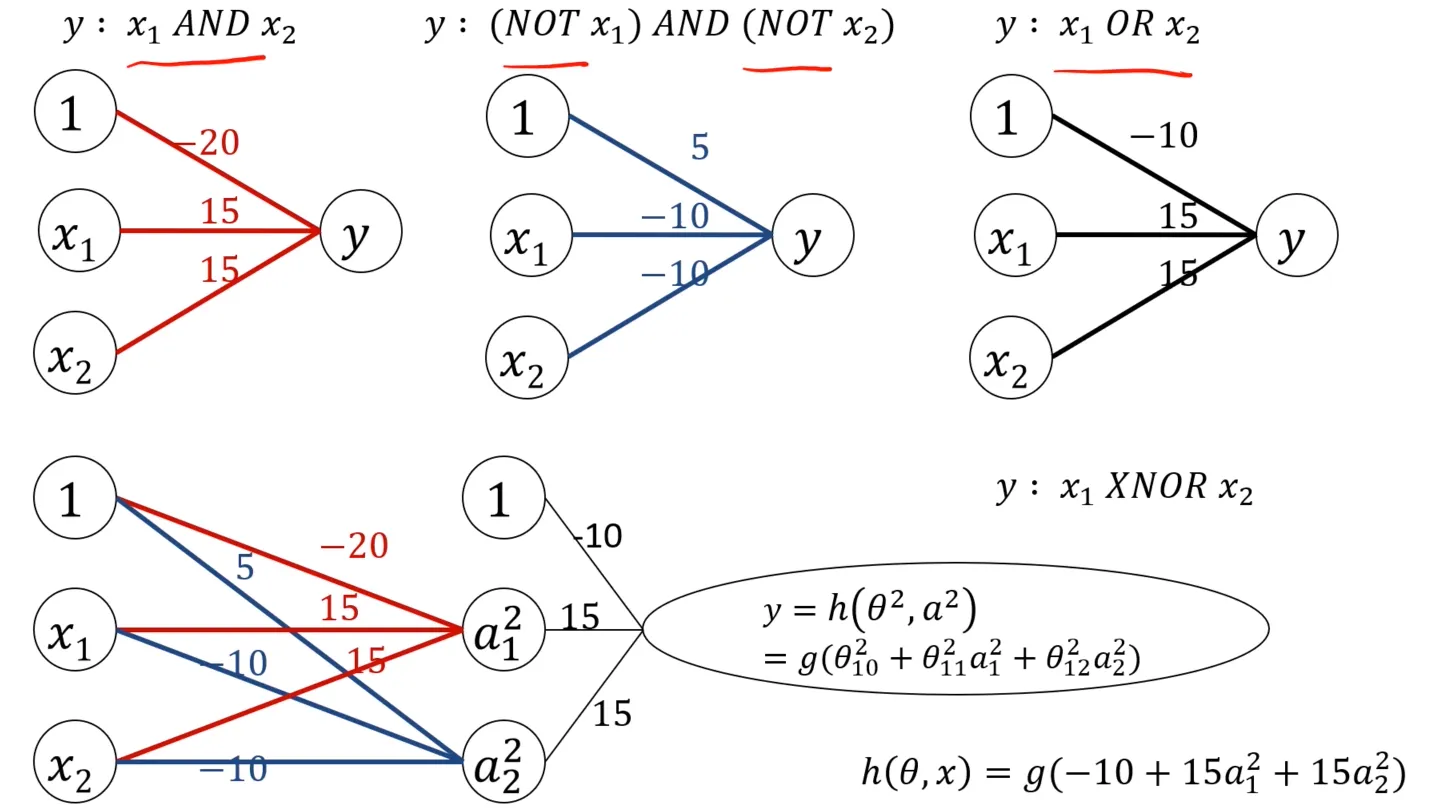 实际计算一下,跟简化模型是符合的:
实际计算一下,跟简化模型是符合的:
那么思考一下,MLP如何实现多分类呢?其实很简单,直接在输出结果上多增加一层,表示对应类别的概率:
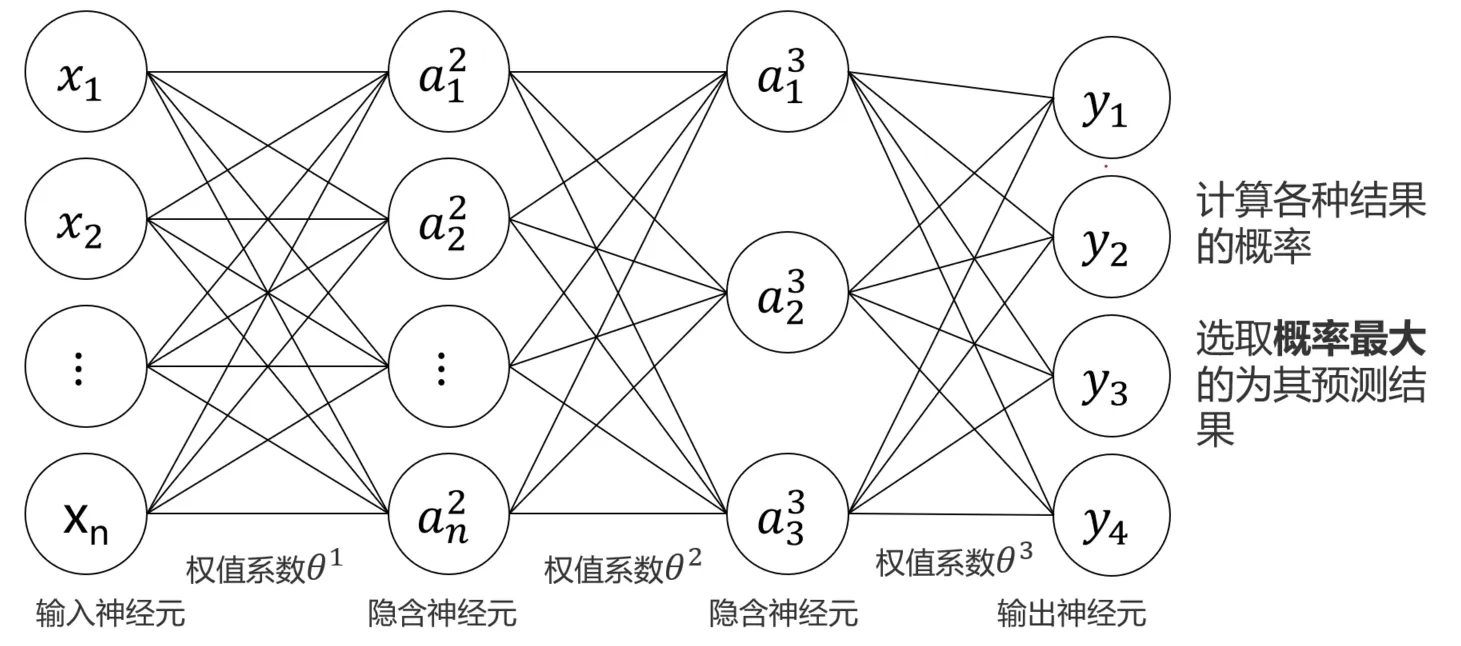
思考问题:在建立MLP模型实现图像多分类任务中其流程应该是怎么样的?
1、加载图片并将其转换为数字矩阵
2、对输入数据进行维度转换与归一化处理
3、建立MLP模型结构
4、MLP模型训练参数配置
5、模型训练与预测
6、对输出结果进行格式转化
MLP实战准备
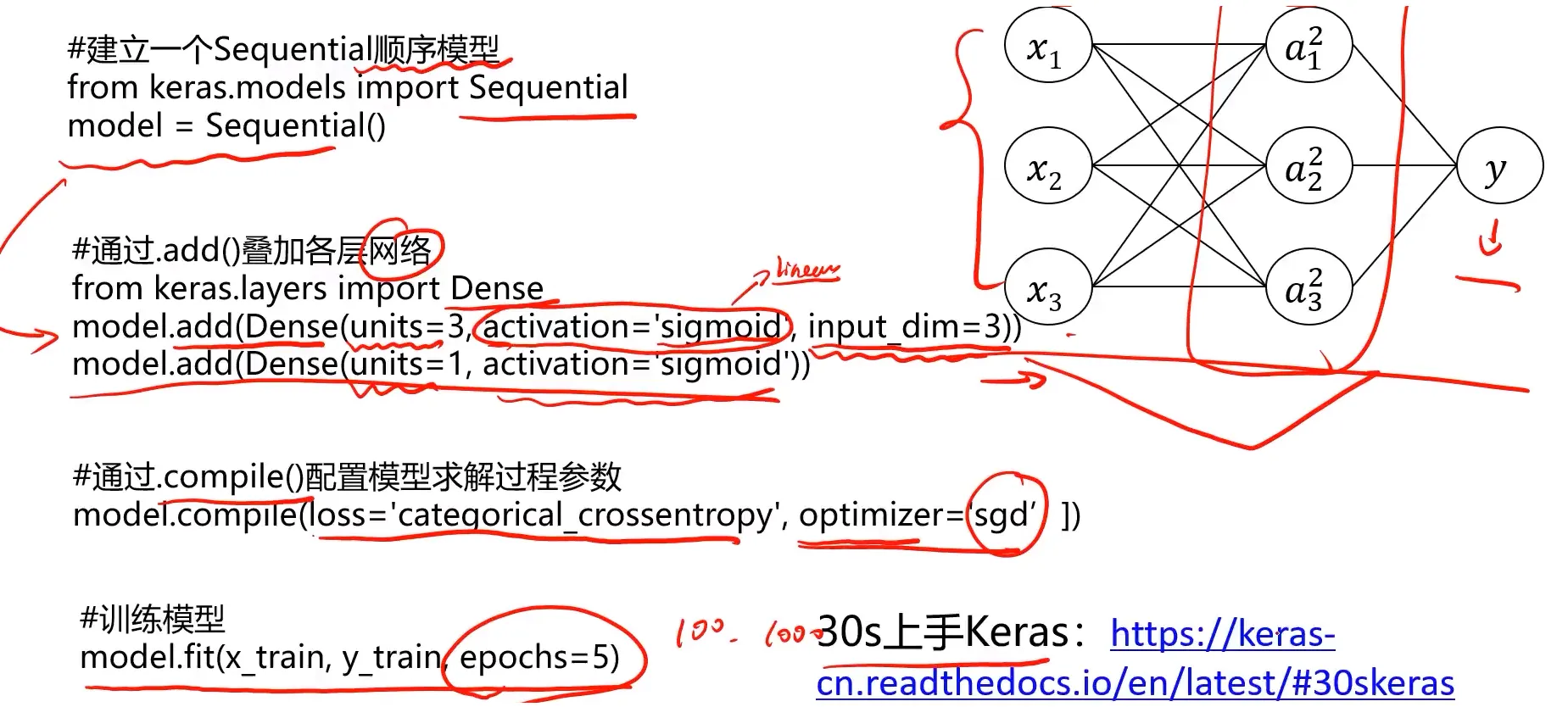
首先准备阶段,这里使用的是Keras框架,Keras 是一个用 Python 编写的用于神经网络开发的应用接口调用开接口可以实现神经网络、卷积神经网络、循环神经网络等常用深度学习算法的开发。
其实Keras通常将TensorFlow,或者Theano作为后端,Keras框架提供上层API,使用起来更加便捷,如果你想快速验证模型,那么Keras框架将是一个不错的选择。Keras集成了深度学习中各类成熟的算法,容易安装和使用,样例丰富教程和文档也非常详细。这里给出文档地址: https://keras.io ,中本版本: https://keras.io/zh
Tensorflow是一个采用数据流图用于数值计算的开源软件库,可自动计算模型相关的微分导数: 非常舌合用于神经网络模型的求解。
Keras可以看作为Tensorflow封装好的一个接口(Keras作为前端,TensorFlow作为后端)。Keras为用户提供了一个易于交互的外壳方便进行深度学习的快速开发。
Keras建立MLP模型:
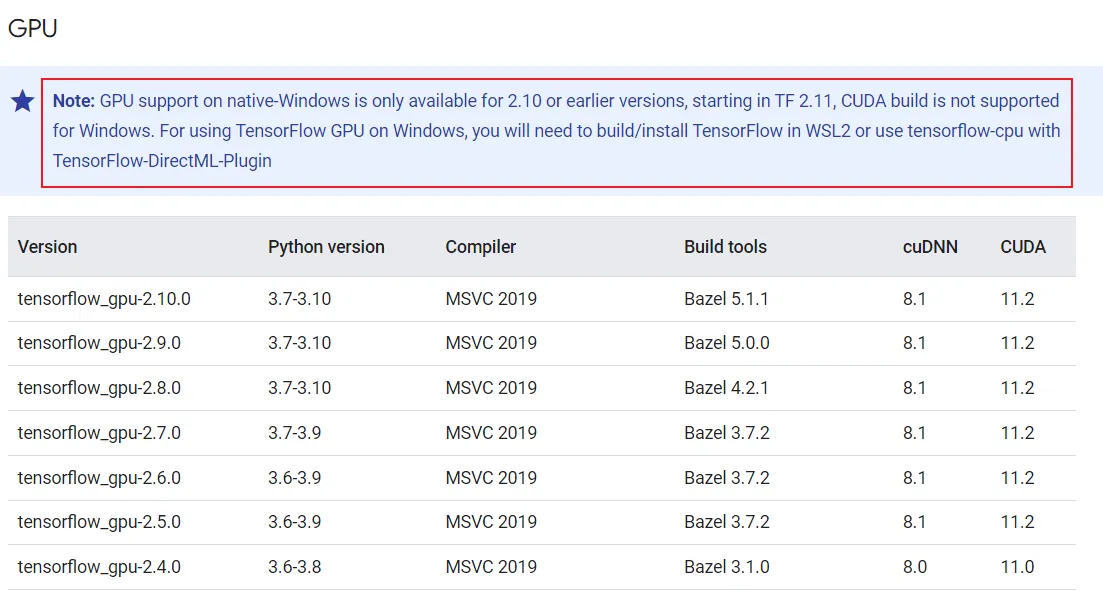
keras环境安装与GPU加速
其实如果是使用conda安装tensorflow的话,完全没有这么复杂,直接使用conda安装tensorflow-gpu即可,剩下的依赖包conda直接会默认安装好。
需要注意的是:在Windows上,TensorFlow-GPU最多支持到CUDA 11.2,可以参考这个链接: https://tensorflow.google.cn/install/source_windows ,所以我们如果在不借助WSL的情况下在Windows上运行TensorFlow-GPU,版本需要把CUDA驱动版本控制在11.2及以下,Python版本根据要安装的TensorFlow版本确定即可,目前我是使用的版本是tensorflow-gpu:2.6.0
安装完成后确认一下cuda版本:


导出的conda环境如下 my_environment.yml(其中就包括了tensorflow-gpu、keras、sklearn常用包):
name: tf
channels:
- defaults
dependencies:
- _tflow_select=2.1.0=gpu
- abseil-cpp=20210324.2=hd77b12b_0
- absl-py=1.4.0=py38haa95532_0
- aiohttp=3.8.5=py38h2bbff1b_0
- aiosignal=1.2.0=pyhd3eb1b0_0
- anyio=3.5.0=py38haa95532_0
- appdirs=1.4.4=pyhd3eb1b0_0
- argon2-cffi=21.3.0=pyhd3eb1b0_0
- argon2-cffi-bindings=21.2.0=py38h2bbff1b_0
- astor=0.8.1=py38haa95532_0
- asttokens=2.0.5=pyhd3eb1b0_0
- astunparse=1.6.3=py_0
- async-timeout=4.0.2=py38haa95532_0
- attrs=22.1.0=py38haa95532_0
- backcall=0.2.0=pyhd3eb1b0_0
- beautifulsoup4=4.12.2=py38haa95532_0
- blas=1.0=mkl
- bleach=4.1.0=pyhd3eb1b0_0
- blinker=1.4=py38haa95532_0
- bottleneck=1.3.5=py38h080aedc_0
- brotlipy=0.7.0=py38h2bbff1b_1003
- c-ares=1.19.1=h2bbff1b_0
- ca-certificates=2023.08.22=haa95532_0
- cachetools=4.2.2=pyhd3eb1b0_0
- certifi=2023.7.22=py38haa95532_0
- cffi=1.15.1=py38h2bbff1b_3
- charset-normalizer=2.0.4=pyhd3eb1b0_0
- click=8.0.4=py38haa95532_0
- colorama=0.4.6=py38haa95532_0
- comm=0.1.2=py38haa95532_0
- cryptography=41.0.3=py38h3438e0d_0
- cudatoolkit=11.3.1=h59b6b97_2
- cudnn=8.2.1=cuda11.3_0
- debugpy=1.6.7=py38hd77b12b_0
- decorator=5.1.1=pyhd3eb1b0_0
- defusedxml=0.7.1=pyhd3eb1b0_0
- entrypoints=0.4=py38haa95532_0
- executing=0.8.3=pyhd3eb1b0_0
- flatbuffers=2.0.0=h6c2663c_0
- frozenlist=1.3.3=py38h2bbff1b_0
- gast=0.4.0=pyhd3eb1b0_0
- giflib=5.2.1=h8cc25b3_3
- google-auth=2.22.0=py38haa95532_0
- google-auth-oauthlib=0.4.1=py_2
- google-pasta=0.2.0=pyhd3eb1b0_0
- grpcio=1.42.0=py38hc60d5dd_0
- h5py=3.7.0=py38h3de5c98_0
- hdf5=1.10.6=h1756f20_1
- icc_rt=2022.1.0=h6049295_2
- icu=68.1=h6c2663c_0
- idna=3.4=py38haa95532_0
- importlib-metadata=6.0.0=py38haa95532_0
- importlib_resources=5.2.0=pyhd3eb1b0_1
- intel-openmp=2021.4.0=haa95532_3556
- ipykernel=6.25.0=py38h9909e9c_0
- ipython=8.12.2=py38haa95532_0
- ipython_genutils=0.2.0=pyhd3eb1b0_1
- jedi=0.18.1=py38haa95532_1
- jinja2=3.1.2=py38haa95532_0
- joblib=1.2.0=py38haa95532_0
- jpeg=9e=h2bbff1b_1
- jsonschema=4.17.3=py38haa95532_0
- jupyter_client=7.4.9=py38haa95532_0
- jupyter_core=5.3.0=py38haa95532_0
- jupyter_server=1.23.4=py38haa95532_0
- jupyterlab_pygments=0.1.2=py_0
- keras=2.6.0=pyhd3eb1b0_0
- keras-applications=1.0.8=py_1
- keras-preprocessing=1.1.2=pyhd3eb1b0_0
- libcurl=8.2.1=h86230a5_0
- libiconv=1.16=h2bbff1b_2
- libpng=1.6.39=h8cc25b3_0
- libprotobuf=3.17.2=h23ce68f_1
- libsodium=1.0.18=h62dcd97_0
- libssh2=1.10.0=hcd4344a_2
- libxml2=2.10.4=h0ad7f3c_1
- libxslt=1.1.37=h2bbff1b_1
- lxml=4.9.2=py38h2bbff1b_0
- markdown=3.4.1=py38haa95532_0
- markupsafe=2.1.1=py38h2bbff1b_0
- matplotlib-inline=0.1.6=py38haa95532_0
- mistune=0.8.4=py38he774522_1000
- mkl=2021.4.0=haa95532_640
- mkl-service=2.4.0=py38h2bbff1b_0
- mkl_fft=1.3.1=py38h277e83a_0
- mkl_random=1.2.2=py38hf11a4ad_0
- multidict=6.0.2=py38h2bbff1b_0
- nbclassic=0.5.5=py38haa95532_0
- nbclient=0.5.13=py38haa95532_0
- nbconvert=6.5.4=py38haa95532_0
- nbformat=5.9.2=py38haa95532_0
- nest-asyncio=1.5.6=py38haa95532_0
- notebook=6.5.4=py38haa95532_1
- notebook-shim=0.2.2=py38haa95532_0
- numexpr=2.8.4=py38h5b0cc5e_0
- numpy=1.20.3=py38ha4e8547_0
- numpy-base=1.20.3=py38hc2deb75_0
- oauthlib=3.2.2=py38haa95532_0
- openssl=1.1.1w=h2bbff1b_0
- opt_einsum=3.3.0=pyhd3eb1b0_1
- packaging=23.1=py38haa95532_0
- pandas=1.5.2=py38hf11a4ad_0
- pandocfilters=1.5.0=pyhd3eb1b0_0
- parso=0.8.3=pyhd3eb1b0_0
- pickleshare=0.7.5=pyhd3eb1b0_1003
- pip=23.2.1=py38haa95532_0
- pkgutil-resolve-name=1.3.10=py38haa95532_0
- platformdirs=3.10.0=py38haa95532_0
- pooch=1.4.0=pyhd3eb1b0_0
- prometheus_client=0.14.1=py38haa95532_0
- prompt-toolkit=3.0.36=py38haa95532_0
- protobuf=3.17.2=py38hd77b12b_0
- psutil=5.9.0=py38h2bbff1b_0
- pure_eval=0.2.2=pyhd3eb1b0_0
- pyasn1=0.4.8=pyhd3eb1b0_0
- pyasn1-modules=0.2.8=py_0
- pycparser=2.21=pyhd3eb1b0_0
- pygments=2.15.1=py38haa95532_1
- pyjwt=2.4.0=py38haa95532_0
- pyopenssl=23.2.0=py38haa95532_0
- pyreadline=2.1=py38_1
- pyrsistent=0.18.0=py38h196d8e1_0
- pysocks=1.7.1=py38haa95532_0
- python=3.8.12=h6244533_0
- python-dateutil=2.8.2=pyhd3eb1b0_0
- python-fastjsonschema=2.16.2=py38haa95532_0
- python-flatbuffers=1.12=pyhd3eb1b0_0
- pytz=2022.7=py38haa95532_0
- pywin32=305=py38h2bbff1b_0
- pywinpty=2.0.10=py38h5da7b33_0
- pyzmq=23.2.0=py38hd77b12b_0
- re2=2022.04.01=hd77b12b_0
- requests=2.31.0=py38haa95532_0
- requests-oauthlib=1.3.0=py_0
- rsa=4.7.2=pyhd3eb1b0_1
- scikit-learn=1.2.2=py38hd77b12b_0
- scipy=1.10.1=py38h321e85e_0
- send2trash=1.8.0=pyhd3eb1b0_1
- setuptools=68.0.0=py38haa95532_0
- six=1.16.0=pyhd3eb1b0_1
- snappy=1.1.9=h6c2663c_0
- sniffio=1.2.0=py38haa95532_1
- soupsieve=2.4=py38haa95532_0
- sqlite=3.41.2=h2bbff1b_0
- stack_data=0.2.0=pyhd3eb1b0_0
- tbb=2021.8.0=h59b6b97_0
- tensorboard=2.6.0=py_1
- tensorboard-data-server=0.6.1=py38haa95532_0
- tensorboard-plugin-wit=1.8.1=py38haa95532_0
- tensorflow=2.6.0=gpu_py38hc0e8100_0
- tensorflow-base=2.6.0=gpu_py38hb3da07e_0
- tensorflow-estimator=2.6.0=pyh7b7c402_0
- tensorflow-gpu=2.6.0=h17022bd_0
- termcolor=2.1.0=py38haa95532_0
- terminado=0.17.1=py38haa95532_0
- threadpoolctl=2.2.0=pyh0d69192_0
- tinycss2=1.2.1=py38haa95532_0
- tornado=6.3.2=py38h2bbff1b_0
- traitlets=5.7.1=py38haa95532_0
- typing-extensions=4.7.1=py38haa95532_0
- typing_extensions=4.7.1=py38haa95532_0
- urllib3=1.26.16=py38haa95532_0
- vc=14.2=h21ff451_1
- vs2015_runtime=14.27.29016=h5e58377_2
- wcwidth=0.2.5=pyhd3eb1b0_0
- webencodings=0.5.1=py38_1
- websocket-client=0.58.0=py38haa95532_4
- werkzeug=2.2.3=py38haa95532_0
- wheel=0.35.1=pyhd3eb1b0_0
- win_inet_pton=1.1.0=py38haa95532_0
- winpty=0.4.3=4
- wrapt=1.14.1=py38h2bbff1b_0
- yarl=1.8.1=py38h2bbff1b_0
- zeromq=4.3.4=hd77b12b_0
- zipp=3.11.0=py38haa95532_0
- zlib=1.2.13=h8cc25b3_0
- pip:
- contourpy==1.1.1
- cycler==0.11.0
- fonttools==4.42.1
- importlib-resources==6.0.1
- kiwisolver==1.4.5
- matplotlib==3.7.3
- pillow==10.0.1
- pyparsing==3.1.1
prefix: C:\Users\zclhl\anaconda3\envs\tf
导入的时候只需要:
conda env create -f my_environment.yml
非线性二分类任务实战
先测试一下GPU是否可用:
import tensorflow as tf
# tf.test.gpu_device_name()
print(tf.test.is_gpu_available())
WARNING:tensorflow:From C:\Users\zclhl\AppData\Local\Temp\ipykernel_13180\3149783646.py:3: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
True
下面开始编码:
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
data.head()
| x1 | x2 | y | |
|---|---|---|---|
| 0 | 0.0323 | 0.0244 | 1 |
| 1 | 0.0887 | 0.0244 | 1 |
| 2 | 0.1690 | 0.0163 | 1 |
| 3 | 0.2420 | 0.0000 | 1 |
| 4 | 0.2420 | 0.0488 | 1 |
#define X y
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
X.head()
| x1 | x2 | |
|---|---|---|
| 0 | 0.0323 | 0.0244 |
| 1 | 0.0887 | 0.0244 |
| 2 | 0.1690 | 0.0163 |
| 3 | 0.2420 | 0.0000 |
| 4 | 0.2420 | 0.0488 |
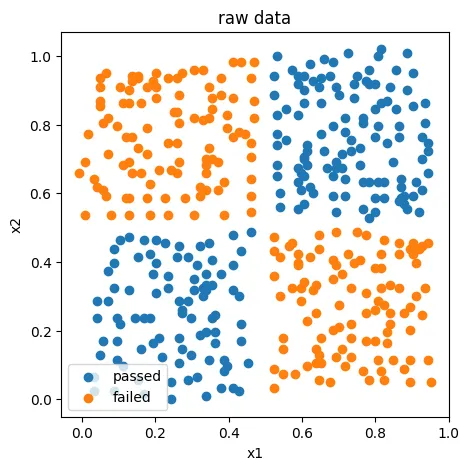
#visualize data
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(5,5))
passed = plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
failed = plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
plt.legend((passed, failed),('passed','failed'))
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('raw data')
plt.show()
# 数据分离
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.13,random_state=10)
print(X_train.shape, X_test.shape, X.shape)
(357, 2) (54, 2) (411, 2)
#构建模型
from keras.models import Sequential
from keras.layers import Dense,Activation
mlp = Sequential()
mlp.add(Dense(units=20,input_dim=2,activation="sigmoid"))#20个神经元 激活函数digmoid
mlp.add(Dense(units=1,activation="sigmoid"))
mlp.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 20) 60
_________________________________________________________________
dense_1 (Dense) (None, 1) 21
=================================================================
Total params: 81
Trainable params: 81
Non-trainable params: 0
_________________________________________________________________
#配置模型参数,优化方法 损失函数
mlp.compile(optimizer="adam",loss="binary_crossentropy")#二分类的
#模型训练,迭代3000次
mlp.fit(X_train,y_train,epochs=3000)
Epoch 1/3000
12/12 [==============================] - 1s 3ms/step - loss: 0.9955
Epoch 2/3000
12/12 [==============================] - 0s 2ms/step - loss: 0.9439
Epoch 3/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.8962
Epoch 4/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.8561
Epoch 5/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.8213
Epoch 6/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7920
Epoch 7/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7678
Epoch 8/3000
12/12 [==============================] - 0s 2ms/step - loss: 0.7494
Epoch 9/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7363
Epoch 10/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7255
Epoch 11/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7165
Epoch 12/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.7105
……
Epoch 2996/3000
12/12 [==============================] - 0s 4ms/step - loss: 0.1437
Epoch 2997/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.1436
Epoch 2998/3000
12/12 [==============================] - 0s 3ms/step - loss: 0.1435
Epoch 2999/3000
12/12 [==============================] - 0s 4ms/step - loss: 0.1438
Epoch 3000/3000
12/12 [==============================] - 0s 4ms/step - loss: 0.1433
<keras.callbacks.History at 0x1da35d40280>
#make prediction and calc accuary
# y_train_predict = mlp.predict_classes(X_train)
y_train_predict = (mlp.predict(X_train) > 0.5).astype("int32")
from sklearn.metrics import accuracy_score
acc_train = accuracy_score(y_train, y_train_predict)
print(acc_train)
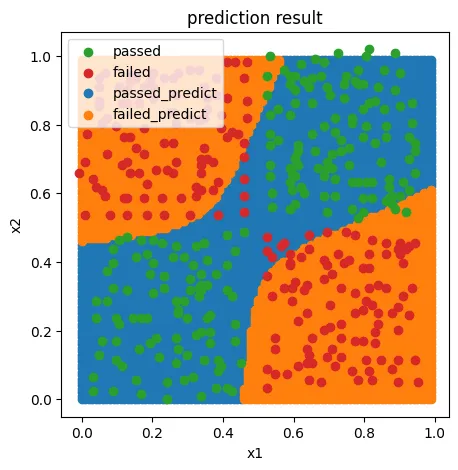
0.9551820728291317
y_test_predict = (mlp.predict(X_test) > 0.5).astype("int32")
#from sklearn.metrics import accuracy_score
acc_test = accuracy_score(y_test, y_test_predict)
print(acc_test)
0.9629629629629629
print(type(y_train_predict), y_train_predict)
<class 'numpy.ndarray'> [[0]
[1]
[0]
[1]
[1]
[1]
[0]
[0]
[0]
[1]
[0]
[1]
[0]
[0]
[1]
[0]
#generate new data for plot
xx, yy = np.meshgrid(np.arange(0,1,0.01),np.arange(0,1,0.01))
x_range = np.c_[xx.ravel(),yy.ravel()]
#y_range_predict = mlp.predict_classes(x_range)
y_range_predict = (mlp.predict(x_range) > 0.5).astype("int32")
print(type(y_range_predict))
<class 'numpy.ndarray'>
#format the output
y_range_predict_form = pd.Series(i[0] for i in y_range_predict)
print(y_range_predict_form)
0 1
1 1
2 1
3 1
4 1
..
9995 1
9996 1
9997 1
9998 1
9999 1
Length: 10000, dtype: int32
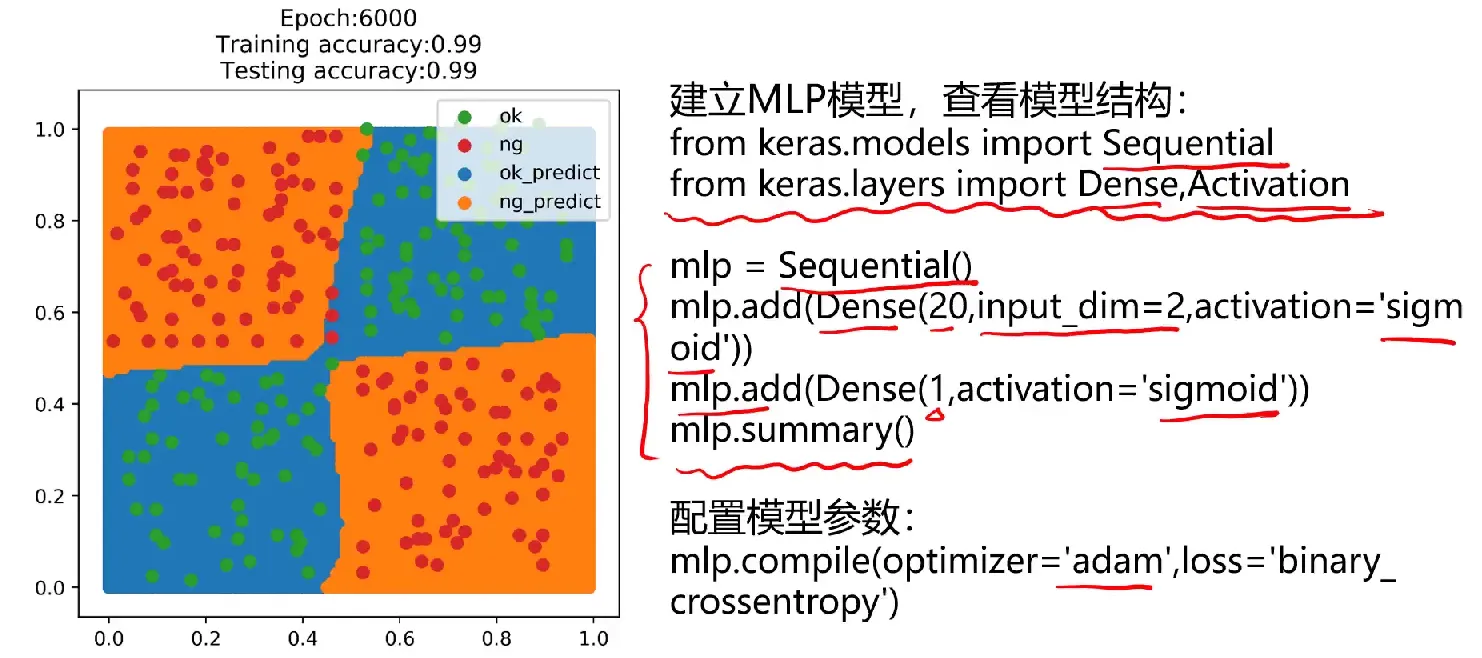
fig2 = plt.figure(figsize=(5,5))
passed_predict=plt.scatter(x_range[:,0][y_range_predict_form==1],x_range[:,1][y_range_predict_form==1])
failed_predict=plt.scatter(x_range[:,0][y_range_predict_form==0],x_range[:,1][y_range_predict_form==0])
passed=plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
failed=plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
plt.legend((passed,failed,passed_predict,failed_predict),('passed','failed','passed_predict','failed_predict'))
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('prediction result')
plt.show()