数据分离与混淆矩阵
建立模型的意义,不在于对训练数据做出准确预测,更在于对新数据的准确预测。在分类中,如何评判模型的好坏呢,之前的学习中主要是通过计算测试数据集预测准确率(accuracy)以评估模型表现,但是现在有了更好的评估方案,那就是混淆矩阵。另外在仅有训练数据的情况下如何评估模型表现呢?这个时候就需要做一些数据分离的工作。最后会讨论模型的选择与优化相关的问题。
数据分离
前面学习过的示例基本流程都是这样的,通常来说分为5步:
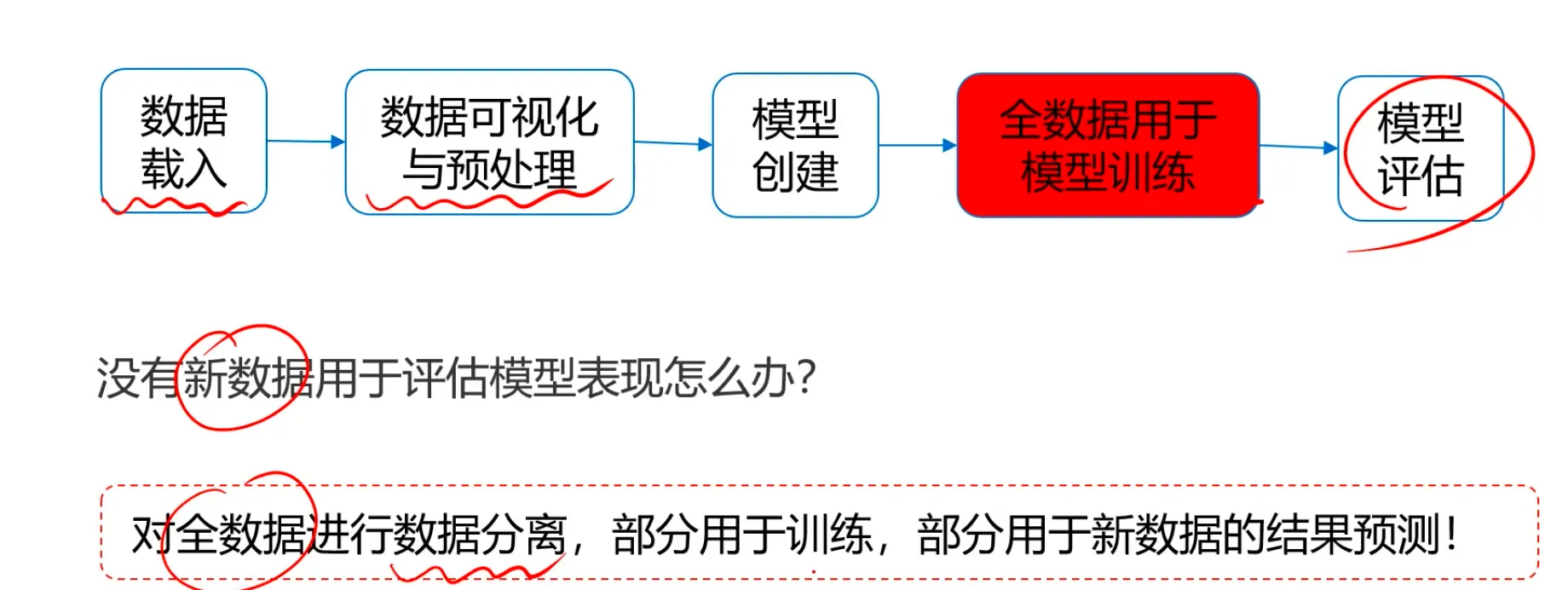
按照这个流程的前提是我们要有新数据来作为测试数据供我们使用,那么如果我们没有新数据用于模型评估表现怎么办呢?这时就需要用到数据分离了。简单来说数据分离就是对全数据进行数据分离,部分数据用来训练,部分数据用于新数据的结果预测。
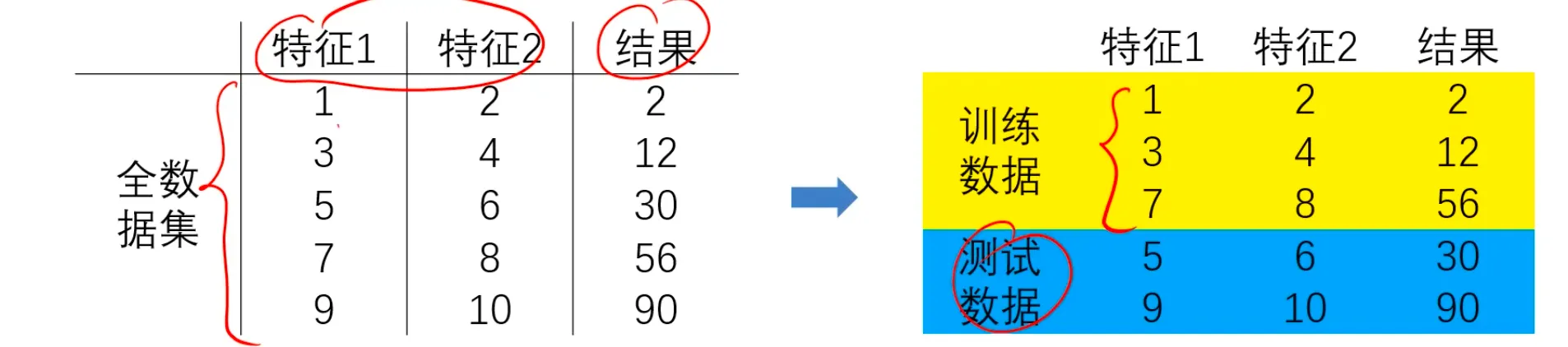
分离训练数据与测试数据,把数据分成两部分:训练集、测试集
1.使用训练集数据进行模型训练
2.使用测试集数据进行预测,更有效地评估模型对于新数据的预测表现
混淆矩阵
分类任务中,计算测试数据集预测准确率(accuracy)以评估模型表现
accuracy的局限性: 无法真实反映模型针对每个分类的预测准确度:
来看看 0-1 二分类的的例子:

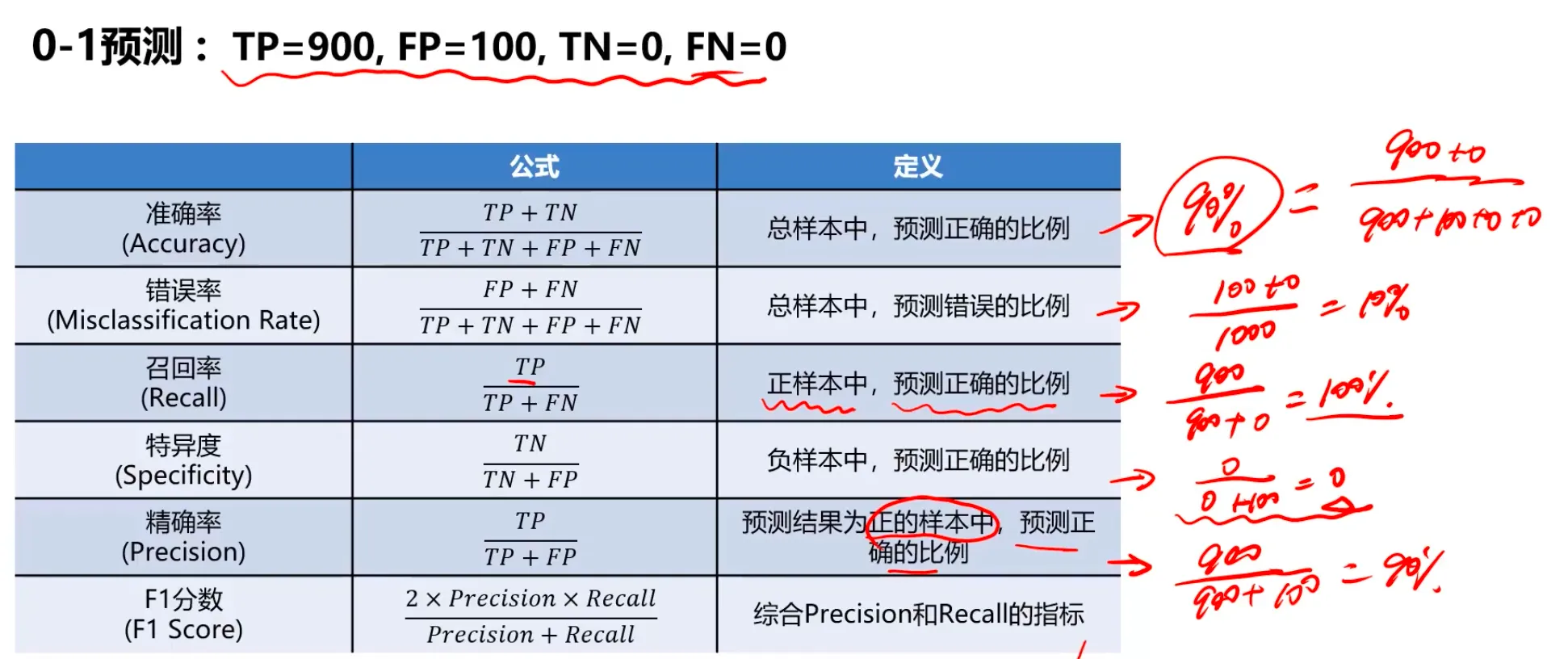
其实很好理解,虽然accuracy计算的准确率都是90%,但是建立模型的意义来看明显模型1的效果是远远超出模型2的。模型2这种情况就是空准确率!
准确率可以方便的用于衡量模型的整体预测效果,但无法反应细节信息,具体表现在:
1、没有体现数据预测的实际分布情况 (0、1本身的分布比例)
2、没有体现模型错误预测的类型
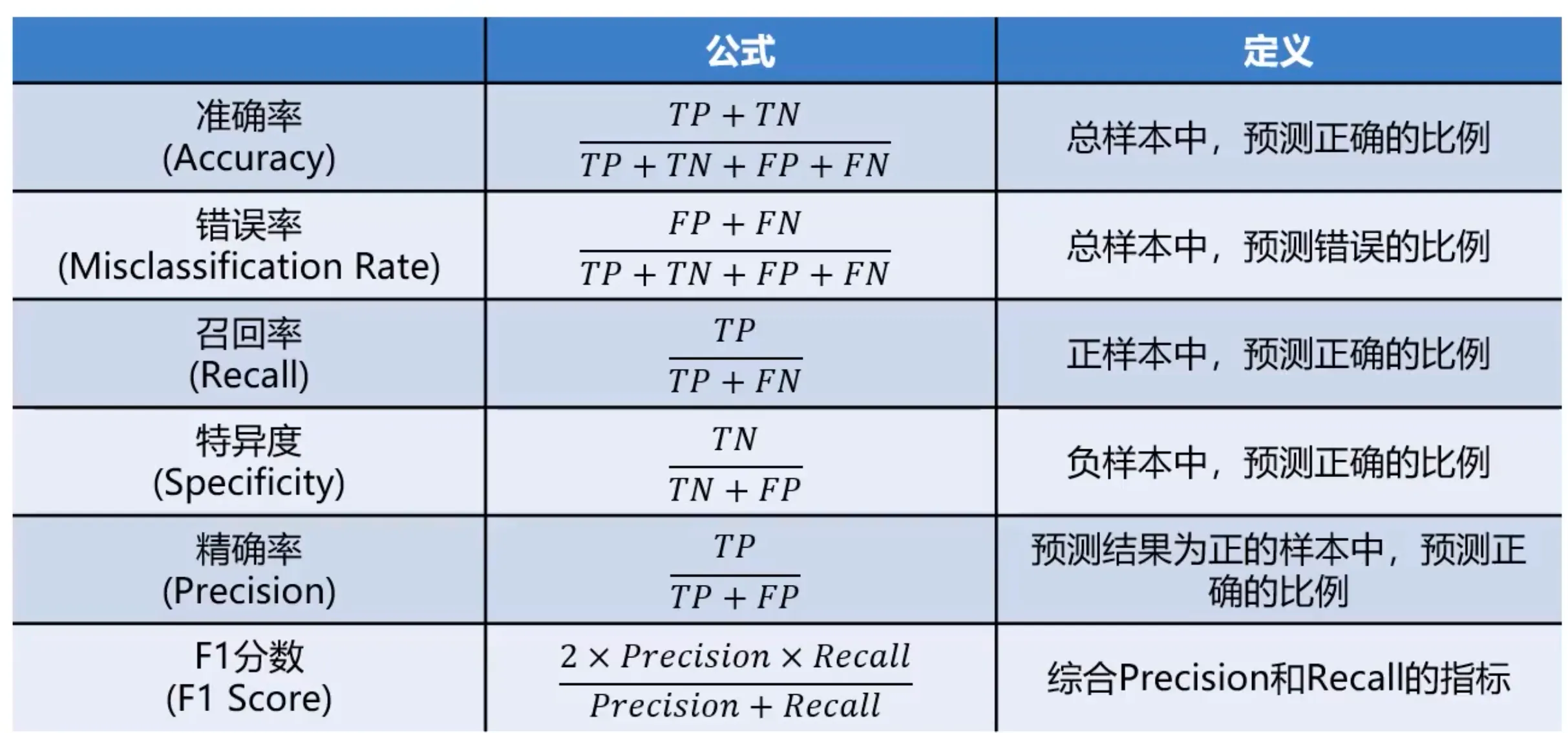
混淆矩阵,又称为误差矩阵用于衡量分类算法的准确程度。

True Positives(TP): 预测准确、实际为正样本的数量(实际为1,预测为1)
True Negatives(TN): 预测准确、实际为负样本的数量 (实际为0,预测为0)
False Positives(FP): 预测错误、实际为负样本的数量(实际为0,预测为1)
False Negatives(FN): 预测错误、实际为正样本的数量(实际为1,预测为0)
(预测结果正确或错误,预测结果为正样本或负样本)
通过混淆矩阵,可以计算更丰富的模型评估指标:
0-1二分类的采用混淆矩阵评估示例
用混淆矩阵来看看 0-1 二分类的的例子:
实际:900个1,100个0
预测:1000个,0个0;
假设负样本为0,正样本为1
则 TP = 900,FP = 100,TN = 0,FN = 0
混淆矩阵指标特点
1、分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息(TP\TN\FP\FN)
2、通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型。
那么哪个衡量指标更关键呢?其实衡量指标的选择取决于应用场景!
垃圾邮件检测(正样本为“垃圾邮件”) 希望普通邮(负样本)不要被判断为垃圾邮(正样本),即:判断为垃圾邮件的样本都是判断正确的,需要关注精确率,还希望所有的垃圾邮件尽可能被判断出来,需要关注召回率。
异常交易检测(正样本为“异常交易”) 希望判断为正常的交易 (负样本)中尽可能不存在异常交易,还需要关注特异度。
模型选择与优化
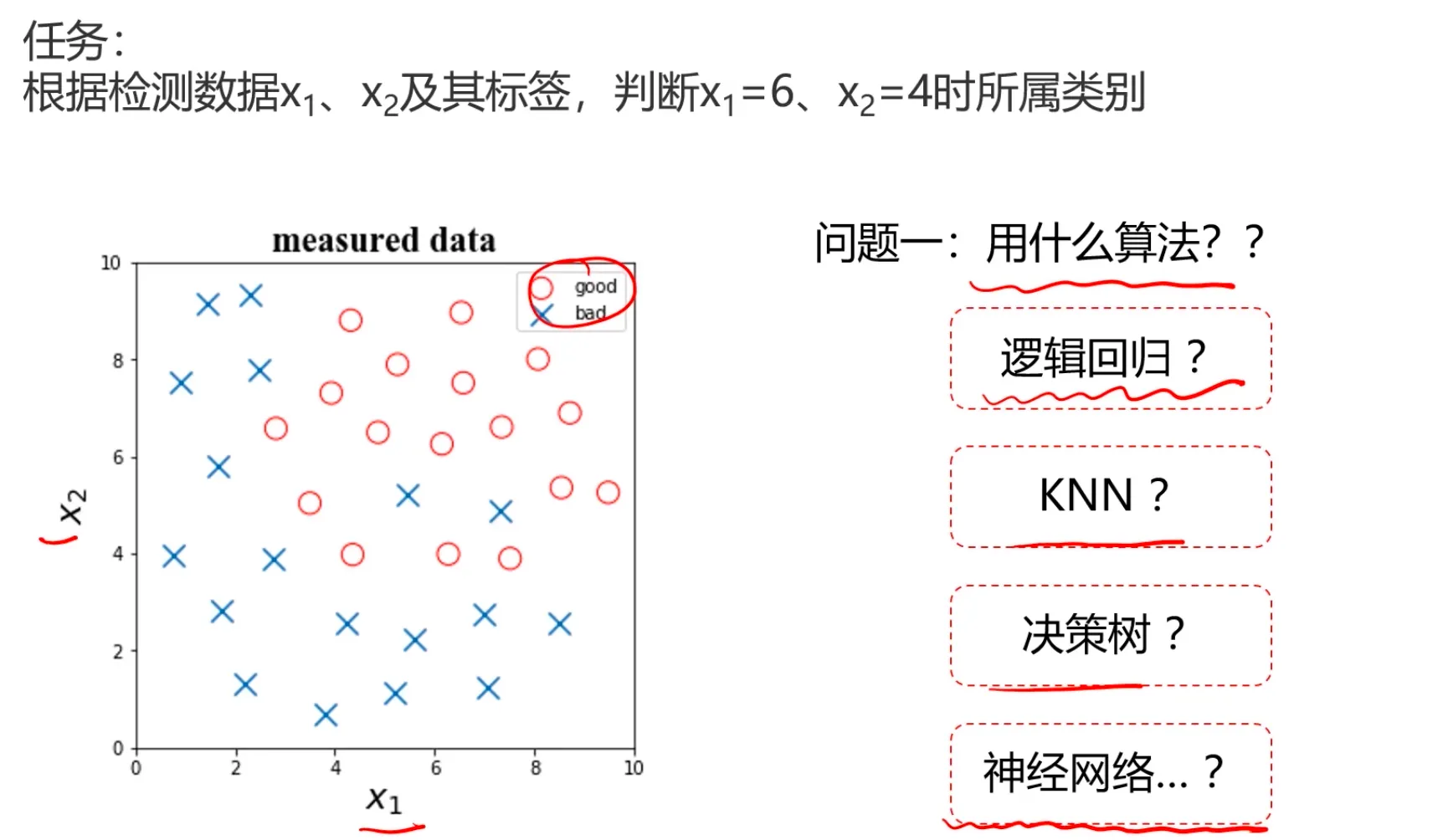
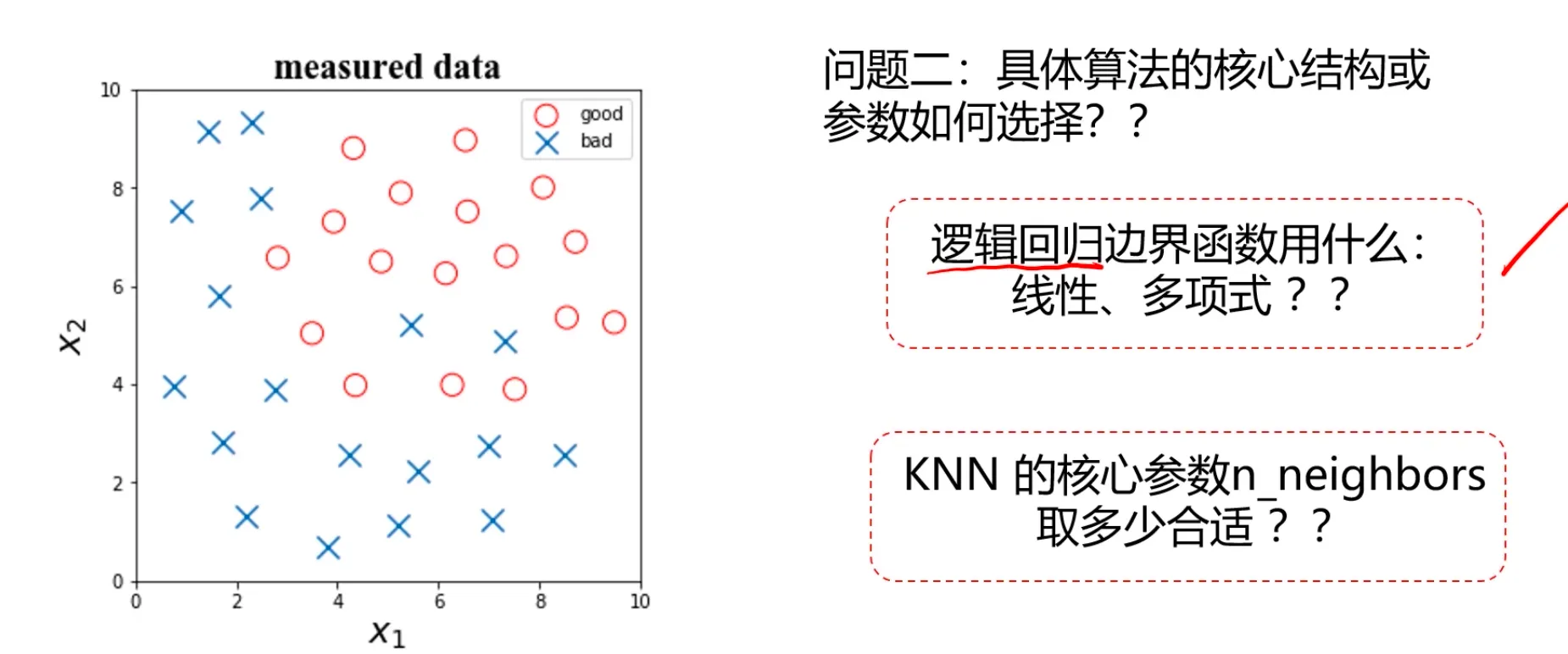
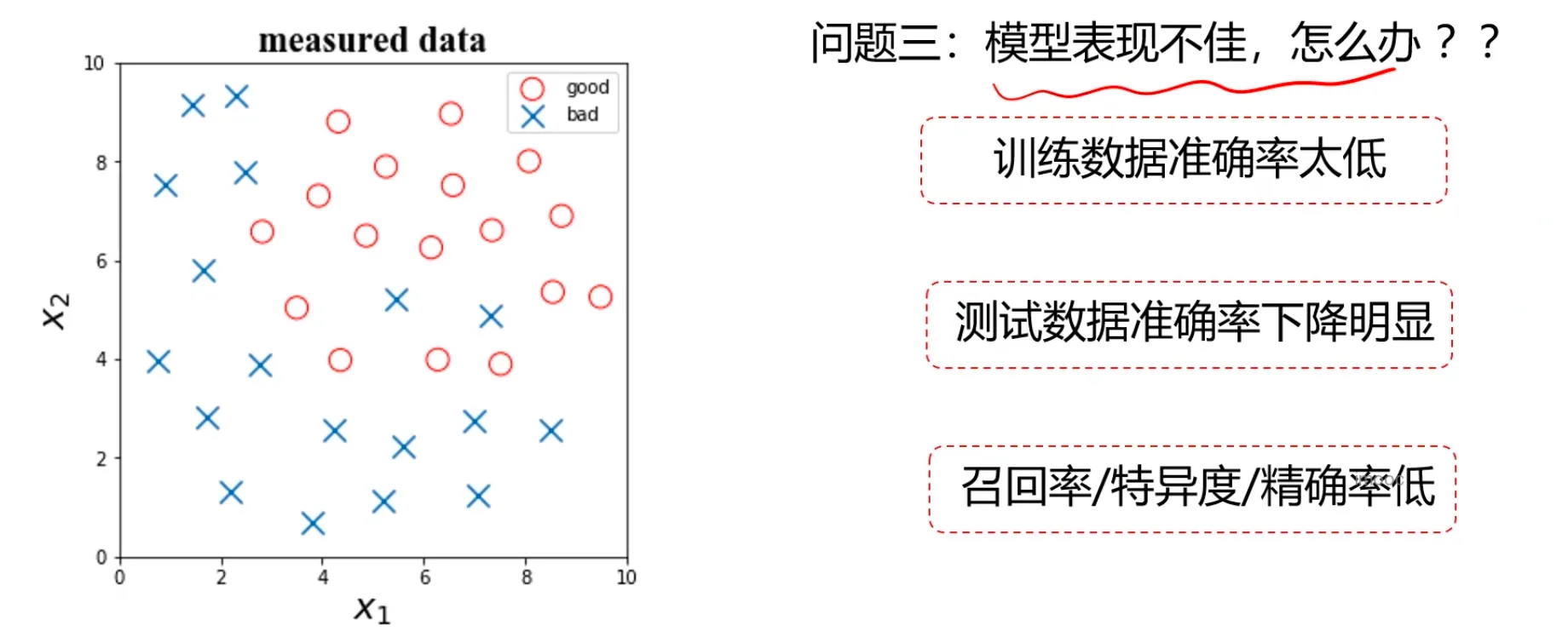
那么如何提高模型表现呢?
数据质量决定模型表现质量的上限
Always check:
1、数据属性的意义,是否为无关数据
2、不同属性数据的数量级差异性如何
3、是否有异常数据,可以用异常检测看看异常的数据点
4、采集数据的方法是否合理,采集到的数据是否有代表性
5、对于标签结果,要确保标签判定规则的一致性 (统一标准)
Always try:
1、删除不必要的属性
2、数据预处理: 归一化、标准化
3、确定是否保留或过滤掉异常数据
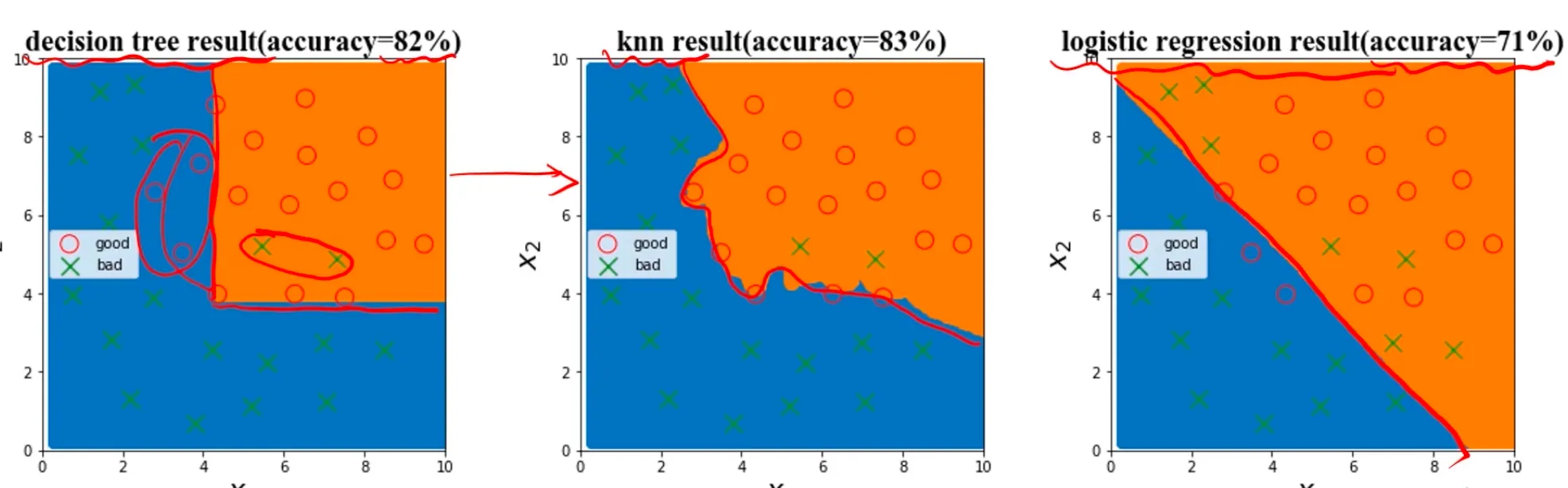
4、尝试不同的模型,对比模型表现
Benefits:
1、减少过拟合、节约运算时间
2、平衡数据影响,加快训练收敛
3、提高鲁棒性
4、帮助确定更合适的模型
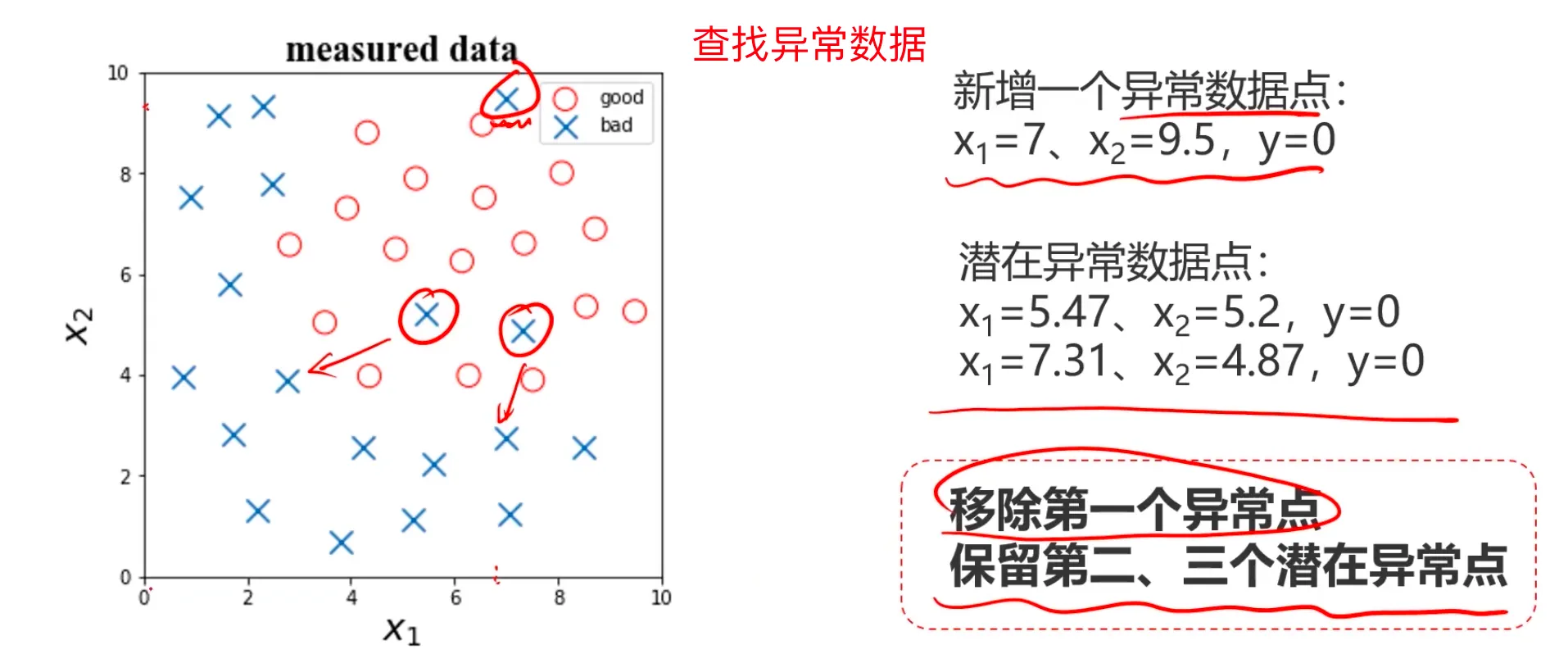
查找异常数据,通过可视化的方式看看异常点:
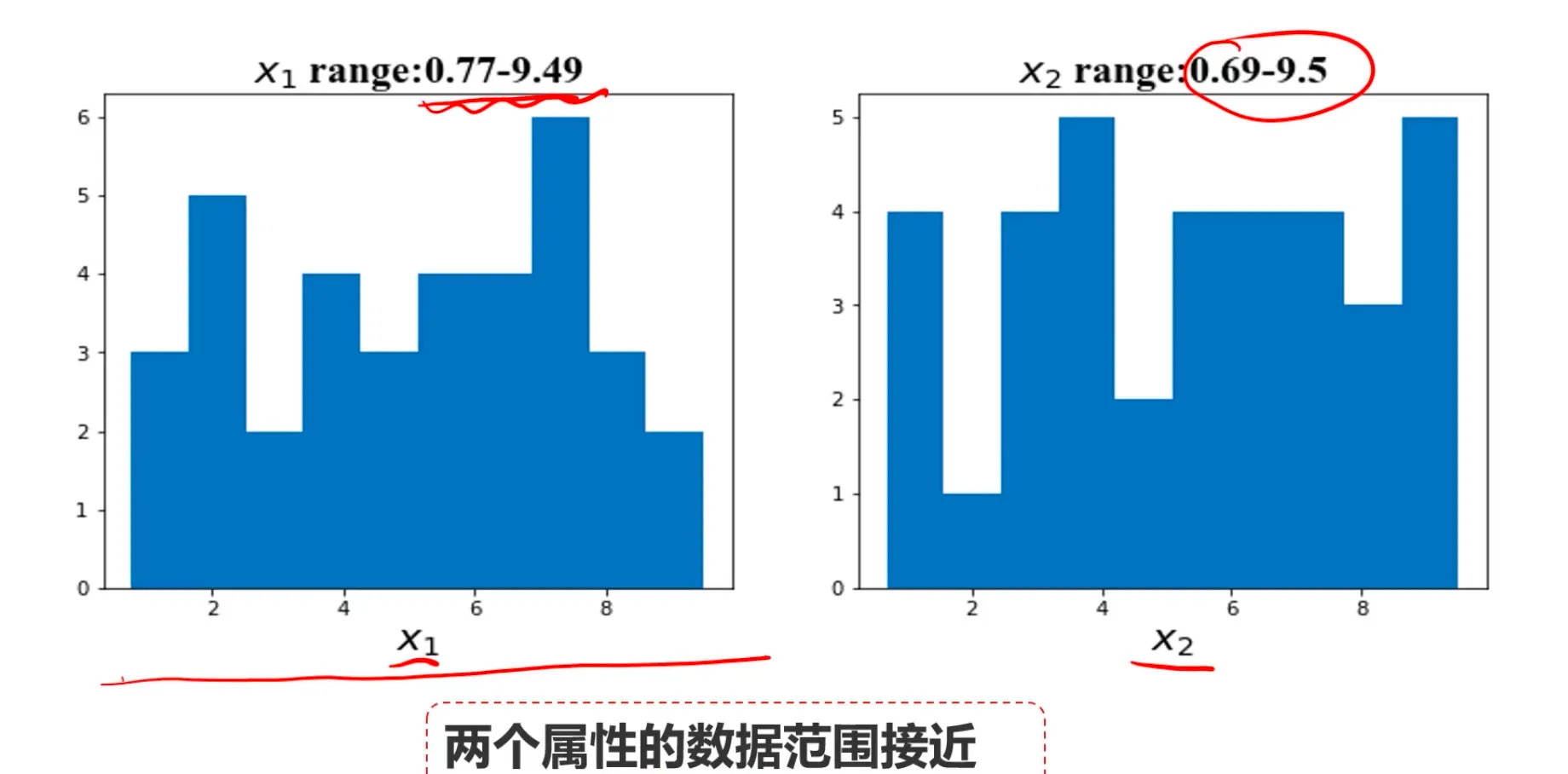
对比各个特征的数据范围,看看属性之间是否接近:
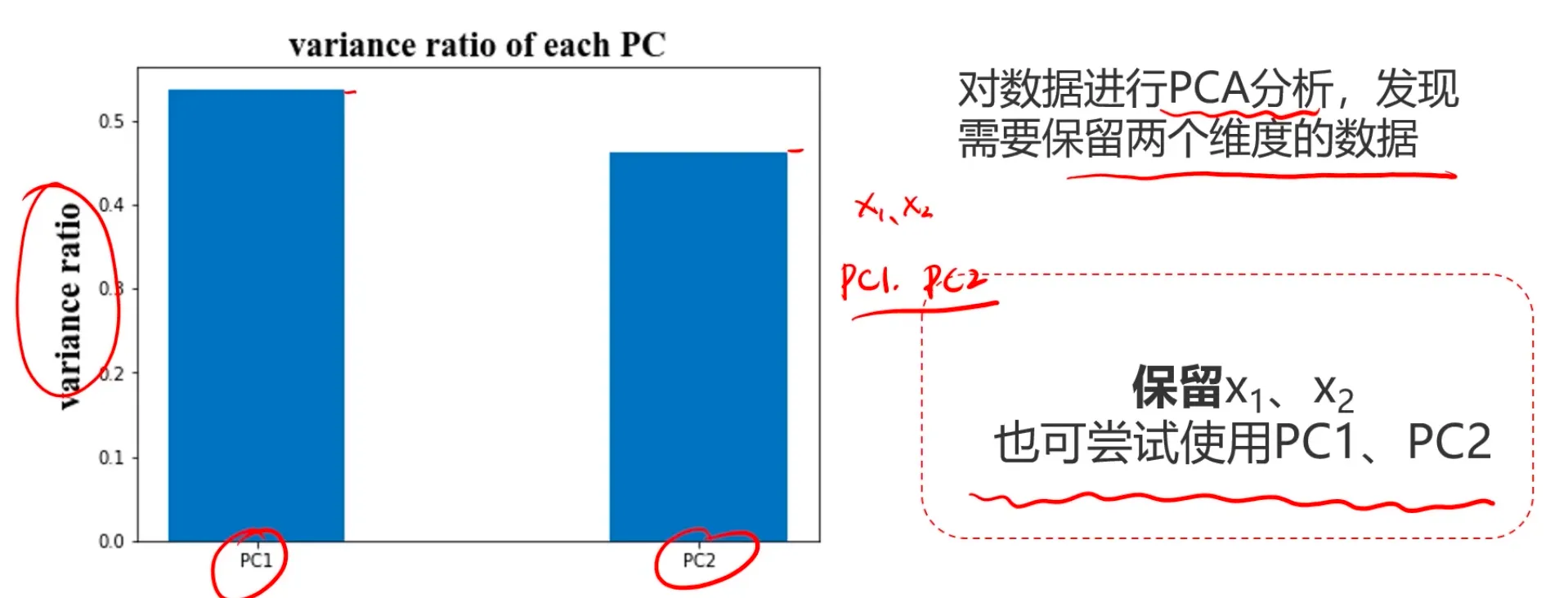
PCA分析,看看数据维度是否能减少:
尝试不同的模型,看看准确率:
目标: 在确定模型类别后,如何让模型表现更好
三方面:数据、模型核心参数、正则化,可以尝试以下方法:
1、遍历核心参数组合,评估对应模型表现(逻辑回归边界函数考虑多项式、KNN尝试不同的n_neighbors值)
2、扩大数据样本
3、增加或减少数据属性
4、对数据进行降维处理
5、对模型进行正则化处理,调整正则项入的数值
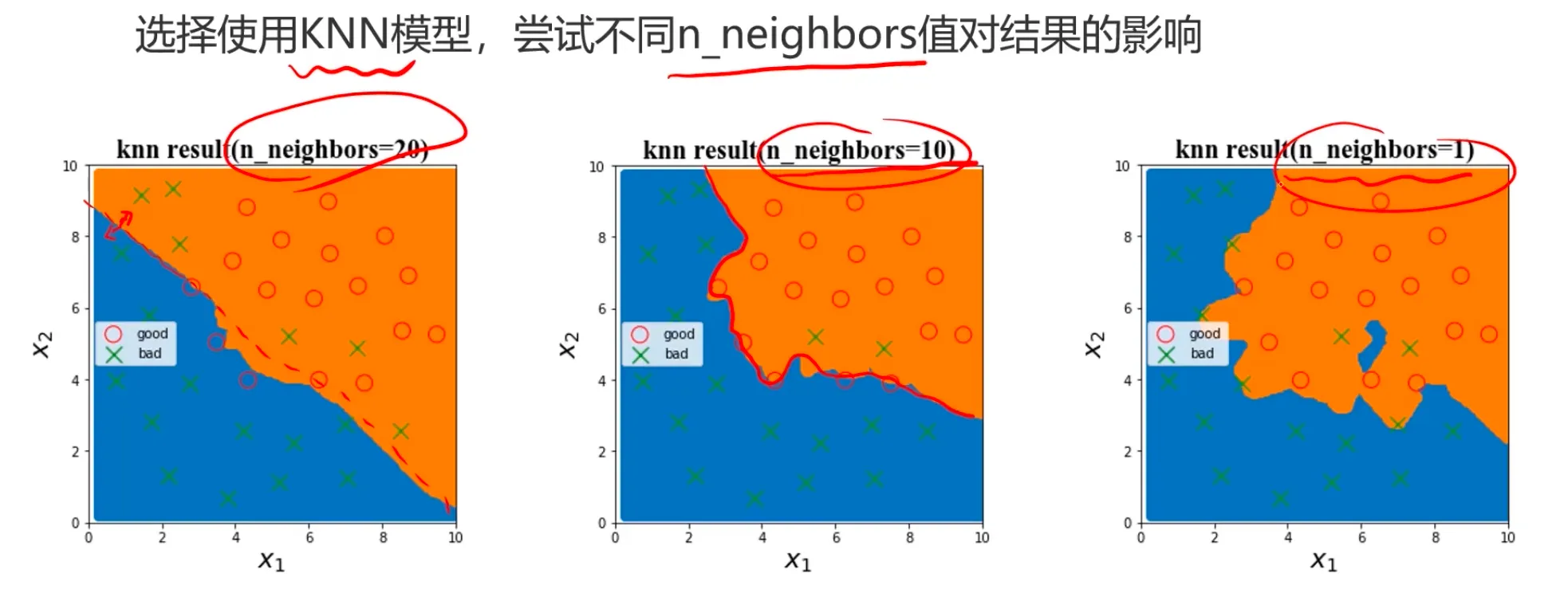 n_neighbors值越小,KNN模型复杂度越高,可能效果也会变好(注意是可能,并不是越复杂越好)。
n_neighbors值越小,KNN模型复杂度越高,可能效果也会变好(注意是可能,并不是越复杂越好)。
问题: 以下说法,哪些是错误的,为什么?
- A、为了达到更好的预测效果,用于训练的数据越多越好
- B、样本数据噪音大,只要模型选的好,就能弥补数据的不足
- C、选择模型时,选择准确率最高的即可
- D、通过可视化数据,有助于分析模型表现与选择合适的模型
下面我说说我的观点:A错误,并不是越大越好,而是覆盖越全、类别均匀、特征明显、维度合适、异常数据少才是比较好的样本数据。B错误,噪音大应该想办法去除噪声,而且不是在选择模型上死磕。C错误,根据混淆矩阵,根据业务选择合适的评估指标才对。D正确。