逻辑回归案例实战
当我们要解决一个分类问题,尤其是一个二分类问题时,如果我们用线性回归去解决就会面临这样一个问题:样本量变大后,准确率会下降。这时为了更好地解决这种分类问题,我们就需要采用逻辑回归的方法了。现在有两个逻辑回归的实战案例:考试通过预测、芯片检测通过预测。同样本次练习也是基于sk-learn库, 通过逻辑回归实现二分类。
一、考试通过预测
首先看第一个目标:基于数据集建立逻辑回归模型,并预测给定两门分数的情况下,预测第三门分数是否能通过;建立二阶边界,提高模型的准确率。
下面的内容基本就是Jupyter NoteBook的内容了:
1.基于testdata.csv数据,建立逻辑回归模型,评估模型的表现。
2.预测Exam1 = 75,Exam2 = 60 时,该同学能否通过 Exam3。
3.建立二阶边界函数,重复任务1,2步骤。
#load from csv
import pandas as pd
import numpy as np
data = pd.read_csv('examdata.csv')
data.head()
| Exam1 | Exam2 | Pass | |
|---|---|---|---|
| 0 | 34.623660 | 78.024693 | 0 |
| 1 | 30.286711 | 43.894998 | 0 |
| 2 | 35.847409 | 72.902198 | 0 |
| 3 | 60.182599 | 86.308552 | 1 |
| 4 | 79.032736 | 75.344376 | 1 |
#visual the data 可视化数据
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(data.loc[:, 'Exam1'], data.loc[:, 'Exam2'])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()
# add lable mask
mask = data.loc[:, 'Pass'] == 1
print(~mask)
0 True
1 True
2 True
3 False
4 False
...
95 False
96 False
97 False
98 False
99 False
Name: Pass, Length: 100, dtype: bool
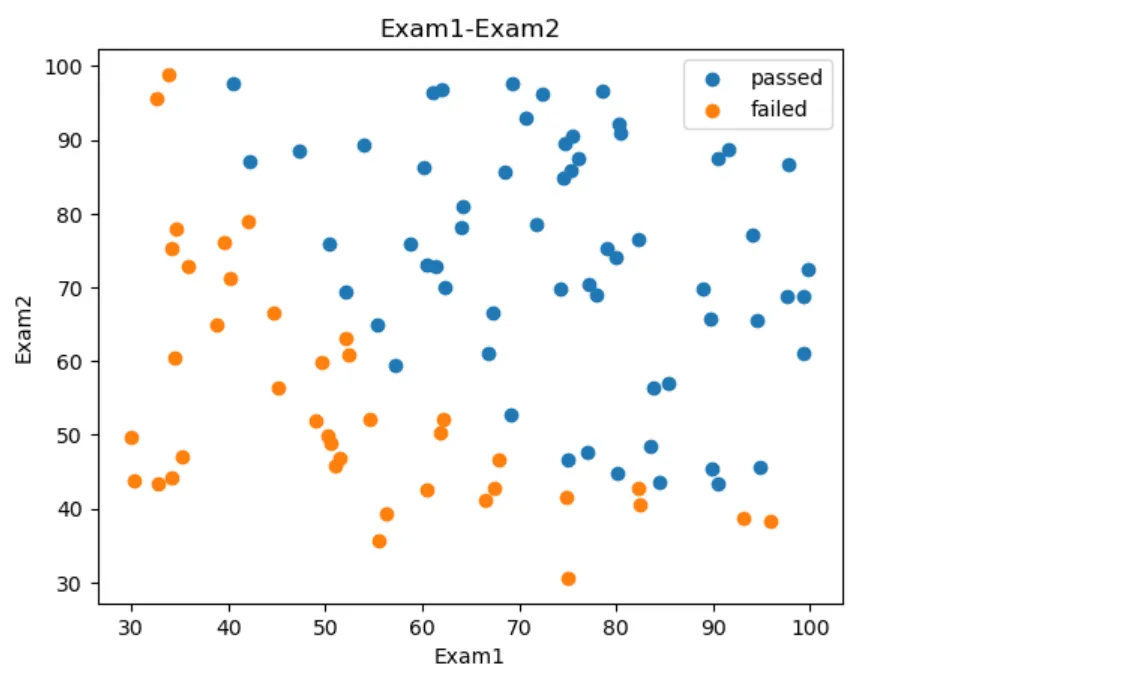
#visual the data with mask 添加标签
fig2 = plt.figure()
passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed, failed), ('passed', 'failed'))
plt.show()
#define X,y 对变量进行数据赋值
X = data.drop(['Pass'], axis=1)
X.head()
X1 = data.loc[:, 'Exam1']
X2 = data.loc[:, 'Exam2']
X2.head()
y = data.loc[:, 'Pass']
y.head()
0 0
1 0
2 0
3 1
4 1
Name: Pass, dtype: int64
print(X.shape, y.shape)
(100, 2) (100,)
#establish the model and train it 建立并训练模型
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(X,y)
LogisticRegression()
# show the pridict result and its accuracy
y_predict = LR.predict(X)
print(y_predict)
[0 0 0 1 1 0 1 0 1 1 1 0 1 1 0 1 0 0 1 1 0 1 0 0 1 1 1 1 0 0 1 1 0 0 0 0 1
1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 0 0 0 0 0 1 0 1 1 0 1 1 1
1 1 1 1 0 1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 1 1 1 1 0 1]
from sklearn.metrics import accuracy_score
accRet = accuracy_score(y, y_predict)
print(accRet)
0.89
#exam1 = 70 exam2 = 65
y_test = LR.predict([[75,65]])
print('passed' if y_test == 1 else 'failed')
passed
/home/changlin/anaconda3/envs/sk_env/lib/python3.7/site-packages/sklearn/base.py:451: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
"X does not have valid feature names, but"
LR.coef_
array([[0.20535491, 0.2005838 ]])
LR.intercept_
array([-25.05219314])
theta0 = LR.intercept_
theta1,theta2 = LR.coef_[0][0], LR.coef_[0][1]
print(theta0, theta1, theta2)
[-25.05219314] 0.20535491217790364 0.20058380395469022
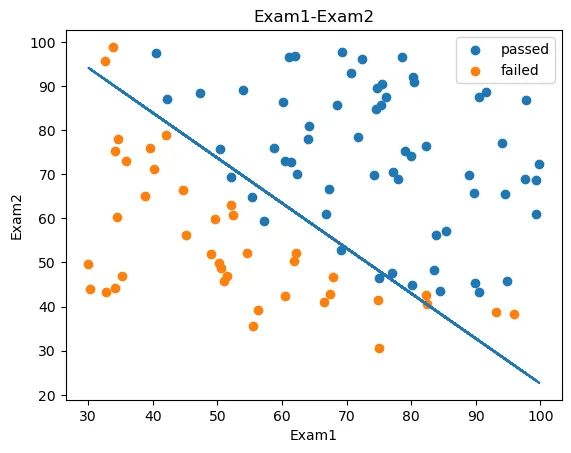
X2_new = -(theta0 + theta1 * X1)/theta2
print(X2_new)
fig3 = plt.figure()
passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed, failed), ('passed', 'failed'))
plt.plot(X1, X2_new)
plt.show()
0 89.449169
1 93.889277
2 88.196312
3 63.282281
4 43.983773
...
95 39.421346
96 81.629448
97 23.219064
98 68.240049
99 48.341870
Name: Exam1, Length: 100, dtype: float64
得到一阶边界模型
下面开始建立二阶边界模型
二阶边界函数: $$ \mathrm{\theta_0~+\theta_1x_1~+\theta_2x_2~+\theta_3x_1^2~+\theta_4x_2^2~+\theta_5x_1x_2~=0} $$
# 创建新的数据集
X1_2 = X1 * X1
X2_2 = X2 * X2
X1_X2 = X1 * X2
print(X1_2, X2_2, X1_X2)
0 1198.797805
1 917.284849
2 1285.036716
3 3621.945269
4 6246.173368
...
95 6970.440295
96 1786.051355
97 9863.470975
98 3062.517544
99 5591.434174
Name: Exam1, Length: 100, dtype: float64 0 6087.852690
1 1926.770807
2 5314.730478
3 7449.166166
4 5676.775061
...
95 2340.652054
96 7587.080849
97 4730.056948
98 4216.156574
99 8015.587398
Name: Exam2, Length: 100, dtype: float64 0 2701.500406
1 1329.435094
2 2613.354893
3 5194.273015
4 5954.672216
...
95 4039.229555
96 3681.156888
97 6830.430397
98 3593.334590
99 6694.671710
Length: 100, dtype: float64
X_new = {'X1':X1, 'X2':X2, 'X1_2': X1_2, 'X2_2':X2_2, 'X1_X2':X1_X2}
X_new = pd.DataFrame(X_new)
print(X_new)
X1 X2 X1_2 X2_2 X1_X2
0 34.623660 78.024693 1198.797805 6087.852690 2701.500406
1 30.286711 43.894998 917.284849 1926.770807 1329.435094
2 35.847409 72.902198 1285.036716 5314.730478 2613.354893
3 60.182599 86.308552 3621.945269 7449.166166 5194.273015
4 79.032736 75.344376 6246.173368 5676.775061 5954.672216
.. ... ... ... ... ...
95 83.489163 48.380286 6970.440295 2340.652054 4039.229555
96 42.261701 87.103851 1786.051355 7587.080849 3681.156888
97 99.315009 68.775409 9863.470975 4730.056948 6830.430397
98 55.340018 64.931938 3062.517544 4216.156574 3593.334590
99 74.775893 89.529813 5591.434174 8015.587398 6694.671710
[100 rows x 5 columns]
# create new model and train
LR2 = LogisticRegression()
LR2.fit(X_new, y)
LogisticRegression()
# show the pridict result and its accuracy
y2_predict = LR2.predict(X_new)
print(y2_predict)
[0 0 0 1 1 0 1 1 1 1 0 0 1 1 0 1 1 0 1 1 0 1 0 0 1 1 1 0 0 0 1 1 0 1 0 0 0
1 0 0 1 0 1 0 0 0 1 1 1 1 1 1 1 0 0 0 1 0 1 1 1 0 0 0 0 0 1 0 1 1 0 1 1 1
1 1 1 1 0 0 1 1 1 1 1 1 0 1 1 0 1 1 0 1 1 1 1 1 1 1]
accRet2 = accuracy_score(y, y2_predict)
print(accRet2)
1.0
LR2.coef_
array([[-8.95942818e-01, -1.40029397e+00, -2.29434572e-04,
3.93039312e-03, 3.61578676e-02]])
# 先排序 否则有交叉
X1_new = X1.sort_values()
print(X1_new)
63 30.058822
1 30.286711
57 32.577200
70 32.722833
36 33.915500
...
56 97.645634
47 97.771599
51 99.272527
97 99.315009
75 99.827858
Name: Exam1, Length: 100, dtype: float64
theta0 = LR2.intercept_
theta1,theta2,theta3,theta4,theta5 = LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4]
a = theta4
b = theta5 * X1_new + theta2
c = theta0 + theta1 * X1_new + theta3 * X1_new * X1_new
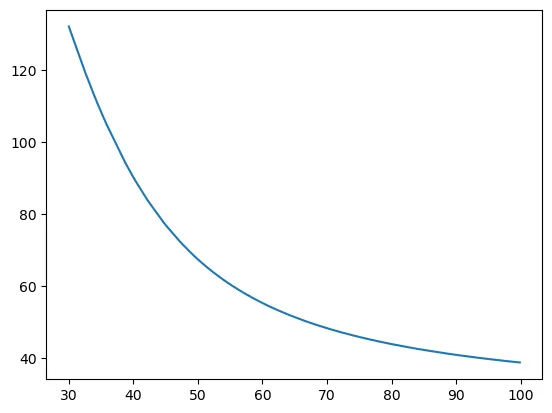
X2_new_bound = (-b + np.sqrt(b*b - 4*a*c))/(2*a)
# print(theta0,theta1,theta2,theta3,theta4,theta5)
print(X2_new_bound)
63 132.124249
1 130.914667
57 119.415258
70 118.725082
36 113.258684
...
56 39.275712
47 39.251001
51 38.963585
97 38.955634
75 38.860426
Name: Exam1, Length: 100, dtype: float64
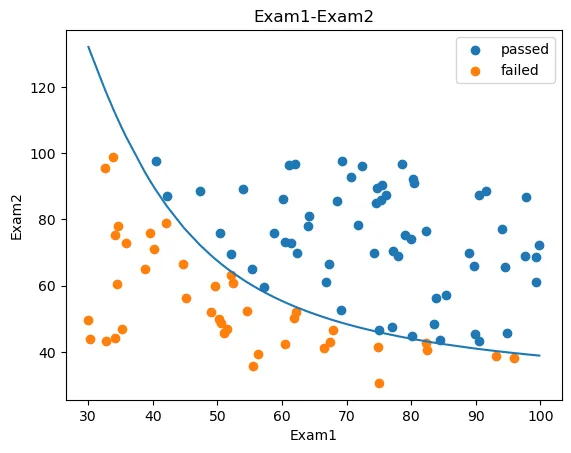
fig4 = plt.figure()
plt.plot(X1_new, X2_new_bound)
plt.show()
#visual the data with mask
fig5 = plt.figure()
plt.plot(X1_new, X2_new_bound)
passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed, failed), ('passed', 'failed'))
plt.show()
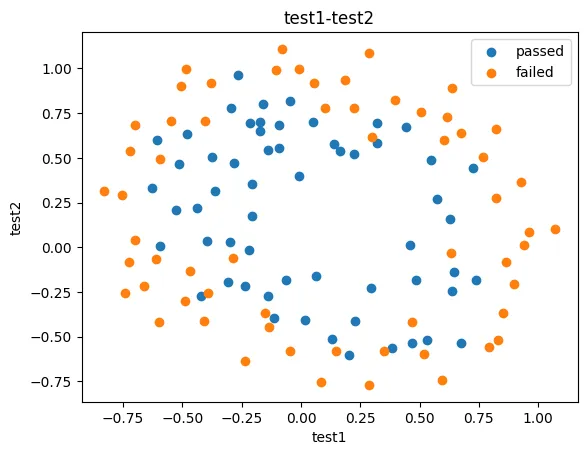
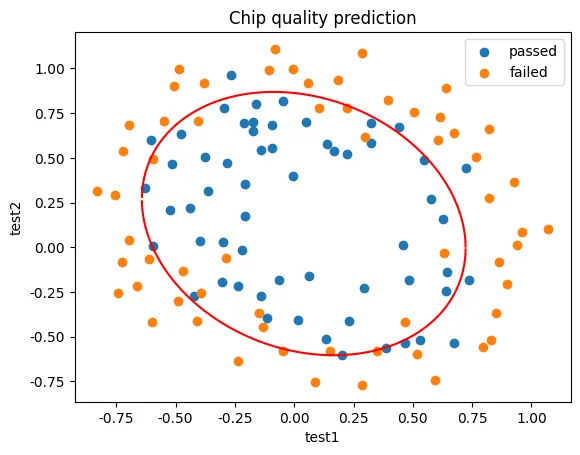
二、芯片质量预测
1、基于芯片测试.csv数据,建立逻辑回归模型(二阶边界),评估模型表现
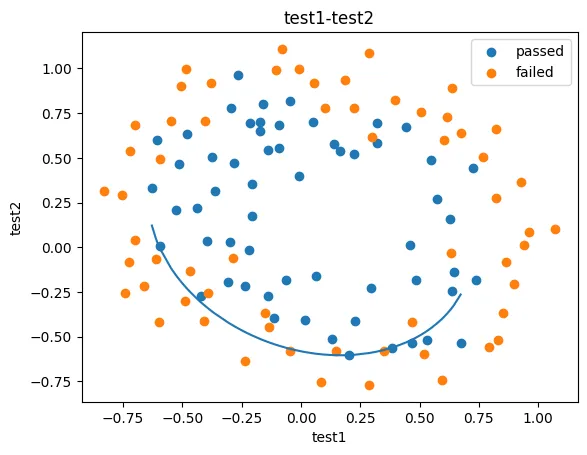
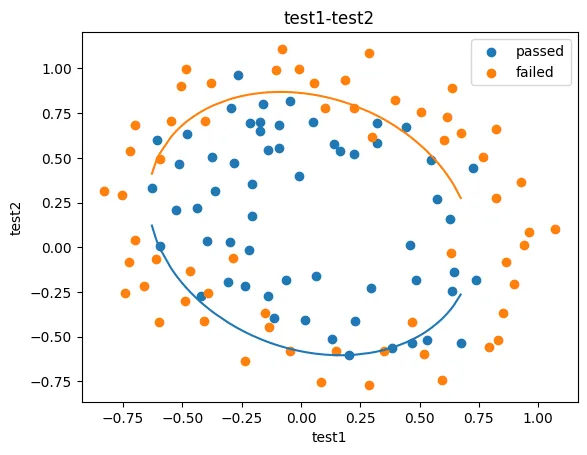
2、以函数的方式求解边界曲线
3、描绘出完整的决策边界曲线
import pandas as pd
import numpy as np
data = pd.read_csv('/root/chip_test.csv')
data.head()
| test1 | test2 | pass | |
|---|---|---|---|
| 0 | 0.051267 | 0.69956 | 1 |
| 1 | -0.092742 | 0.68494 | 1 |
| 2 | -0.213710 | 0.69225 | 1 |
| 3 | -0.375000 | 0.50219 | 1 |
| 4 | 0.183760 | 0.93348 | 0 |