决策树模型、异常检测与主成分分析
之前学习了几种分类的算法:逻辑回归、KNN近邻。这次来看另外一种模型:决策树。决策树是一种对实例进行分类的树形结构,通过多层判断区分目标所属类别。决策树的本质就是通过多层判断,从训练数据集中归纳出一组分类规则。其优点:计算量小,运算速度快;易于理解,可清晰查看各种属性的重要性。但是容易忽略属性间的相关性;样本类别分布不均匀时,容易影响模型表现。
一个简单的例子:根据用户的学习动力、能力提升意愿、兴趣度、空余时间,判断其是否适合学习本门课程。
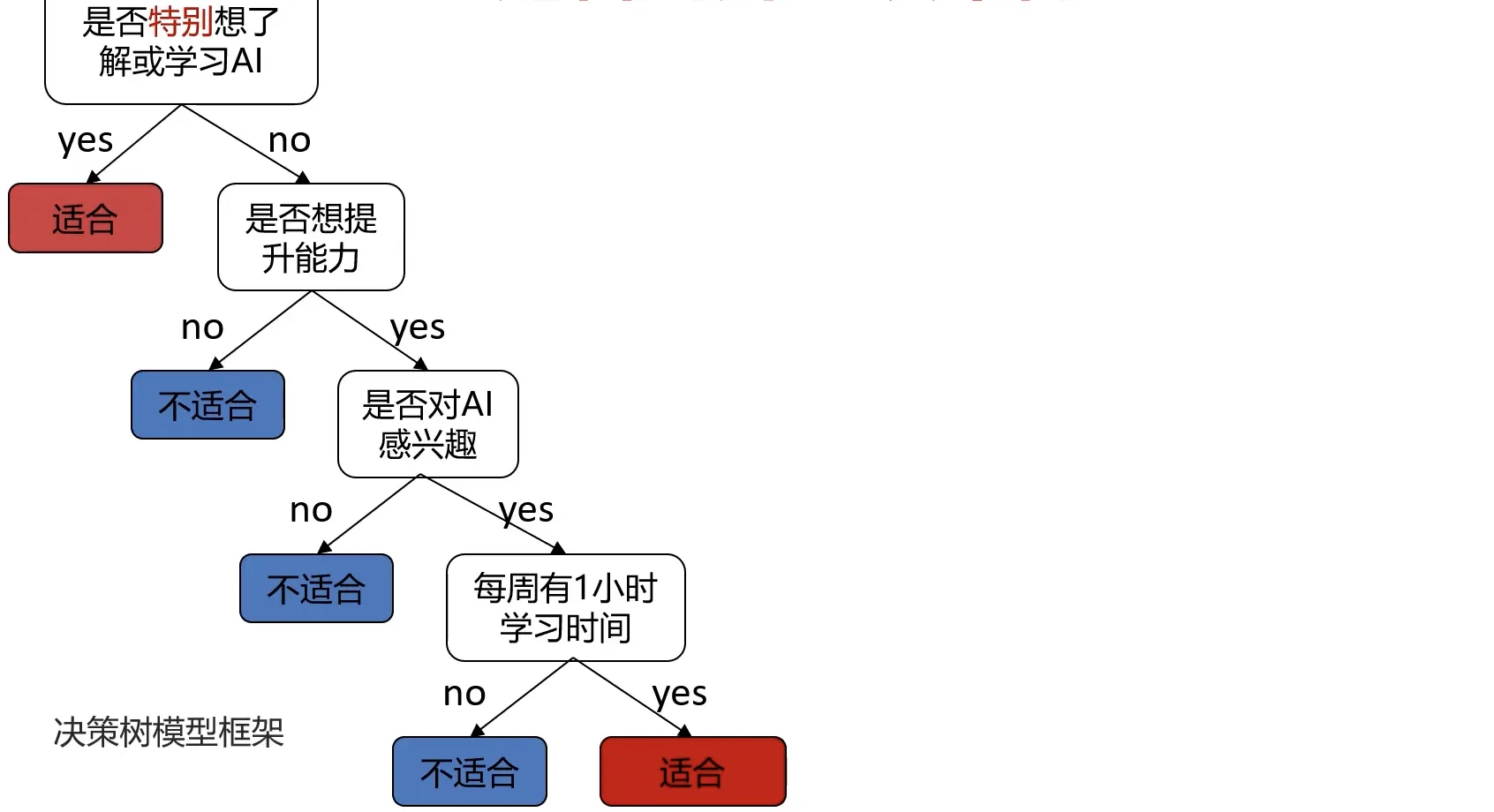
那么问题来了,凭啥“是否特别想了解或学习AI” 是首要判断条件呢?这就涉及到决策树求解的过程了。
决策树(DecisionTree)
假设给定训练数据集 $D={(x_1,y_1),(x_2,y_2),\ldots,(xN,yN)}$ ,其中 $x_i=(x_i^{(1)},x_i^{(2)},\ldots,x_i^{(m)})^T$ 为输入实例,m 为特征个数,$y_i\in{1,2,3,\ldots,K}$ 为类标记,$i = 1,2,……N$, N 为样本容量。
目标:根据训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
问题核心:特征选择,每一个节点选哪一个特征。选择的特征不同,决策树也不同,那么选择哪一个特征的决策树呢?有三种方法:ID3,C4.5,CART(前两者用到了信息增益的概念)
这里不讨论复杂的数学公式推导,简单来看,ID3:利用信息熵原理选择信息增益最大的属性作为分类属性,递归地拓展决策树的分支,完成决策树的构造。
信息熵的定义:是度量随机变量不确定性的指标,熵越大,变量的不确定性越大。假定当前样本集合D中的第k类样本所占比例为 $p_k$ ,则D的信息熵为: $$ Ent(D)=-\sum_{k=1}^{|y|}p_klog_2p_k $$
Ent(D) 的值越小,变量的不确定性越小。$p_k = 1$ 时,$Ent(D)= 0$,$p_k = 0$ 时,$Ent(D)= 0$。因为两种情况都表示另外一种情况为不可能,所以确定性是100%。
根据信息熵,可以计算以属性a进行样本划分带来的信息增益:
$$Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\frac{D^v}DEnt(D^v)$$
V为根据属性 a 划分出的类别数、D为当前样本总数,$D^v$ 为类别V的样本数。
$Ent(D)$ 就是划分之前的信息熵,$\sum_{v=1}^{V}\frac{D^v}DEnt(D^v)$ 就是划分之后的信息熵。
目标: 划分后样本分布不确定性尽可能小,即划分后信息熵小,信息增益大。因为你肯定希望每次划分完毕之后的不确定性逐渐变小的。
以上面的例子来计算一次:
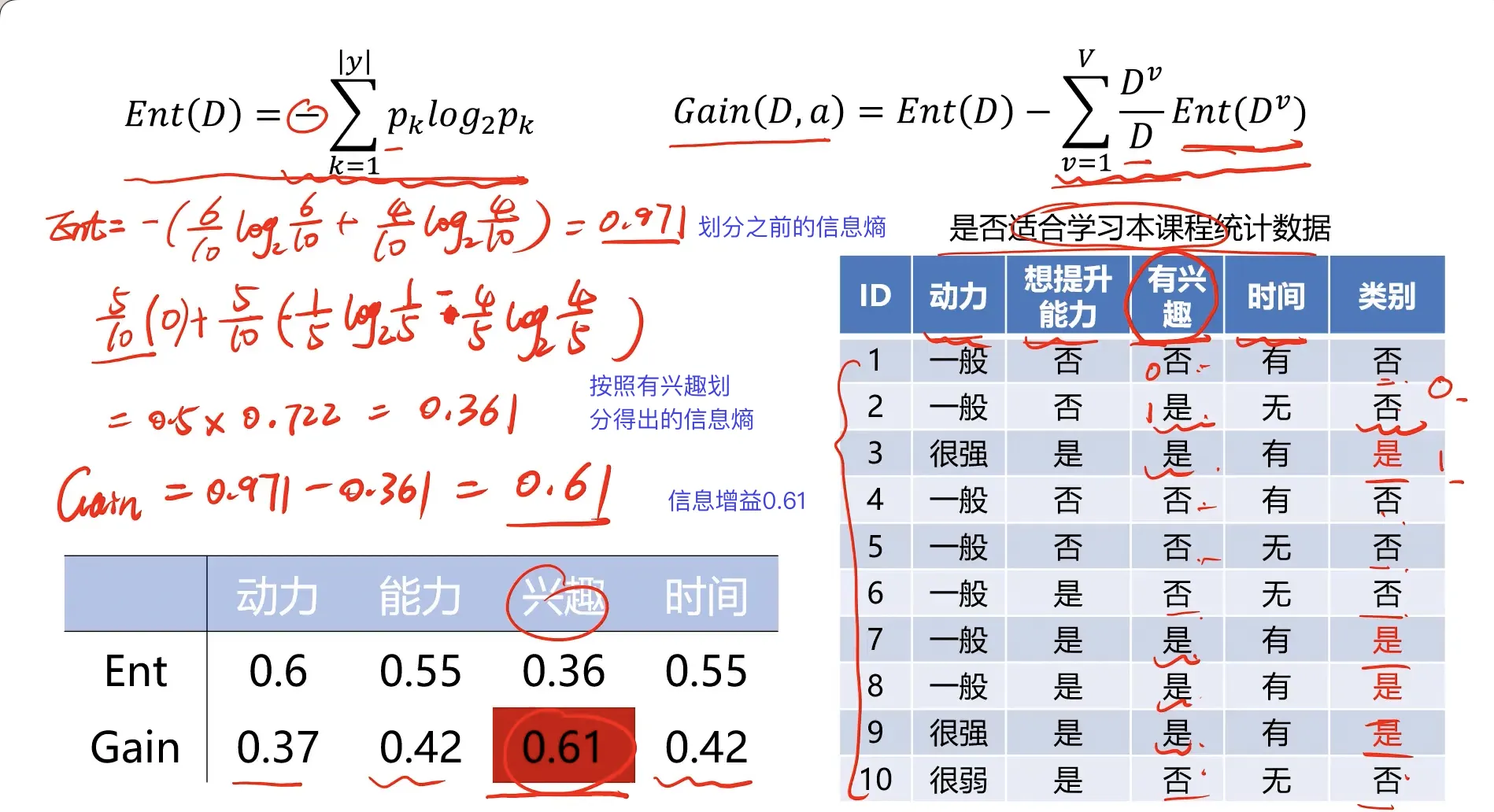
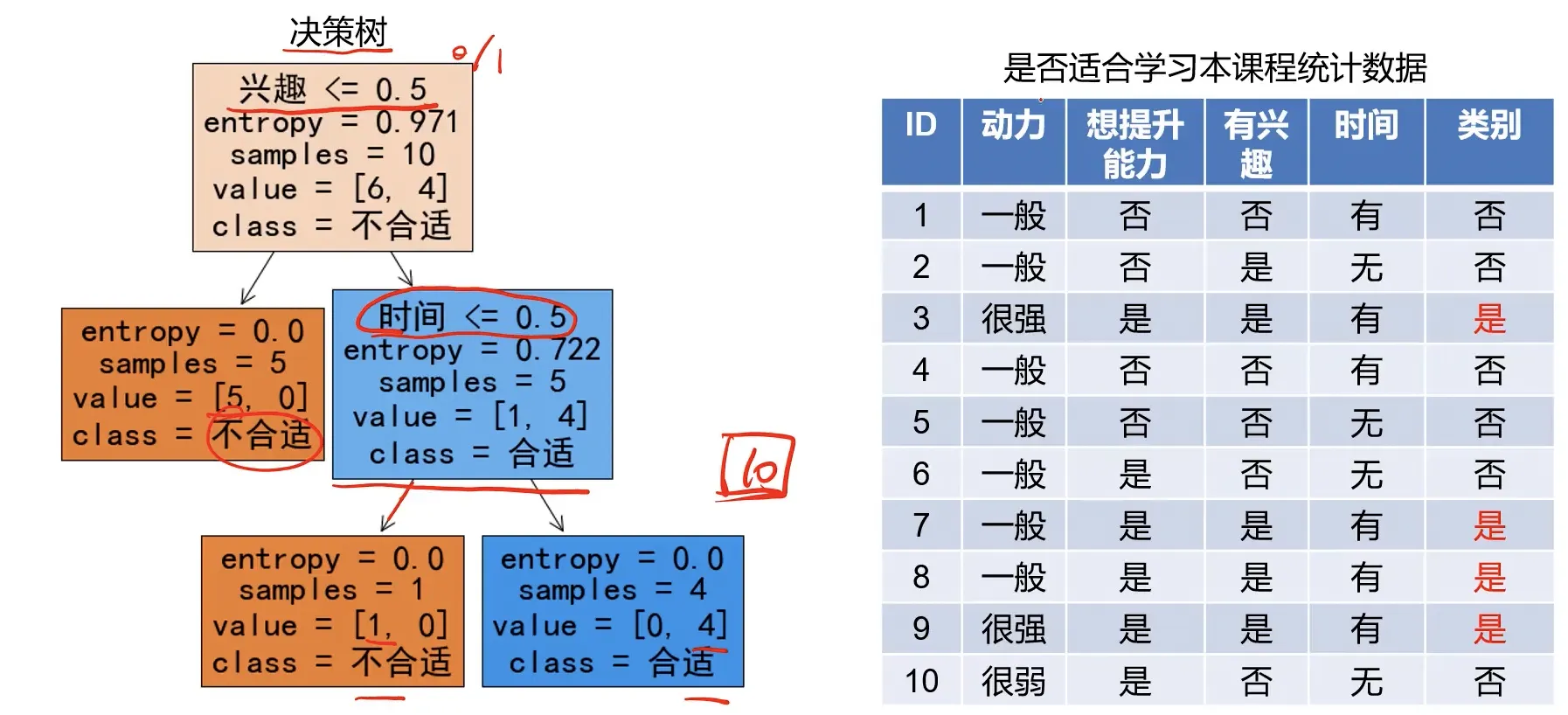
经过计算可以得到如下的决策树:
异常检测(Anomaly Detection)
异常检测其实就是根据输入数据,对不符合预期模式的数据进行识别:

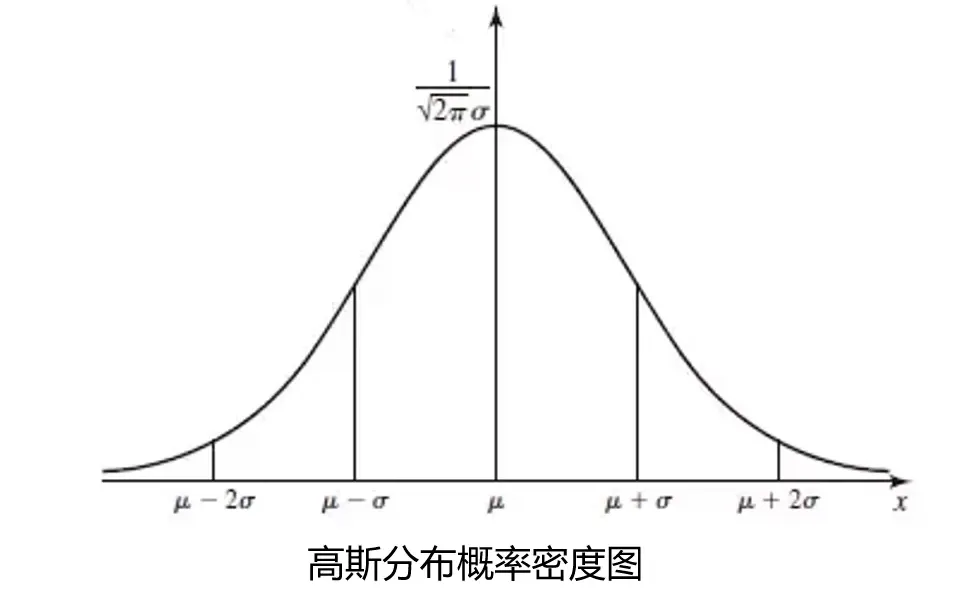
这里我们需要引入一个概率密度的概念:概率密度函数是一个描述随机变量在某个确定的取值点附近为可能性的函数。
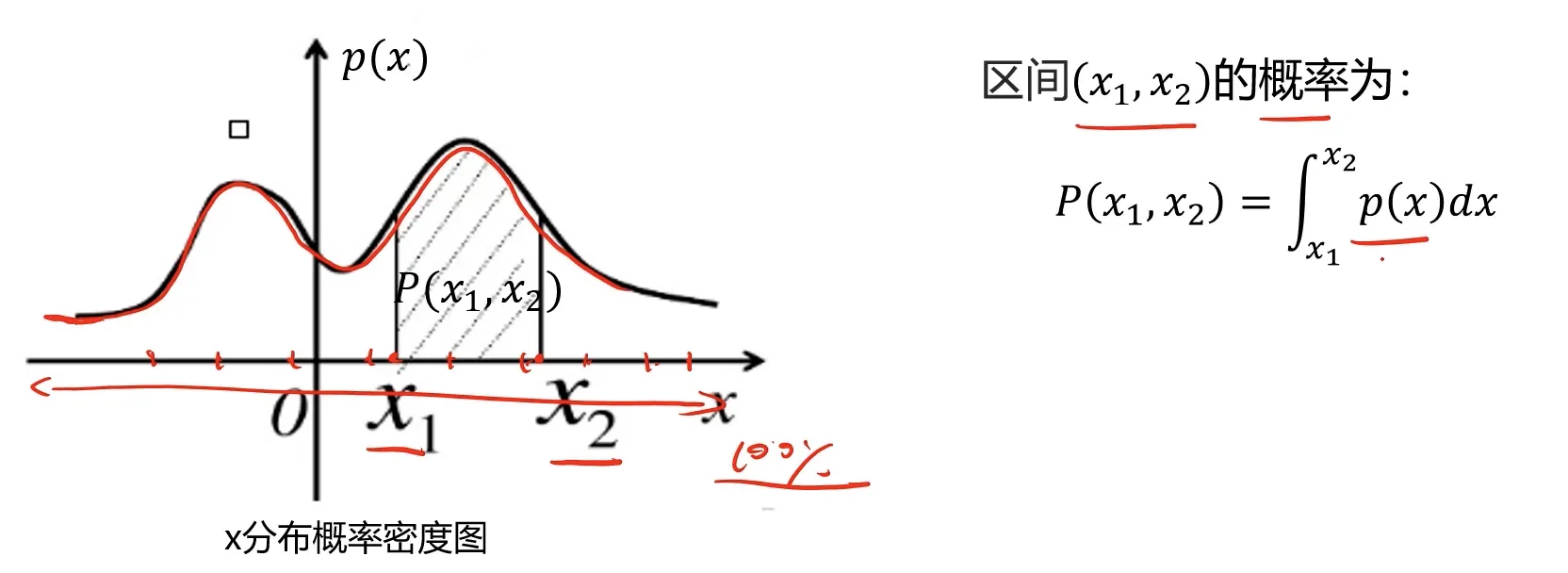
通常情况下,数据的概率密度是符合高斯分布的。高斯分布的概率密度函数是(这些是概率论的基础内容):
$$p(x)=\frac1{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}$$
其中μ为数据均值,σ为标准差:
$$\begin{gathered}\mu=\frac1m\sum_{i=1}^{m}x^{(i)},\\sigma^2=\frac1m\sum_{i=1}^{m}(x^{(i)}-\mu)^2\end{gathered}$$
一维数据基于高斯分布实现异常检测:
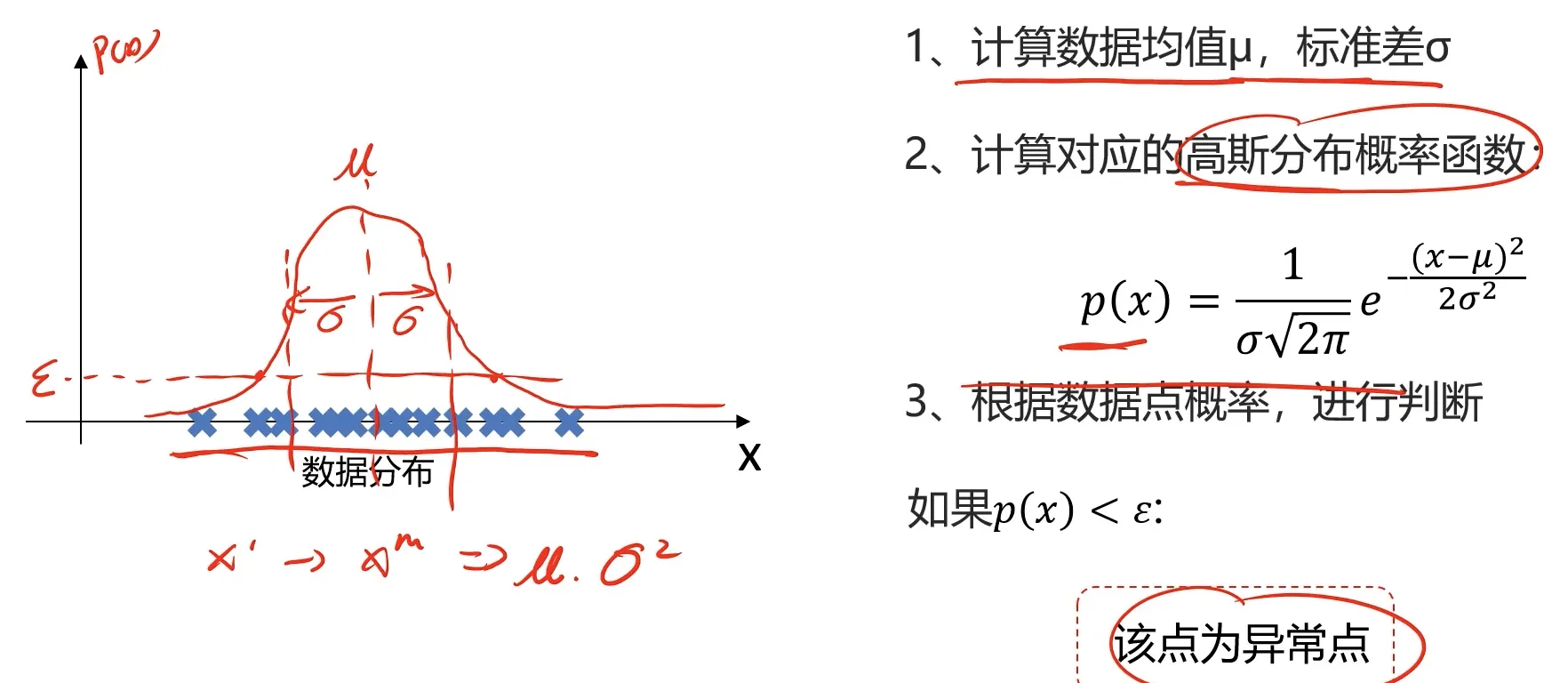
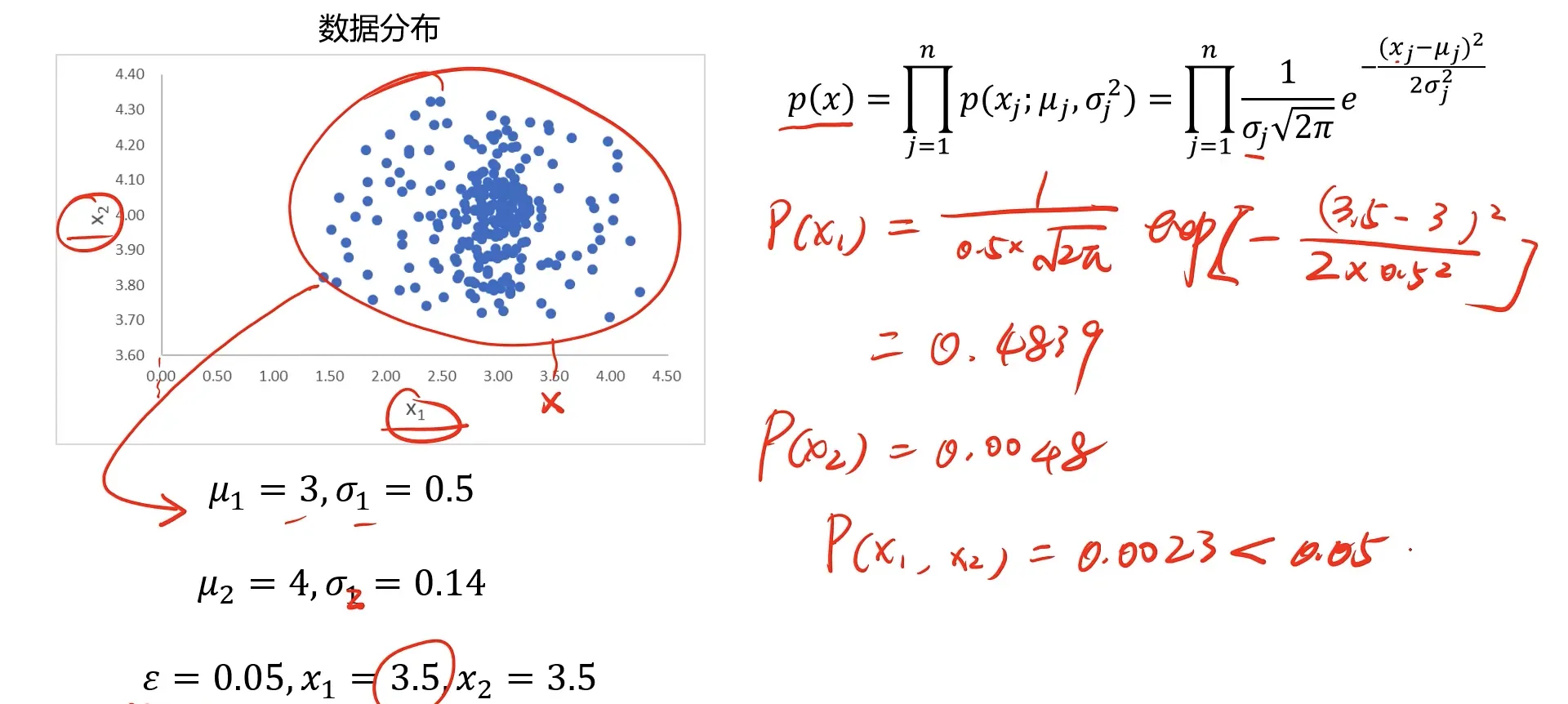
N维数据基于高斯分布实现异常检测:
$$\begin{Bmatrix}{x_1^{(1)},x_1^{(2)},…x_1^{(m)}}_{…}\\…\\x_n^{(1)},x_n^{(2)},…x_n^{(m)}\end{Bmatrix}$$
对于N维的情况我们可以先计算每一个维度下的均值和标准差:
$$\mu_j=\frac1m\sum_{i=1}^mx_j^{(i)},\quad\quad\sigma_j^2=\frac1m\sum_{i=1}^m(x_j^{(i)}-\mu_j)^2$$
然后得出对应维度下的概率密度函数,再把每个维度下的概率密度函数相乘。
$$\begin{aligned}{p(x)}&=\prod_{j=1}^np(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sigma_j\sqrt{2\pi}}e^{-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}}\end{aligned}$$
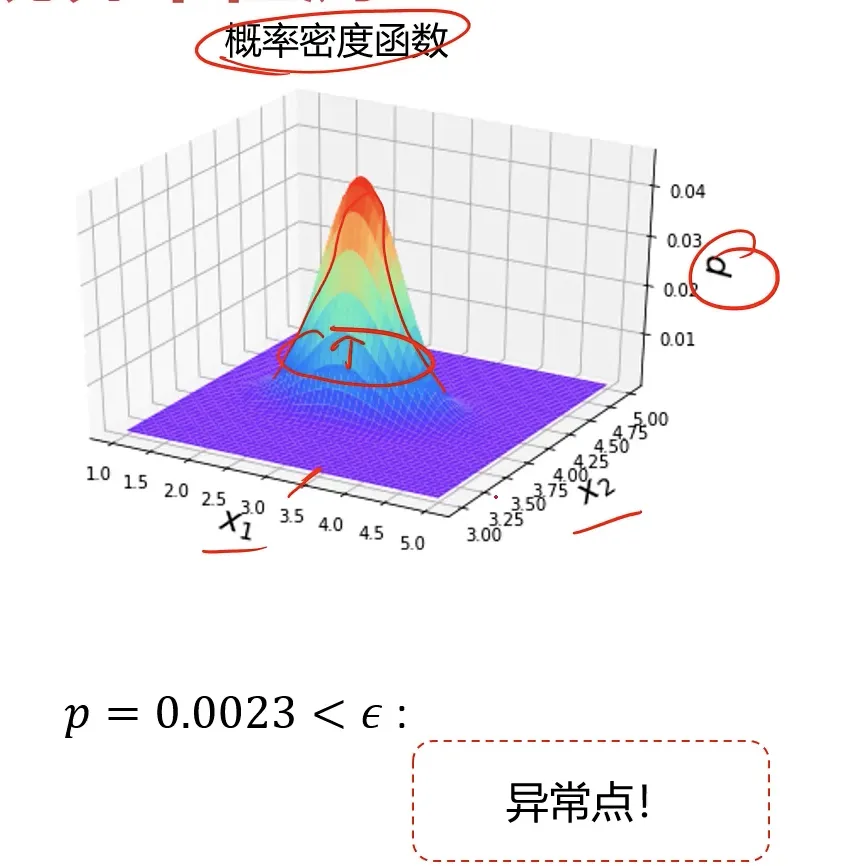
通过可视化的方式看起来是这样:
主成分分析(PCA-Principal component analysis)
有一个数据降维的真实案例: 通过美国1929-1938年各年经济数据,预测国民收入与支出。数据包括:雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息、外贸平衡等十七个指标。一个叫做斯通(Stone)的统计学家提出了一个方法:主成分分析。将17个指标的模型降到了3个指标(这里三个指标并不是初始的三个指标),预测准确率达到97%。
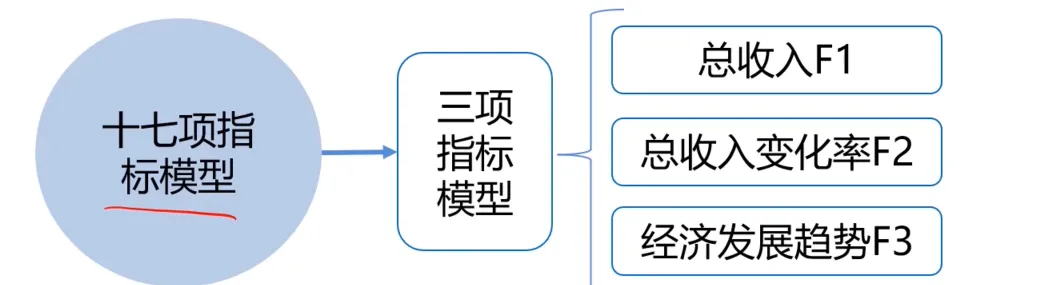
数据降维,是指在某些限定条件下降低随机变量个数得到一组“不相关”主变量的过程。
作用:1、减少模型分析数据量,提升处理效率,降低计算难度2、实现数据可视化。
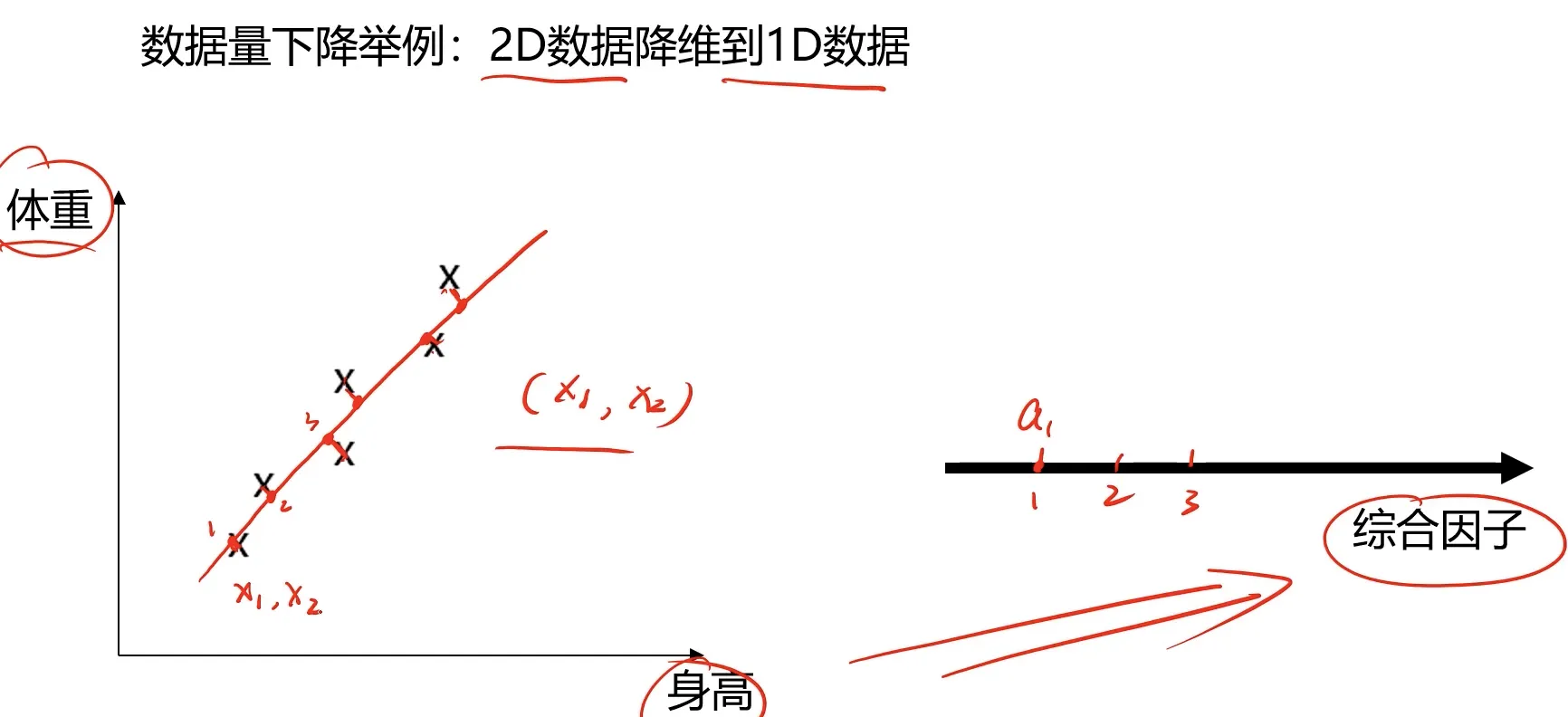
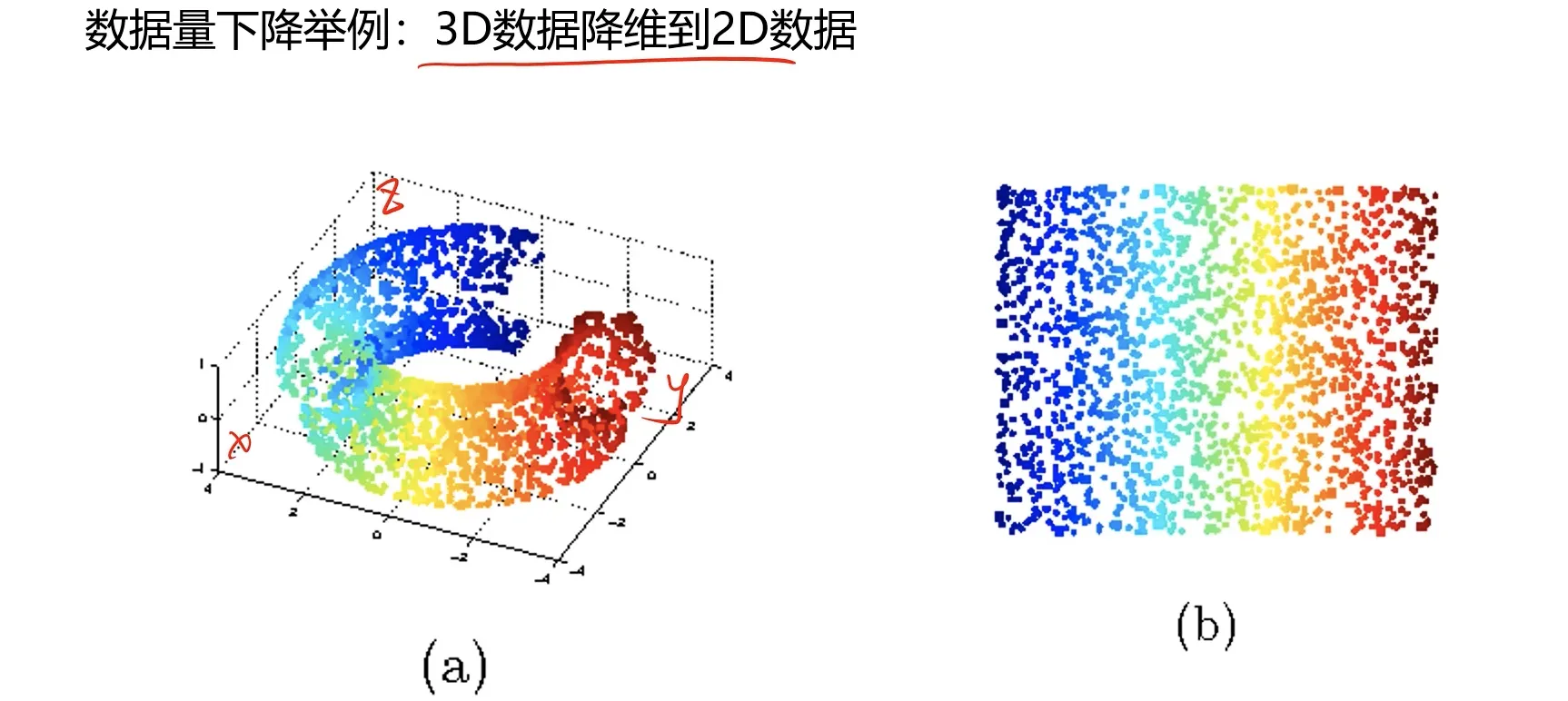
主成分分析(PCA)作为数据降维的实现,也是应用最多的方法,其目标就是寻找k(k<n)维新数据,使他们反应事物的主要特征。
核心:在信息损失尽可能少的情况下,降低数据维度
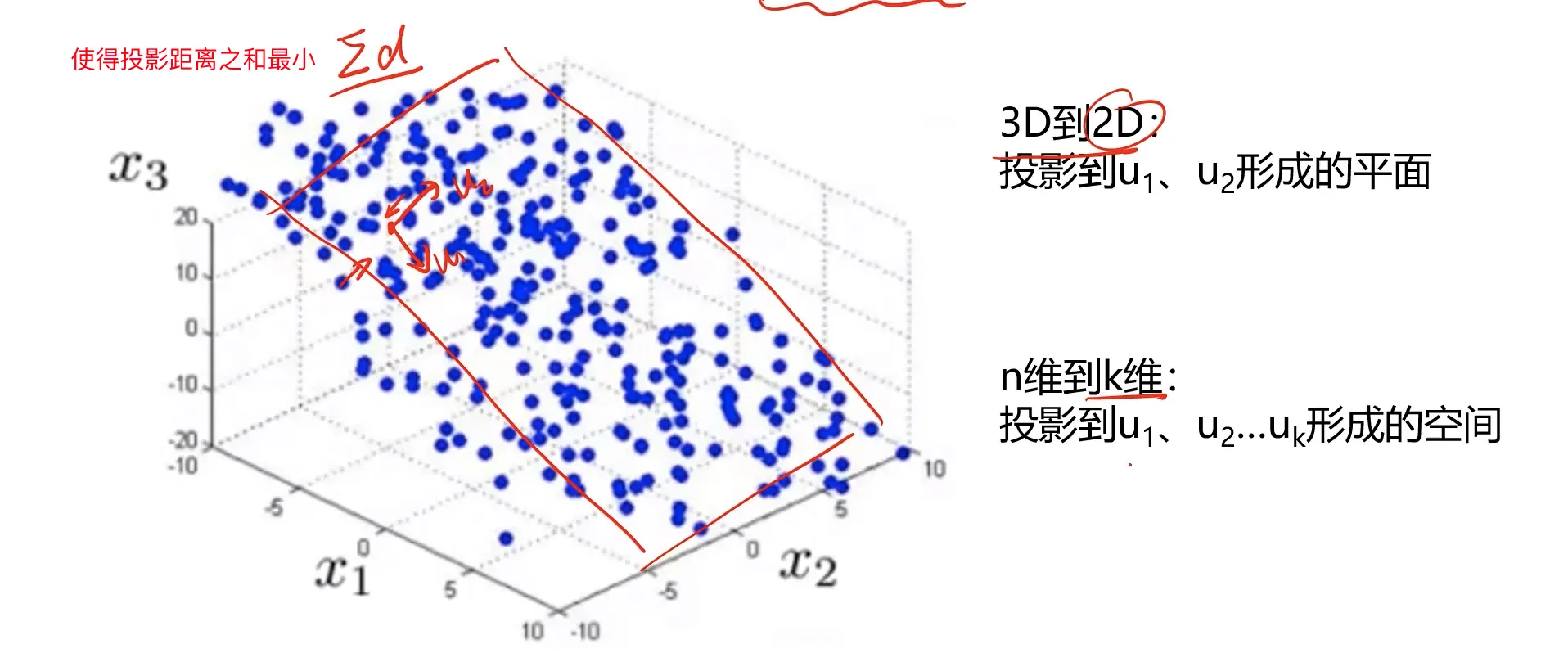
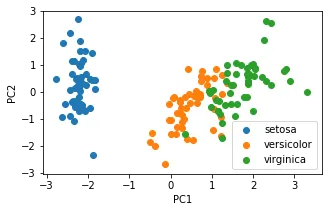
如何保留主要信息:投影后的不同特征数据尽可能分得开(即不相关)
如何实现:使投影后数据的方差最大,因为方差越大数据也越分散
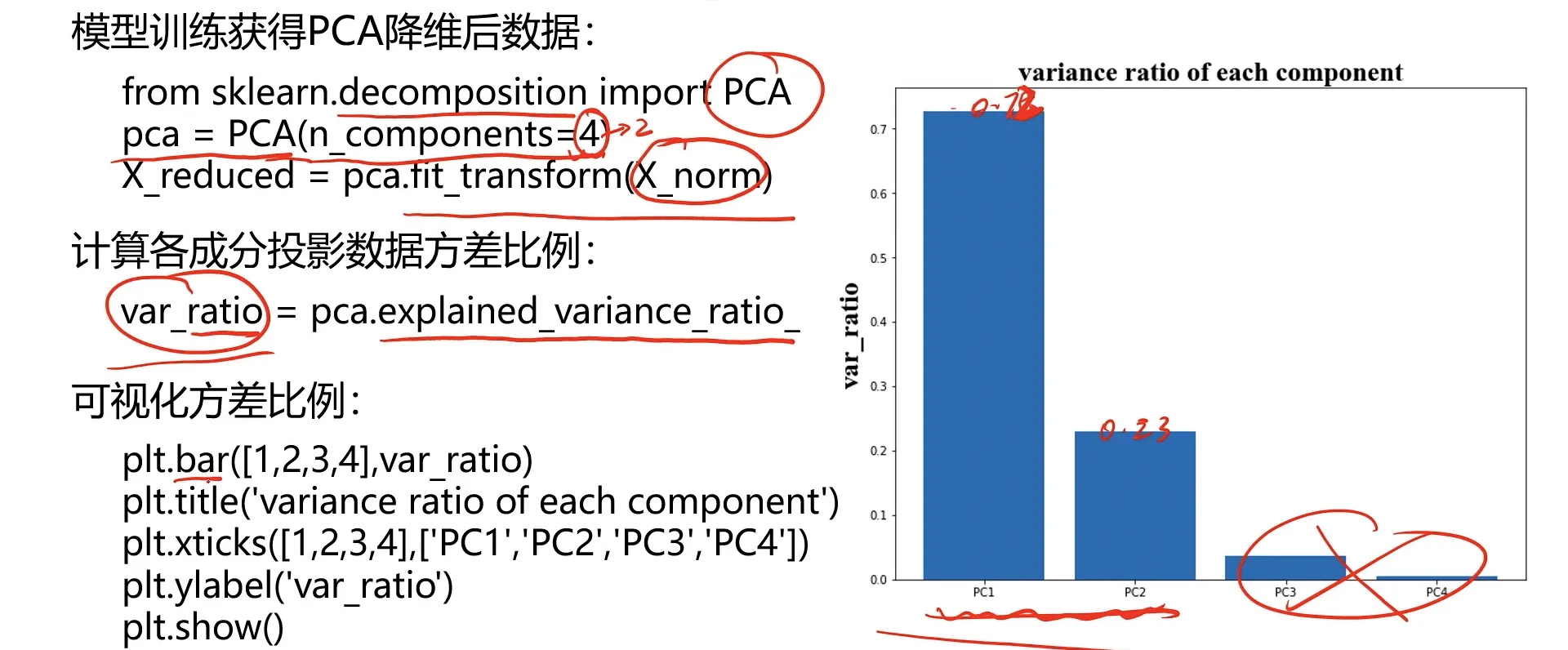
计算过程:
- 1、原始数据预处理(标准化:μ=0, σ=1)
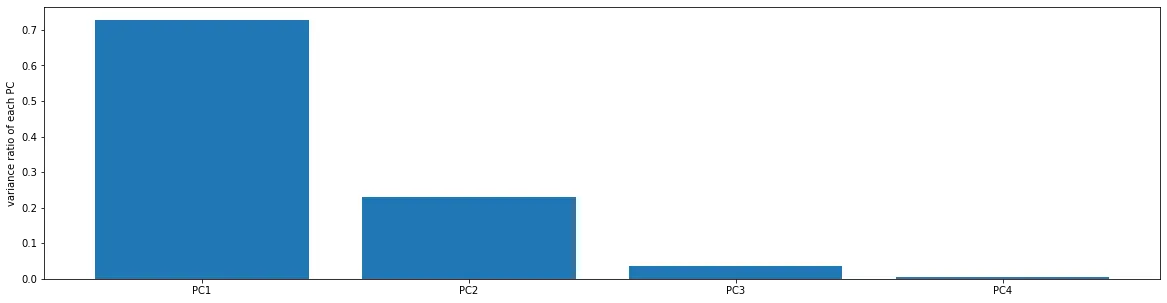
- 2、计算协方差矩阵特征向量,及数据在各特征向量投影后的方差
- 3、根据需求(任务指定或方差比例)确定降维维度k
- 4、选取k维特征向量,计算数据在其形成空间的投影
决策树案例实战
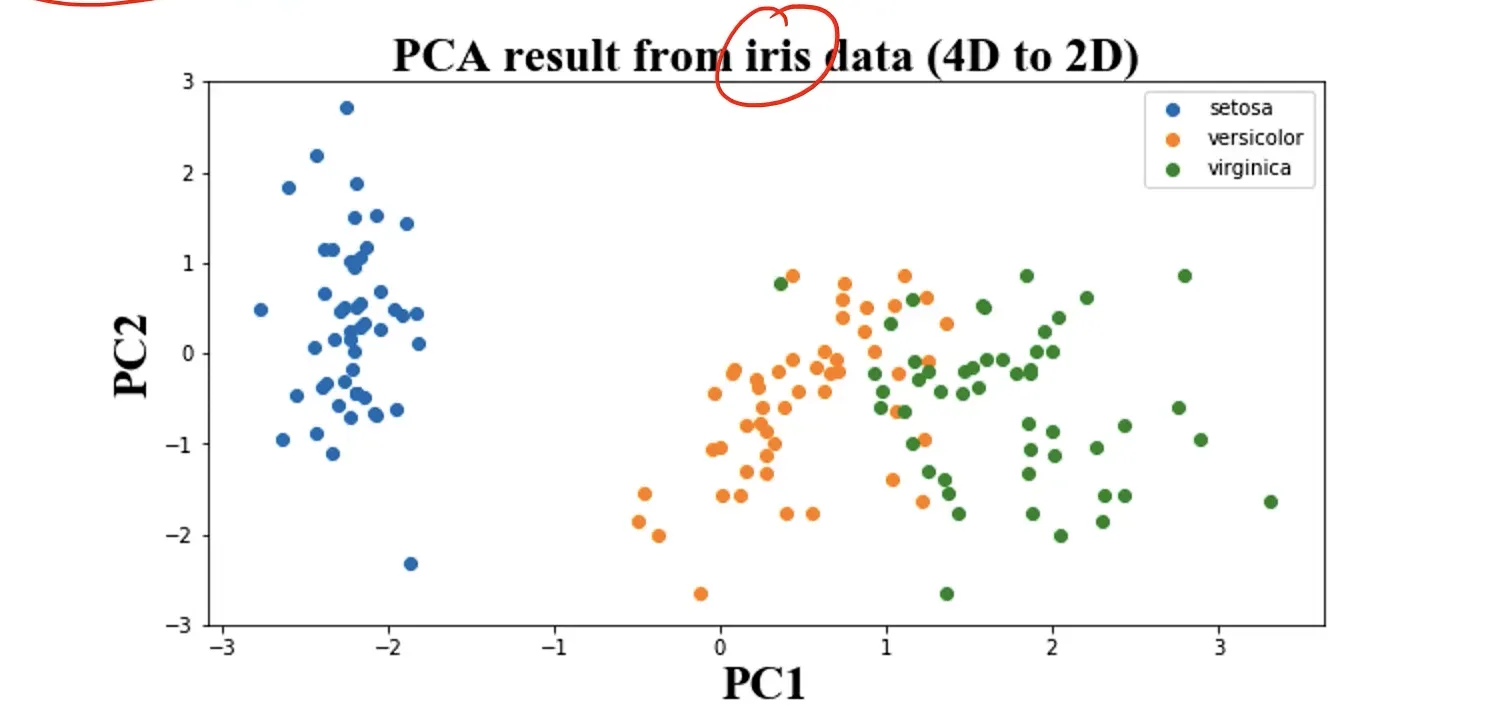
lIris数据集:lris 尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。作为机器学习经典数据集:简单而具有代表性,常用于监督式学习应用。

3共150条记录,每类各 50个数据。每条记录都有4项特:征花萼长度(Sepal Length)、花萼宽度(Sepal Width)、花瓣长度(Petal Length)、花瓣宽度(Petal Width)。
目标呢就是通过4个特征预测花卉属于三类 (iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。

决策树实战task:
1、基于iris_data.csv数据,建立决策树模型,评估模型表现
2、可视化决策树结构
3、修改min_samples_leaf参数,对比模型结果
import pandas as pd
import numpy as np
data = pd.read_csv('iris_data.csv')
data.head()
| sepal length | sepal width | petal length | petal width | target | label | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa | 0 |
#define the X and y
X = data.drop(['target', 'label'],axis=1)
y = data.loc[:, 'label']
print(X.shape, y.shape)
(150, 4) (150,)
#建立决策树模型
from sklearn import tree
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=5)
dc_tree.fit(X,y)
| DecisionTreeClassifier(criterion='entropy', min_samples_leaf=5) |
|---|
#评估模型表现
y_predict = dc_tree.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)
print(accuracy)
0.9733333333333334
# 可视化展示
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(10,10))
#tree.plot_tree(dc_tree)
# 加上分类名称
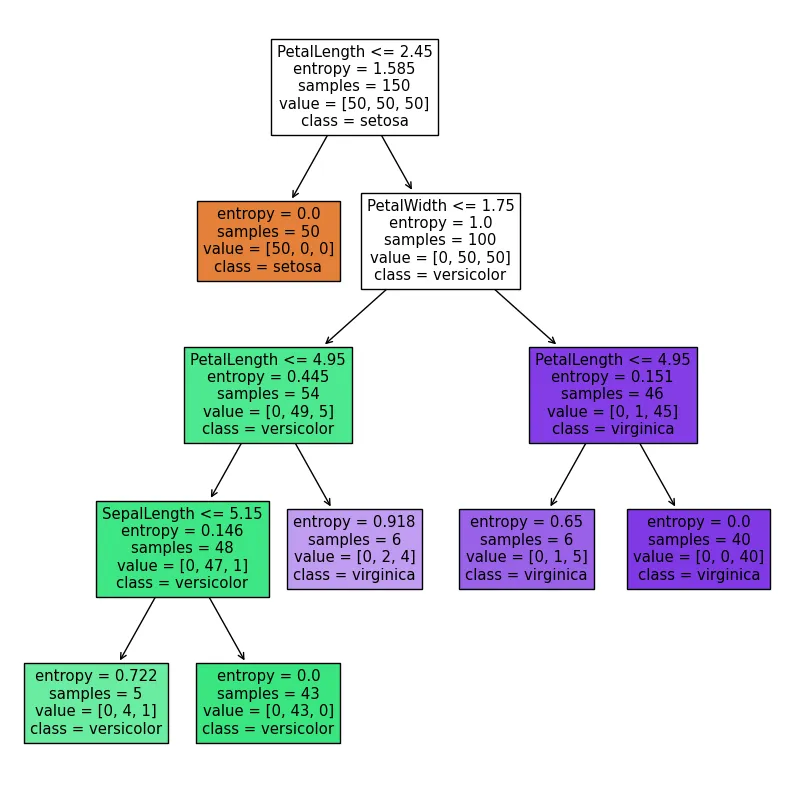
tree.plot_tree(dc_tree,filled=True,feature_names=['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth'],class_names=['setosa','versicolor','virginica'])
[Text(0.4444444444444444, 0.9, 'PetalLength <= 2.45\nentropy = 1.585\nsamples = 150\nvalue = [50, 50, 50]\nclass = setosa'),
Text(0.3333333333333333, 0.7, 'entropy = 0.0\nsamples = 50\nvalue = [50, 0, 0]\nclass = setosa'),
Text(0.5555555555555556, 0.7, 'PetalWidth <= 1.75\nentropy = 1.0\nsamples = 100\nvalue = [0, 50, 50]\nclass = versicolor'),
Text(0.3333333333333333, 0.5, 'PetalLength <= 4.95\nentropy = 0.445\nsamples = 54\nvalue = [0, 49, 5]\nclass = versicolor'),
Text(0.2222222222222222, 0.3, 'SepalLength <= 5.15\nentropy = 0.146\nsamples = 48\nvalue = [0, 47, 1]\nclass = versicolor'),
Text(0.1111111111111111, 0.1, 'entropy = 0.722\nsamples = 5\nvalue = [0, 4, 1]\nclass = versicolor'),
Text(0.3333333333333333, 0.1, 'entropy = 0.0\nsamples = 43\nvalue = [0, 43, 0]\nclass = versicolor'),
Text(0.4444444444444444, 0.3, 'entropy = 0.918\nsamples = 6\nvalue = [0, 2, 4]\nclass = virginica'),
Text(0.7777777777777778, 0.5, 'PetalLength <= 4.95\nentropy = 0.151\nsamples = 46\nvalue = [0, 1, 45]\nclass = virginica'),
Text(0.6666666666666666, 0.3, 'entropy = 0.65\nsamples = 6\nvalue = [0, 1, 5]\nclass = virginica'),
Text(0.8888888888888888, 0.3, 'entropy = 0.0\nsamples = 40\nvalue = [0, 0, 40]\nclass = virginica')]
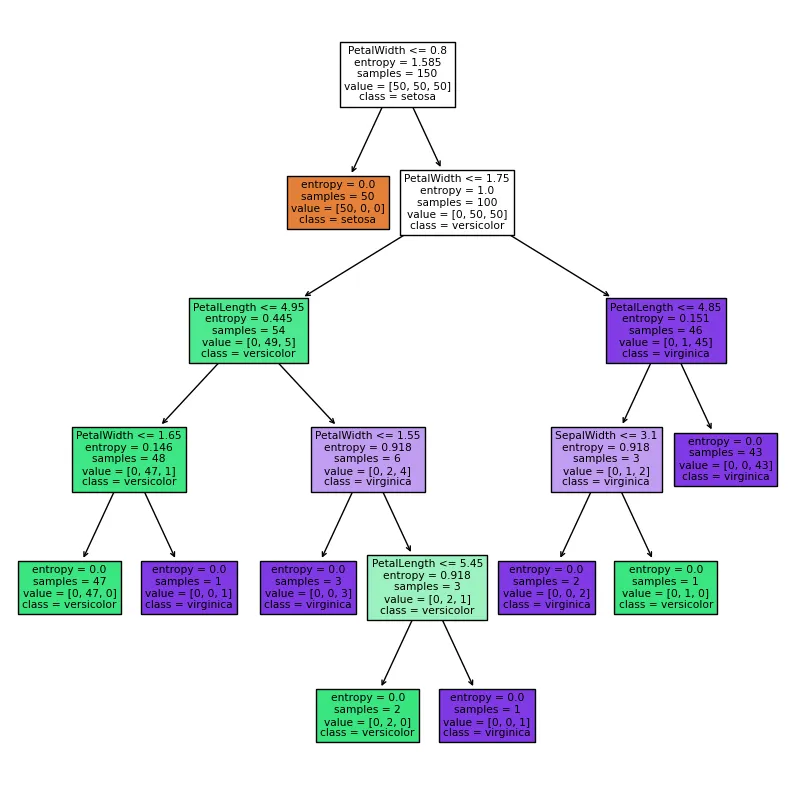
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=1)
dc_tree.fit(X,y)
fig2 = plt.figure(figsize=(10,10))
# 加上分类名称
tree.plot_tree(dc_tree,filled=True,feature_names=['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth'],class_names=['setosa','versicolor','virginica'])
[Text(0.5, 0.9166666666666666, 'PetalWidth <= 0.8\nentropy = 1.585\nsamples = 150\nvalue = [50, 50, 50]\nclass = setosa'),
Text(0.4230769230769231, 0.75, 'entropy = 0.0\nsamples = 50\nvalue = [50, 0, 0]\nclass = setosa'),
Text(0.5769230769230769, 0.75, 'PetalWidth <= 1.75\nentropy = 1.0\nsamples = 100\nvalue = [0, 50, 50]\nclass = versicolor'),
Text(0.3076923076923077, 0.5833333333333334, 'PetalLength <= 4.95\nentropy = 0.445\nsamples = 54\nvalue = [0, 49, 5]\nclass = versicolor'),
Text(0.15384615384615385, 0.4166666666666667, 'PetalWidth <= 1.65\nentropy = 0.146\nsamples = 48\nvalue = [0, 47, 1]\nclass = versicolor'),
Text(0.07692307692307693, 0.25, 'entropy = 0.0\nsamples = 47\nvalue = [0, 47, 0]\nclass = versicolor'),
Text(0.23076923076923078, 0.25, 'entropy = 0.0\nsamples = 1\nvalue = [0, 0, 1]\nclass = virginica'),
Text(0.46153846153846156, 0.4166666666666667, 'PetalWidth <= 1.55\nentropy = 0.918\nsamples = 6\nvalue = [0, 2, 4]\nclass = virginica'),
Text(0.38461538461538464, 0.25, 'entropy = 0.0\nsamples = 3\nvalue = [0, 0, 3]\nclass = virginica'),
Text(0.5384615384615384, 0.25, 'PetalLength <= 5.45\nentropy = 0.918\nsamples = 3\nvalue = [0, 2, 1]\nclass = versicolor'),
Text(0.46153846153846156, 0.08333333333333333, 'entropy = 0.0\nsamples = 2\nvalue = [0, 2, 0]\nclass = versicolor'),
Text(0.6153846153846154, 0.08333333333333333, 'entropy = 0.0\nsamples = 1\nvalue = [0, 0, 1]\nclass = virginica'),
Text(0.8461538461538461, 0.5833333333333334, 'PetalLength <= 4.85\nentropy = 0.151\nsamples = 46\nvalue = [0, 1, 45]\nclass = virginica'),
Text(0.7692307692307693, 0.4166666666666667, 'SepalWidth <= 3.1\nentropy = 0.918\nsamples = 3\nvalue = [0, 1, 2]\nclass = virginica'),
Text(0.6923076923076923, 0.25, 'entropy = 0.0\nsamples = 2\nvalue = [0, 0, 2]\nclass = virginica'),
Text(0.8461538461538461, 0.25, 'entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]\nclass = versicolor'),
Text(0.9230769230769231, 0.4166666666666667, 'entropy = 0.0\nsamples = 43\nvalue = [0, 0, 43]\nclass = virginica')]
异常检测实战
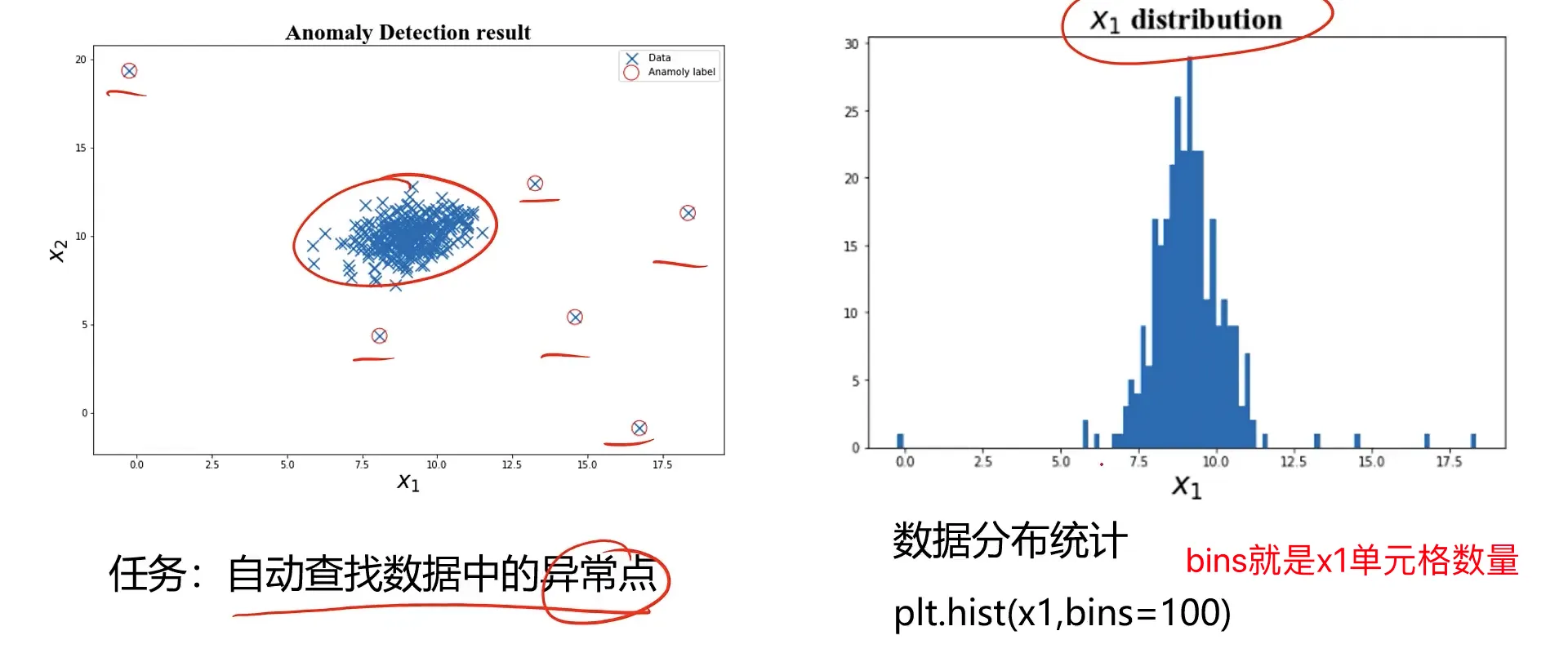
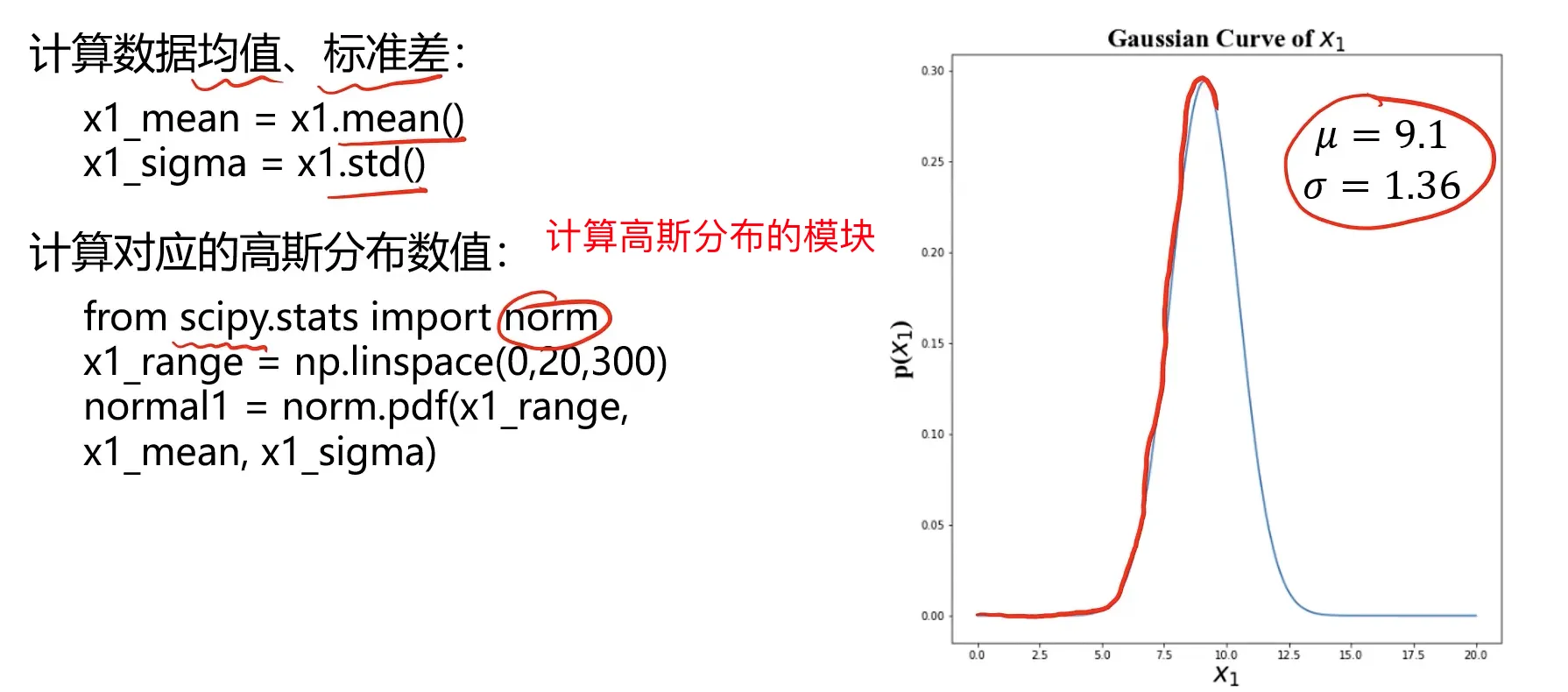
异常检测实战task:
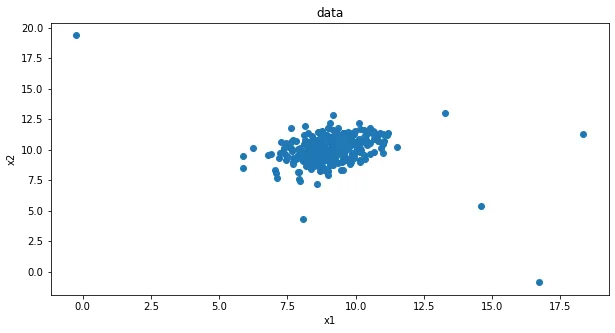
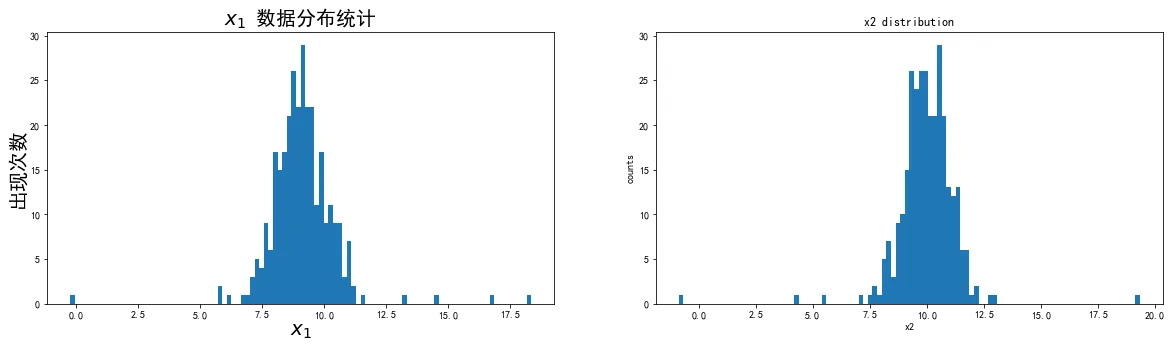
1、基于 anomaly_data.csv数据,可视化数据分布情况、及其对应高斯分布的概率密度函数
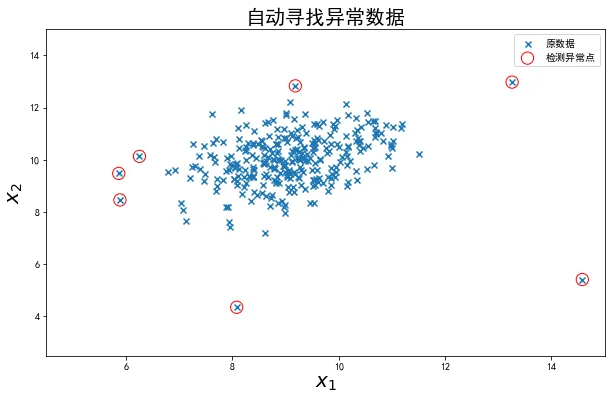
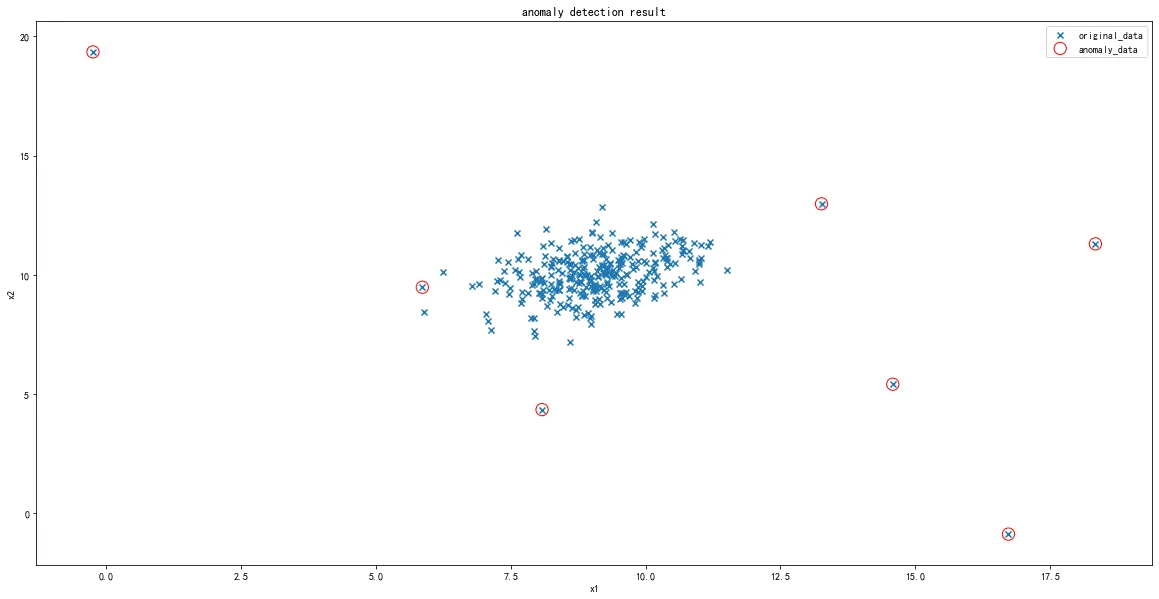
2、建立模型,实现异常数据点预测
3、可视化异常检测处理结果
4、修改概率分布阈值EllipticEnvelope(contamination=0.1)中的contamination,查看阈值改变对结果的影响
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('anomaly_data.csv')
data.head()
| x1 | x2 | |
|---|---|---|
| 0 | 8.046815 | 9.741152 |
| 1 | 8.408520 | 8.763270 |
| 2 | 9.195915 | 10.853181 |
| 3 | 9.914701 | 11.174260 |
| 4 | 8.576700 | 9.042849 |