LLM + Vector DB应用初探
在大模型的应用中,不断涌现出B端对专用数据的需求、C端对个性化与自动化的需求,带来给大模型增加记忆功能的刚性需求,相关产品需求量快速增长。众所周知,如今如火如荼的ChatGPT确实可以帮助我们解决许多问题,但是其作为一款语言大模型,从原理上就不容易实现记录与用户的全部历史对话,以及历史对话过程中的关键信息,这些信息往往只存在一次Session中。为了解决大模型没有“记忆”的问题,引入了向量数据库。
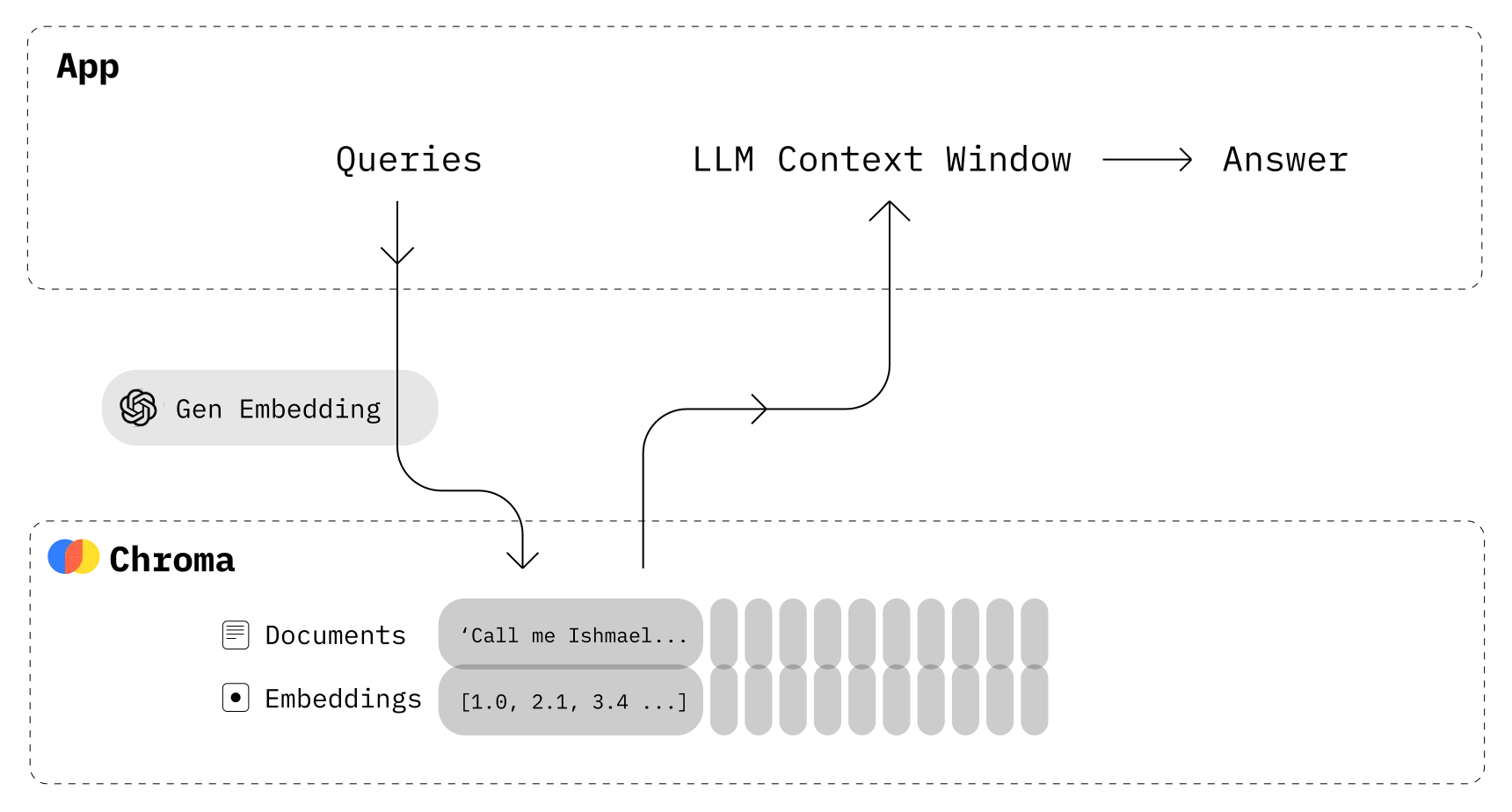
向量数据库定义
| 概念 | 定义 | 备注 |
|---|---|---|
| 向量 | 为AI理解世界的通用数据形式,是多模态数据的压缩 | 虽然大模型端到端呈现的都是文字文本,但模型实际接触和学习数据是向量化文本,因为文本本身直接作为数据维度太高,机器学习效率太低 |
| Embedding | 将文字文本转化为保留语义关系的向量文本 | 即embedding模型对自然语言的压缩和总结,将高维数据映射到低维空间 |
| 向量搜索 | 在海量存储的向量中找到最符合要求的Top N个目标。向量搜索是模糊匹配,返回的是相对最符合要求的N个数据,并没有精确标准答案 | 传统数据库索引是精确匹配,也就是说,传统数据库中的数据要么符合查询要求/返回数据,要么不符合查询要求/无数据返回 |
| 向量数据库 | 用以高效存储和搜索向量。保证100%信息完整的情况下,通过向量嵌入函数(embedding)精准描写非结构化数据的特征,从而提供查询、删除、修改、元数据过滤等操作 | 传统数据库无法满足此类操作和需求,只能实现部分向量数据的存储,且无法高效搜索向量 |
从向量搜索到向量数据库:虽然向量数据库当前最主要的使用场景和火热原因是因为它为大模型提供记忆。但其实向量的embedding结构和向量搜索算法之前就已经出现,只是在大模型出现之前,向量搜索需求只存在于大厂,大厂自研向量搜索算法即可,且没有很强的向量存储需求。
伴随着 ML/AI 模型发展到今天,一直到大模型场景下,向量搜索和存储的需求才真正开始爆发式增长。向量数据库因为可以为大模型提供记忆而需求倍增,AutoGPT更是把对向量数据库需求量推到了更高的水平,AutoGPT从一开始就是采用了OpenAI API + Pinecone的模式。
有记忆交互VS无记忆交互
无记忆交互:在初始的LLM中,世界知识和语义理解被压缩为静态参数,模型不会随着交互记住用户的聊天记录和喜好,也无法调用额外知识信息来辅助判断,因此模型只能根据历史训练数据回答问题,并且经常产生幻觉,给出与事实相悖的答案。一个解决方法是在 Prompt 中将知识告诉模型,但是这往往受限于 token 数量,在 GPT-4 之前一般是 4000 个字的限制,且不经济,而且过多不相干信息还可能导致幻觉。
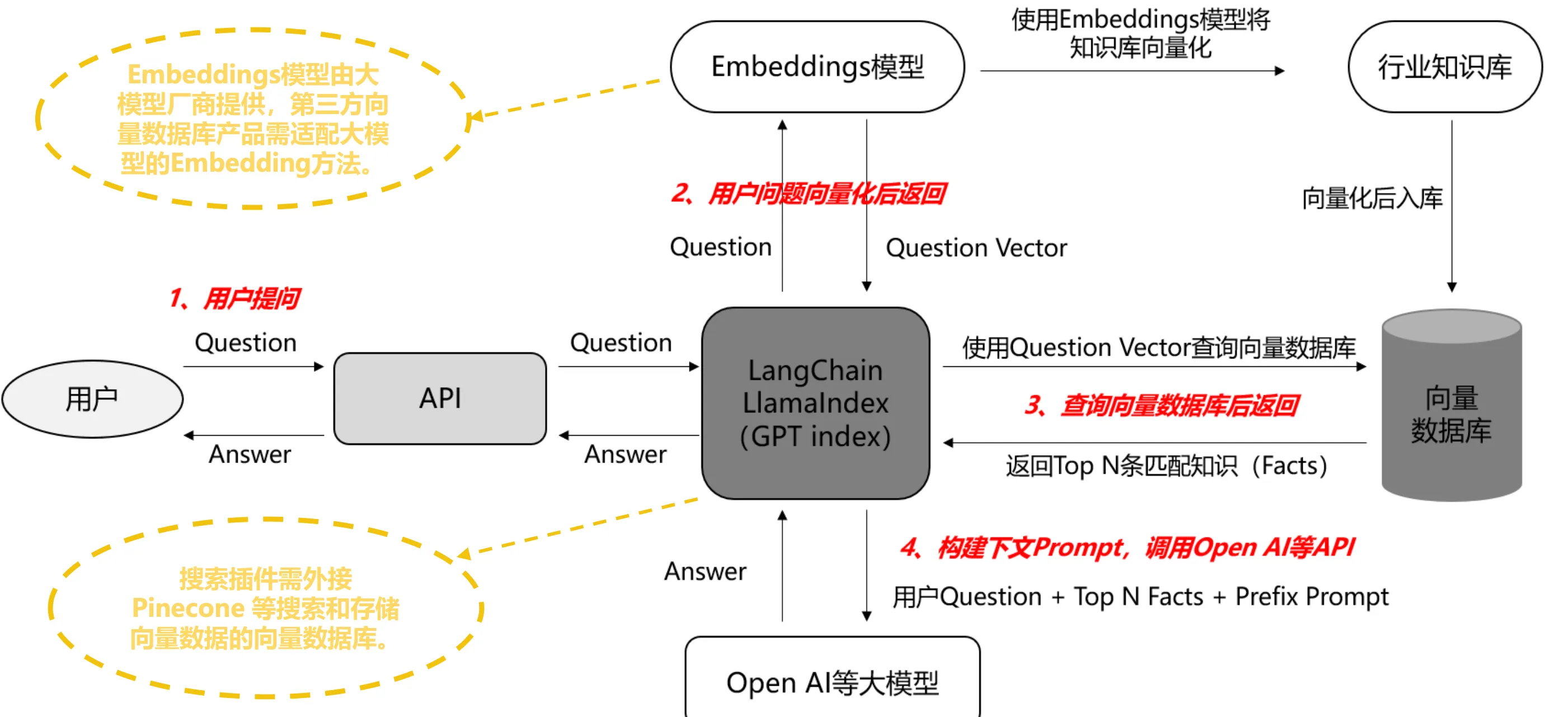
有记忆交互:当模型需要记忆大量的聊天记录或行业知识库时,可将其储存在向量数据库中,后续在提问时将问题向量化,送入向量数据库中匹配相似的语料作为prompt,向量数据库通过提供记忆能力使prompt更精简和精准,从而使返回结果更精准。
有记忆交互原理与流程
Step 1——语料库准备: 将与行业相关的大量知识或语料上传至向量数据库,储存为向量化文本;
Step 2 ——问题输入: 输入的问题被Embedding引擎变成带有向量的提问;
Step 3 ——向量搜索: 向量化问题进入提前准备好的向量数据库中,通过向量搜索引擎计算向量相似度,匹配出Top N条语义最相关的Facts(向量数据库是模糊匹配,输出的是概率上最近似的答案)
Step 4 —— Prompt优化: 输出的Top N条Facts,和用户的问题一起作为prompt输入给模型。
Step 5、结果返回: 有记忆交互下得到的生成内容更精准且缓解了幻觉问题。
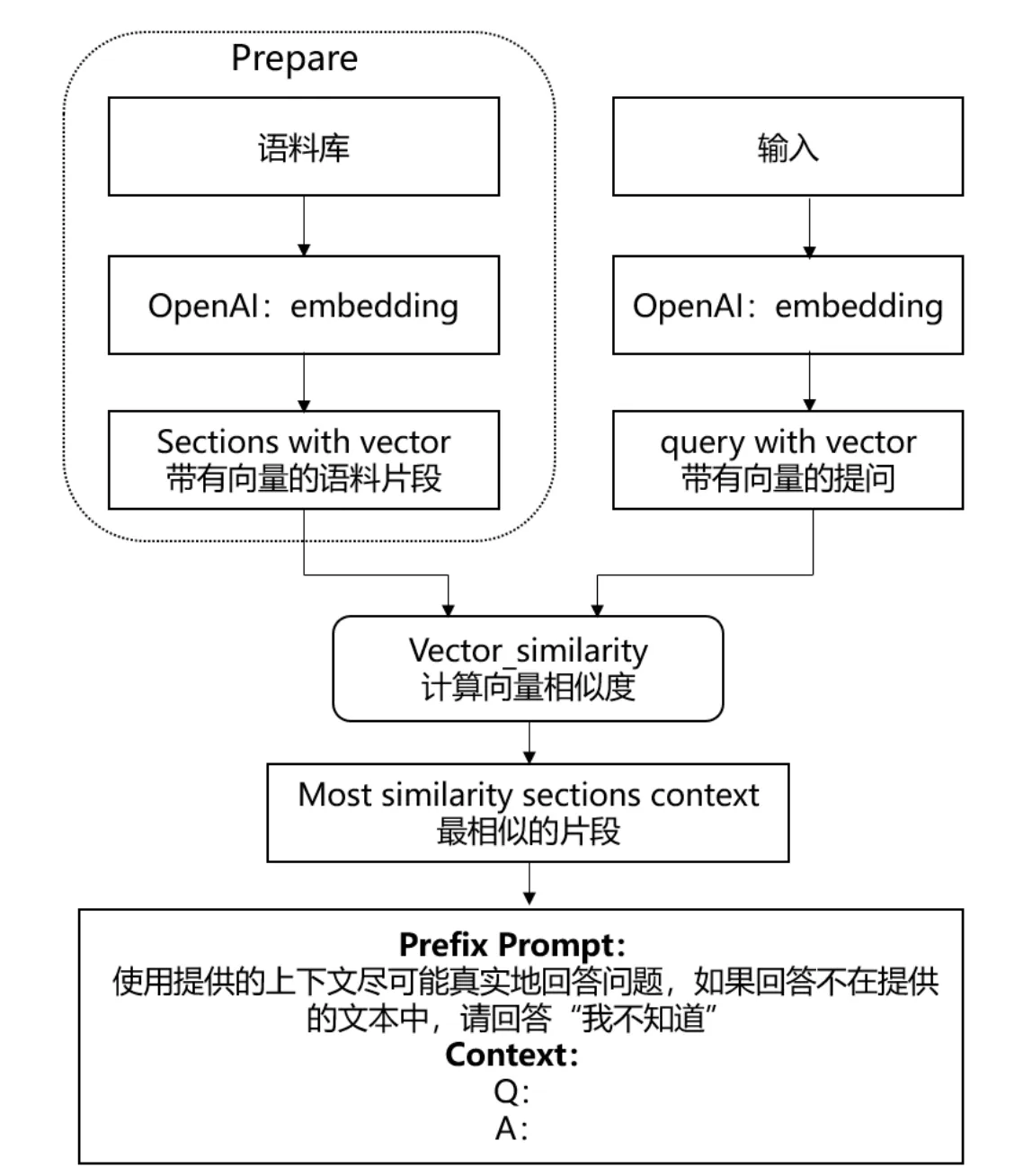
其实我们上面的核心问题就是:怎么在我们的数据集中检索到和prompt相似的内容?
embedding 一般是指将一个内容实体映射为低维向量,从而可以获得内容之间的相似度。
OpenAI 的 embedding 是计算文本与维度的相关性,默认的 ada-002 模型会将文本解析为 1536 个维度。用户可以通过文本之间的 embedding 计算相似度。
embedding 的使用场景是可以根据用户提供的语料片段与 prompt 内容计算相关度,然后将最相关的语料片段作为上下文放到 prompt 中,以提高 completion 的准确率。
代码实践
那么这些向量存放在哪以及怎么对向量的管理和检索怎么进行呢?这就是向量数据库的职责,相比于关系型数据库,向量数据库更擅长进行相似性的搜索,以及在数据存储量上也存在优势。
向量数据库可能每个人用的都不一样,我使用的是pinecone,其他还有Milvus、Zilliz啥的,没用过就不介绍了(主要是pingcone免费版申请直接就秒过了)
pinecone官网: https://www.pinecone.io/
pinecone文档: Python Client
进去之后免费版需要申请,不过应该挺好过。付费版好像是70刀一个月。
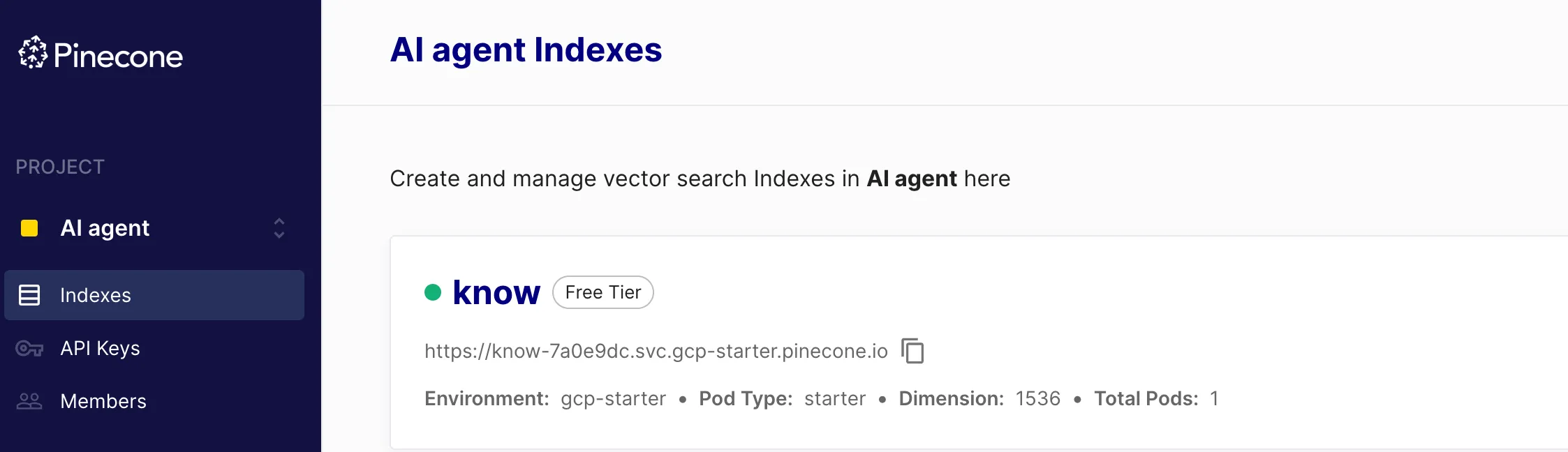
创建索引的时候需要选择特征维度:就是向量的数组长度,openAi将内容转成向量之后的长度是1536,所以我配置的是1536。
安装Python客户端:
pip3 install pinecone-client
相关的术语:
- Index:是Pinecone中向量数据的最高层组织单位。它接受和存储向量,服务于对其包含的向量的查询,并对它的内容进行其他向量操作。每个索引至少运行在一个pod上。
- Pod:用于运行 Pinecone 服务的预配置硬件单元。每个索引在一个或多个 pod 上运行。通常,更多的 pod 意味着更多的存储容量、更低的延迟和更高的吞吐量。您还可以创建不同大小的 pod。
- Collections:集合是索引的静态副本。它是一组向量和元数据的不可查询表示。您可以从索引创建集合,也可以从集合创建新索引。这个新索引可以不同于原始源索引:新索引可以有不同数量的 pod、不同的 pod 类型或不同的相似性度量。
import openai
import pinecone
openai.api_key = 'your openai key'
def main():
pinecone.init(api_key='your pinecone api key', environment='gcp-starter')
# 初始化索引
active_indexes = pinecone.list_indexes()
index = pinecone.Index(active_indexes[0])
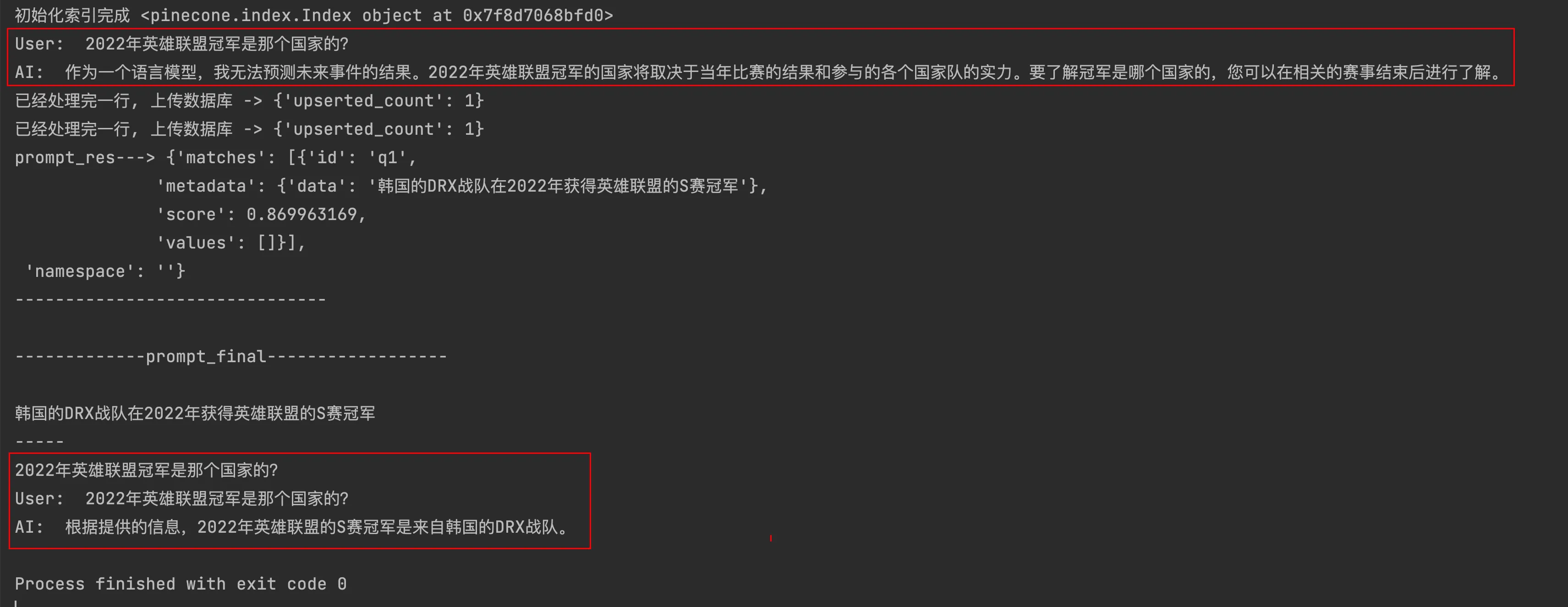
print('初始化索引完成', index)
# 提示词
prompt = "2022年英雄联盟冠军是那个国家的?"
# 与LLM交流
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
print("User: ", prompt)
print("AI: ", completion.choices[0].message.content)
# 读取知识库 & 生成知识库embedding vector
num = 0
with open('data/question_bank.txt', 'r') as file:
line = file.readline()
while line:
data_embedding_res = openai.Embedding.create(
model='text-embedding-ada-002',
input=line
)
# 更新知识库向量以及对应的元数据
upsertRes = index.upsert([
(f'q{num}', data_embedding_res['data'][0]['embedding'], {"data": line})
])
num = num + 1
print('已经处理完一行, 上传数据库 ->', upsertRes)
line = file.readline()
# 生成问题embedding vector
prompt_embedding_res = openai.Embedding.create(
model="text-embedding-ada-002",
input=prompt
)
# 查询向量数据库
prompt_res = index.query(
prompt_embedding_res['data'][0]['embedding'],
top_k=1,
include_metadata=True
)
print('prompt_res--->', prompt_res)
print('-------------------------------\n')
# 查询结果用来拼接prompt
# 重新构造prompts
contexts = [item['metadata']['data'] for item in prompt_res['matches']]
prompt_final = "---\n".join(contexts) + "\n-----\n" + prompt
print('-------------prompt_final------------------\n')
print(prompt_final)
# 与LLM交流
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt_final}
]
)
print("User: ", prompt)
print("AI: ", completion.choices[0].message.content)
if __name__ == '__main__':
main()
其中用到的模拟知识库文本:
已知阿根廷在2022年卡塔尔世界杯中获得冠军
已知韩国的DRX战队在2022年获得英雄联盟的S赛冠军
具体步骤:
- 初始化索引
- 获取txt文件中的数据
- 调用openAI的embedding接口生成embedding vectors
- 将embedding vectors保存到pinecone中,同时需要保存元数据
- 将propmt也调用openAI的embedding接口生成embedding vectors
- 去pinecone的索引中去检索,是否有相似的内容
- 将相似内容和prompt重新构造成一份新的prompt_final,丢给GPT
通过这样的方式便可以实现让大模型拥有“记忆”,是不是很简单?