Disruptor 高性能队列
Disruptor 是由 Java 编写的基于内存的高性能队列,最早由英国外汇交易公司LMAX(一种新型零售金融交易平台)开发并开源的,能够在无锁的情况下实现队列的高并发操作,用于在异步事件处理体系结构中提供低延迟,高吞吐量的工作队列。与ArrayBlockingQueue 一样,它通常用于多个线程间的消息传递(常见场景就是生产者-消费者模型),Disruptor 从功能、性能都远好于 ArrayBlockingQueue ,当多个线程之间传递大量数据或对性能要求较高时,可以考虑使用 Disruptor 作为 ArrayBlockingQueue 的替代者。
常见队列及底层实现
JDK中常见的线程安全的内置队列如下,队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded | 加锁 | arraylist |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedlist |
| ConcurrentLinkedQueue | unbounded | 无锁 | linkedlist |
| LinkedTransferQueue | unbounded | 无锁 | linkedlist |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是 ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成 LinkedBlockingQueue 和 ConcurrentLinkedQueue 两大类,前者也通过锁的方式来实现线程安全,而后者通过 CAS 实现。通过 CAS 方式实现的队列都是无界的,在稳定性要求特别高的系统中,为了防止生产者速度过快导致的内存溢出,同时也为了减少 GC 对系统性能的影响,会尽量选择数组/堆这样的数据结构,ArrayBlockingQueue 似乎成了唯一选择。
加锁与伪共享问题
1、加锁的性能损耗
Disruptor 论文中讲述了一个实验:
- 这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
- 机器环境:2.4G 6核
- 运算: 64位的计数器累加5亿次
| Method | Time (ms) |
|---|---|
| Single thread | 300 |
| Single thread with CAS | 5,700 |
| Single thread with lock | 10,000 |
| Single thread with volatile write | 4,700 |
| Two threads with CAS | 30,000 |
| Two threads with lock | 224,000 |
CAS操作比单线程无锁慢了1个数量级,有锁且多线程并发的情况下,速度比单线程无锁慢3个数量级。可见无锁速度最快。 单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能。 在多线程情况下,为了保证线程安全,必须使用CAS或锁,这种情况下,CAS的性能超过锁的性能,前者大约是后者的8倍。
综上可知,加锁的性能是最差的。
ComparaAndSwap(CAS)
CAS 操作,要么比较并交换成功,要么比较并交换失败。由 CPU 保证原子性。CAS 操作包含三个操作数——内存位置(V)、期望值(A)和新值(B),如果内存位置的值与期望值匹配,那么处理器就会自动将该位置值更新为新值,否则,处理器不做任何操作;
CAS 通过 JNI(Java Native Interface) 的代码来实现;运行Java调用C/C++,而CompareAndSwapxxx系列的方法就是借助C语言来调用CPU底层指令实现的,以常用的Intel x86平台来说,最终映射到CPU的指令为cmpxchg,这是一个原子指令,CPU 执行此命令时,实现比较替换操作;
对于Intel x86平台来说,cmpxchg指令如何保证多核心下的线程安全呢?其实系统底层进行 CAS 操作的时候,会判断当前系统是否为多核心系统;如果是多核心,就给从总线加锁,加所之后只有一个线程对总线加所成功,加锁成功之后,才会执行CAS操作,也就是说CAS的原子性时平台级别的,无需考虑多核心 CPU 对 CAS 操作有啥影响。
另外一个值得注意的点就是 CAS 的 ABA 问题,CAS 需要在操作值的时候检查下值,有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,在CAS方法执行之前,被其他线程修改为B,然后又修改回了A,那么CAS方法执行检查的时候就会发现他的值没有修改,但是实际缺变化了,这就是 CAS 的 ABA 问题。如何解决呢?JDK 中使用了 AtomicStampedReference, AtomicStampedReference 主要包含一个对象引用以及一个可以自动更新的正数 stamp 的Pair对象来解决ABA问题;
JUC中的锁都依赖于同步器 AbstractQueuedSynchronizer,而 AbstractQueuedSynchronizer 的核心就是CAS操作。下面是 AbstractQueuedSynchronizer 同步队列的入队操作,也是一种乐观锁的实现,多线程情况下,操作头节点和尾节点都有可能失败,失败后会再次尝试,直到成功:
/**
* Inserts node into queue, initializing if necessary. See picture above.
* @param node the node to insert
* @return node's predecessor
*/
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
2、伪共享问题
下图是CPU的3级缓存基本结构,L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
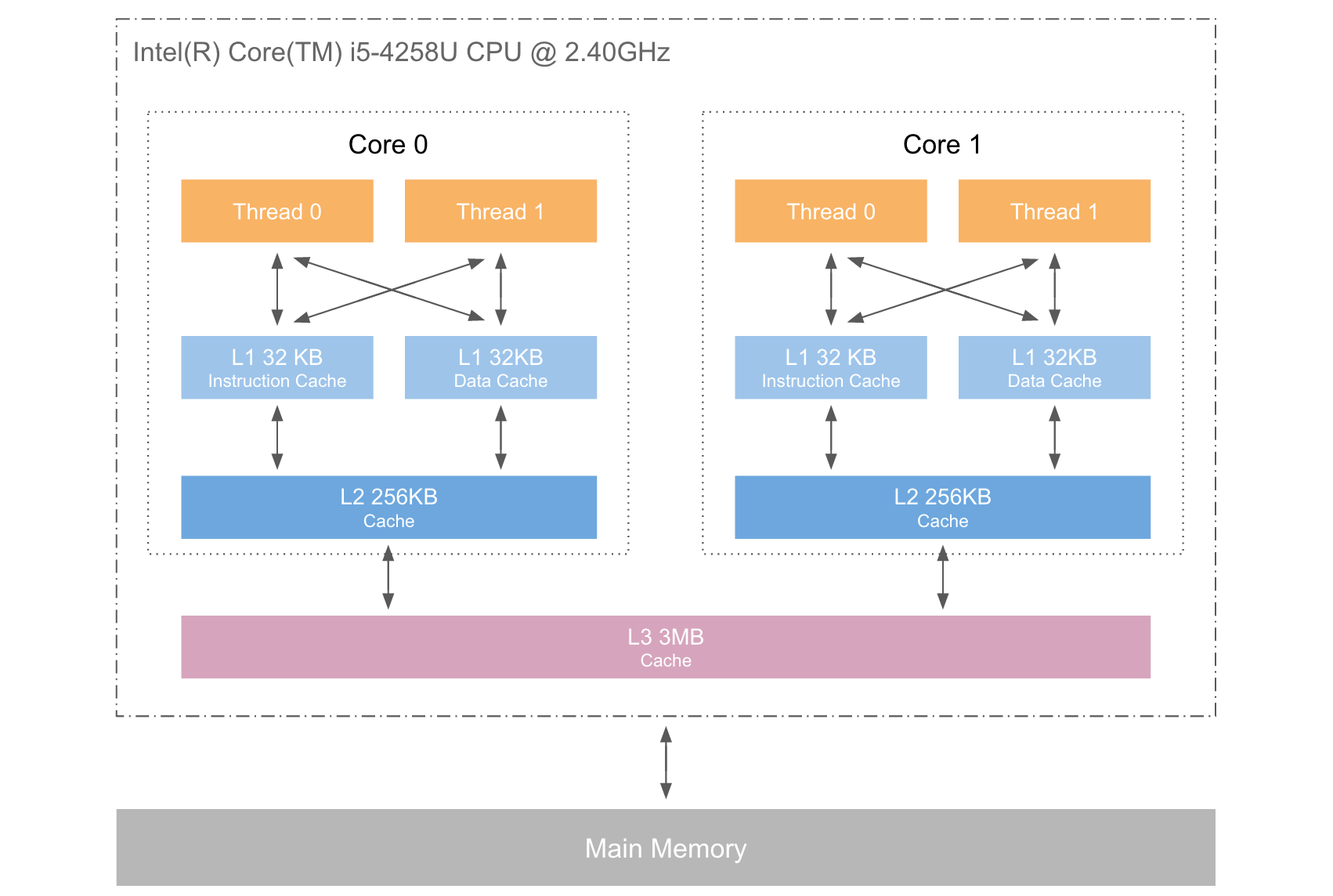 当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
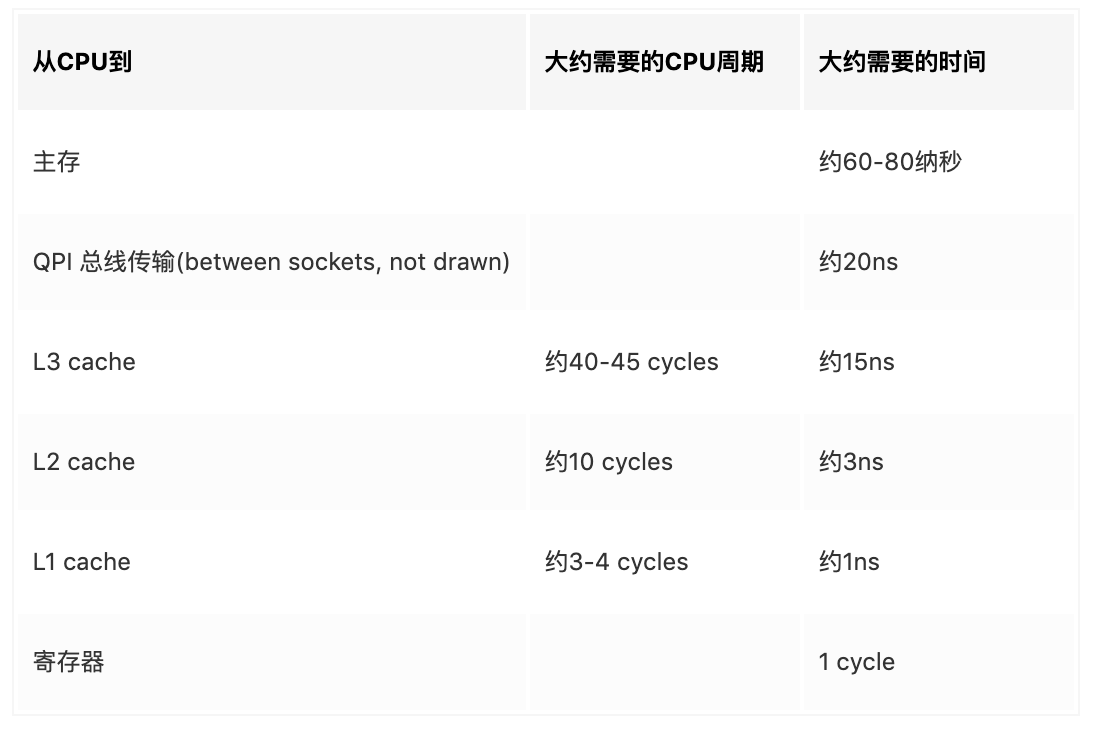
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。下面是从CPU访问不同层级数据的时间概念,可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级:
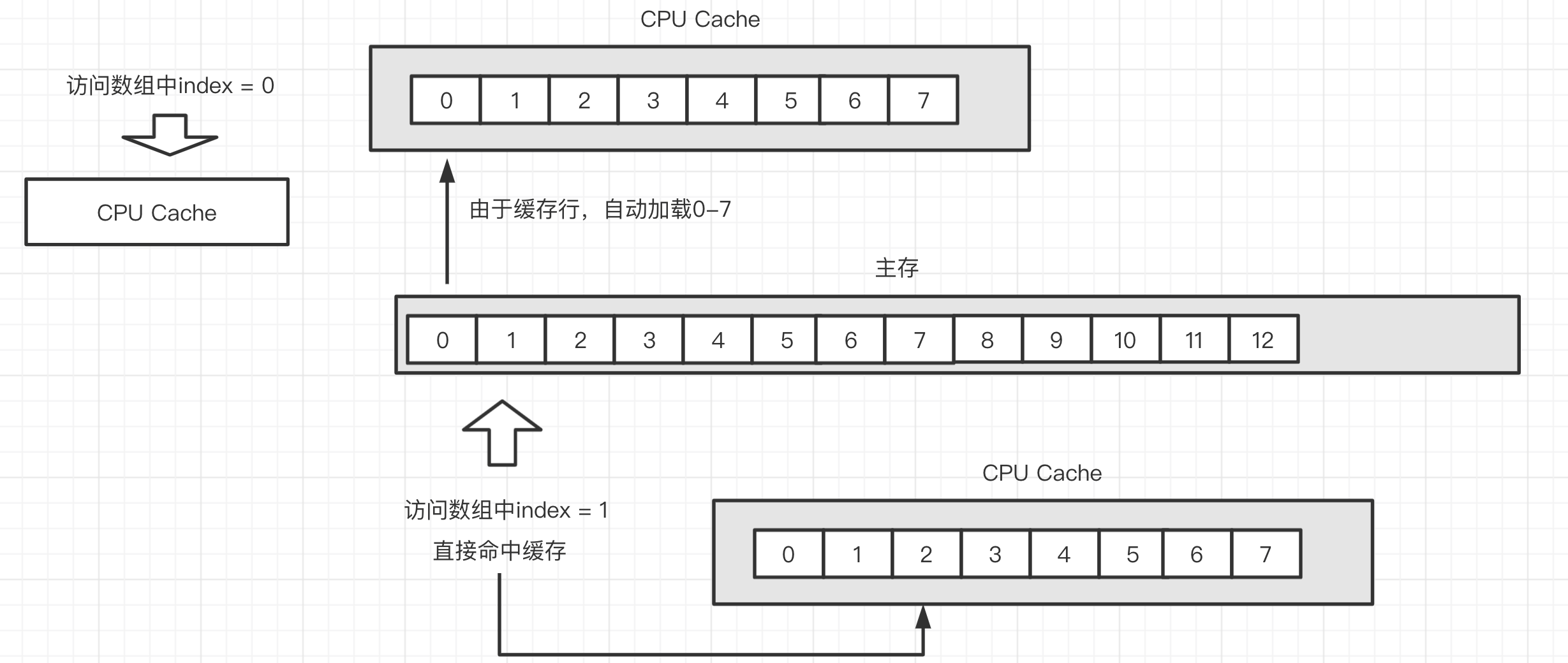
Cache是由很多个缓存行组成的。每个缓存行通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个缓存行(这也是为什么选择数组不选择链表,在数组中可以依靠缓存行得到高效的访问)。在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此可以非常快的遍历这个数组,也可以非常快速的遍历在连续内存块中分配的任意数据结构。下面的例子测试利用缓存行的特性和不利用缓存行的特性的效果对比:
package cn.tim;
public class CacheLineEffect {
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
}
}

 但是缓存行也不是万能的,因为缓存行依然带来了一个缺点,我在这里举个例子说明这个缺点,可以想象有个数组队列,ArrayQueue,他的数据结构如下:
但是缓存行也不是万能的,因为缓存行依然带来了一个缺点,我在这里举个例子说明这个缺点,可以想象有个数组队列,ArrayQueue,他的数据结构如下:
class ArrayQueue{
long maxSize;
long currentIndex;
......
}
对于 maxSize 是我们一开始就定义好的,数组的大小,对于 currentIndex,是标志我们当前队列的位置,这个变化比较快,可以想象你访问 maxSize 的时候,是不是把 currentIndex 也加载进来了,这个时候,其他线程更新 currentIndex,就会把 CPU 中的缓存行置为无效,这是 CPU 规定的,他并不是只把 currentIndex 置为无效,而是整个缓存行,如果此时又继续访问 maxSize 他依然得继续从内存中读取,但是 maxSize 却是我们一开始定义好的,我们应该访问缓存即可,但是却被我们经常改变的 currentIndex 所影响,这个问题就是伪共享问题。
为了解决上面缓存行出现的问题,在 Disruptor 中采用了 Padding 的方式:
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
其中的 Value 就被其他一些无用的 long 变量给填充了。这样你修改 Value 的时候,就不会影响到其他变量的缓存行。
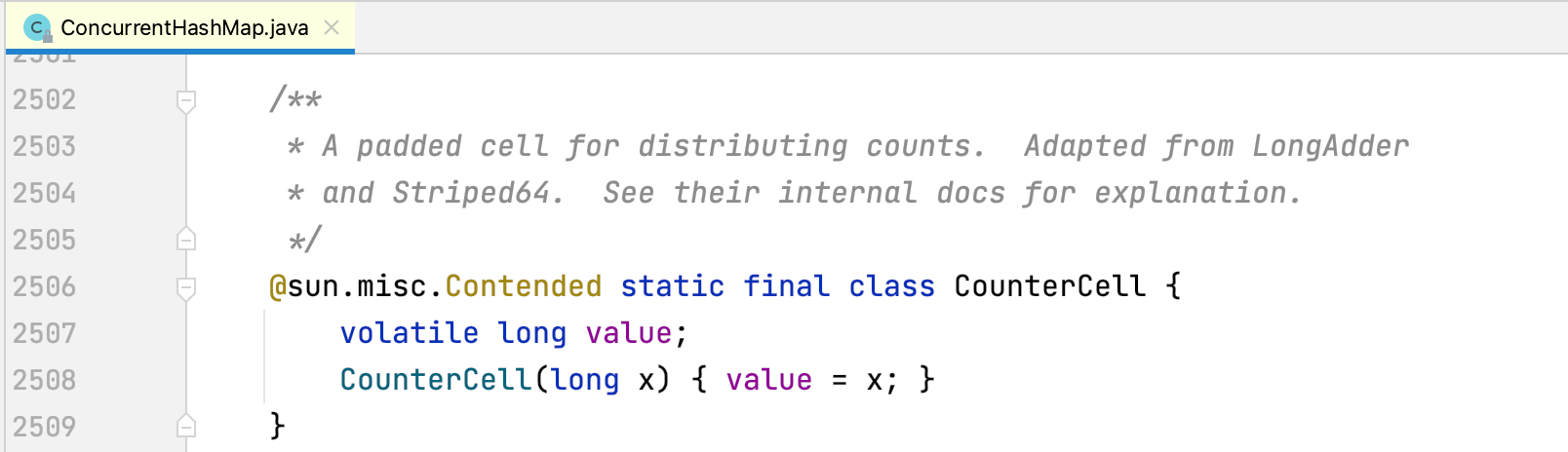
其实也不用上面写的那么复杂,在 JDK8 中提供了 @Contended 的注解,当然一般来说只允许JDK中内部使用,如果你自己使用那就得配置Jvm参数 -RestricContentended = fase,将限制这个注解置位取消。很多文章分析了 ConcurrentHashMap ,但是都把这个注解给忽略掉了,在ConcurrentHashMap 中就使用了这个注解,在 ConcurrentHashMap 每个桶都是单独的用计数器去做计算,而这个计数器由于时刻都在变化,所以被用这个注解进行填充缓存行优化,以此来增加性能。
 在 ArrayBlockingQueue 中,takeIndex、putIndex、count 这三个变量很容易放到一个缓存行中, 但是之间修改没有太多的关联. 所以每次修改, 都会使之前缓存的数据失效, 从而不能完全达到共享的效果。当生产者线程put一个元素到 ArrayBlockingQueue 时, putIndex 会修改, 从而导致消费者线程的缓存中的缓存行无效, 需要从主存中重新读取,这就是在 ArrayBlockingQueue 中的伪共享问题。
在 ArrayBlockingQueue 中,takeIndex、putIndex、count 这三个变量很容易放到一个缓存行中, 但是之间修改没有太多的关联. 所以每次修改, 都会使之前缓存的数据失效, 从而不能完全达到共享的效果。当生产者线程put一个元素到 ArrayBlockingQueue 时, putIndex 会修改, 从而导致消费者线程的缓存中的缓存行无效, 需要从主存中重新读取,这就是在 ArrayBlockingQueue 中的伪共享问题。

public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** items index for next take, poll, peek or remove */
/** 需要被取走的元素下标 */
int takeIndex;
/** items index for next put, offer, or add */
/** 可被元素插入的位置的下标 */
int putIndex;
/** Number of elements in the queue */
/** 队列中元素的数量 */
int count;
......
核心数据结构——RingBuffer
分析完了 ArrayBlockingQueue 低效的原因,下面来看看 Disruptor 是如何设计的:
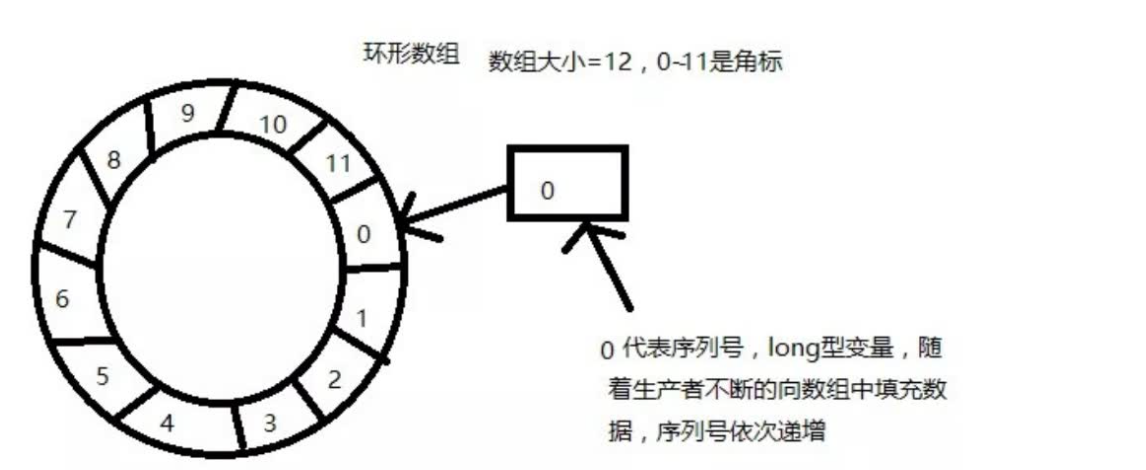
在 Disruptor 中,采用了 RingBuffer 来作为队列的数据结构,RingBuffer 就是一个环形的数组,既然是数组,我们便可对其设置大小;在这个 RingBuffer 中,除了数组之外,还有一个序列号,用来指向数组中的下一个可用元素,供生产者使用或者消费者使用,也就是生产者可以生产的地方,或者消费者可以消费的地方,注意:序列号和数组索引是两个概念;
所以Disruptor主要是通过以下设计来解决队列速度慢的问题: 1、环形数组结构 为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
2、无锁设计 每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
3、元素位置定位 数组长度2的N次方,通过位运算,加快定位的速度,这与HashMap是一样的。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
Disruptor 使用方法
1、添加Maven依赖
2、声明Event来包含需要传递的事件(数据)
3、使用EventFactory来实例化Event对象
4、声明消费者事件(数据)处理器
5、生产者发送事件(数据)
6、测试验证
声明Event来包含需要传递的事件
package consumer;
/**
* 声明Event来包含需要传递的事件(数据)
*/
public class StringEvent {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
定义事件工厂
package consumer;
import com.lmax.disruptor.EventFactory;
/**
* 定义事件工厂
*/
public class StringEventFactory implements EventFactory<StringEvent> {
@Override
public StringEvent newInstance() {
return new StringEvent();
}
}
定义事件处理器(消费者)
package consumer;
import com.lmax.disruptor.EventHandler;
/**
* 定义事件处理器
*/
public class StringEventHandler implements EventHandler<StringEvent> {
@Override
public void onEvent(StringEvent stringEvent, long sequence, boolean endOfBatch) {
System.out.println("消费者:" + stringEvent.getValue()
+ "--> sequence = " + sequence + " endOfBatch = " + endOfBatch);
}
}
定义生产者
package producer;
import com.lmax.disruptor.RingBuffer;
import consumer.StringEvent;
/**
* 生产者
*/
public class StringEventProducer {
public final RingBuffer<StringEvent> ringBuffer;
public StringEventProducer(RingBuffer<StringEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
/**
* 生产事件(数据)
* @param data
*/
public void onData(String data){
// 1、获取下一个序号,也就是要放置数据的位置
long sequence = ringBuffer.next();
try {
// 2、从队列中取出数据承载对象
StringEvent stringEvent = ringBuffer.get(sequence);
// 3、装入数据
stringEvent.setValue(data);
}finally {
// 4、发布事件
ringBuffer.publish(sequence);
}
}
}
测试一下
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.YieldingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import consumer.StringEvent;
import consumer.StringEventFactory;
import consumer.StringEventHandler;
import org.junit.Test;
import producer.StringEventProducer;
import java.util.concurrent.*;
public class DisruptorTest {
@Test
public void test(){
long startTime = System.currentTimeMillis();
// 1、创建一个线程池提供线程来触发Consumer的事件处理
ThreadFactory threadFactory = Executors.defaultThreadFactory();
// 2、创建工厂
StringEventFactory eventFactory = new StringEventFactory();
// 3、创建RingBuffer的大小,2的N次方
int ringBufferSize = 16;
// 4、创建Disruptor,指定单生产者模式
Disruptor<StringEvent> disruptor = new Disruptor<>(eventFactory, ringBufferSize,
threadFactory, ProducerType.SINGLE, new YieldingWaitStrategy());
// 5、链接消费端方法
disruptor.handleEventsWith(new StringEventHandler());
// 6、启动消费者
disruptor.start();
// 7、创建RingBuffer容器
RingBuffer<StringEvent> ringBuffer = disruptor.getRingBuffer();
// 8、创建生产者
StringEventProducer producer = new StringEventProducer(ringBuffer);
for (int i = 0; i < 1000000; i++) {
producer.onData(String.valueOf(i));
}
// 9、关闭disruptor与executor
disruptor.shutdown();
long endTime = System.currentTimeMillis();
System.out.println("Total Time = " + (endTime - startTime));
}
}
Disruptor
Disruptor 的入口,主要封装了环形队列 RingBuffer、消费者集合 ConsumerRepository 的引用,主要提供了获取环形队列、添加消费者、生产者向 RingBuffer 中添加事件(即生产者生产数据的操作);
RingBuffer
Disruptor 中队列具体的实现,底层封装了Object[]数组,在初始化时,会使用 Event 事件对数组进行填充,填充的大小就是bufferSize设置的值,此外该对象内部还维护了 Sequencer(序列生成器)具体的实现;
Sequencer
序列生成器,分别有 MultiProducerSequencer(多生产者序列生产器)和 SingleProducerSequencer(单生产者序列生产器)两个实现类 。在 Sequencer 中,维护了消费者的 Sequence(序列对象)和生产者自己的 Sequence(序列对象);以及维护了生产者与消费者序列冲突时候的等待策略 WaitStrategy;
Sequence
序列对象,内部维护了一个 long 型的 value,这个序列指向了 RingBuffer 中 Object[] 数组具体的角标,生产者和消费者各自维护自己的Sequence,但都是指向RingBuffer的Object[]数组;
WaitStrategy
等待策略,当没有可消费的事件时,消费者根据特定的策略进行等待,当没有可生产的地方时,生产者根据特定的策略进行等待;
Event
事件对象,就是我们Ringbuffer中存在的数据,在Disruptor中用Event来定义数据,并不存在Event类,它只是一个定义,是一个概念,表示要传递的数据;
EventProcessor
事件处理器,单独在一个线程内执行,判断消费者的序列和生产者序列关系,决定是否调用自定义的事件处理器,也就是是否可以进行消费;
EventHandler
事件处理器,由用户自定义实现,也就是最终的事件消费者,需要实现EventHandler接口;
Producer
事件生产者,我们定义的发送事件的对象;
RingBuffer的读取与写入过程
以下部分内容转载自 《高性能队列——Disruptor》
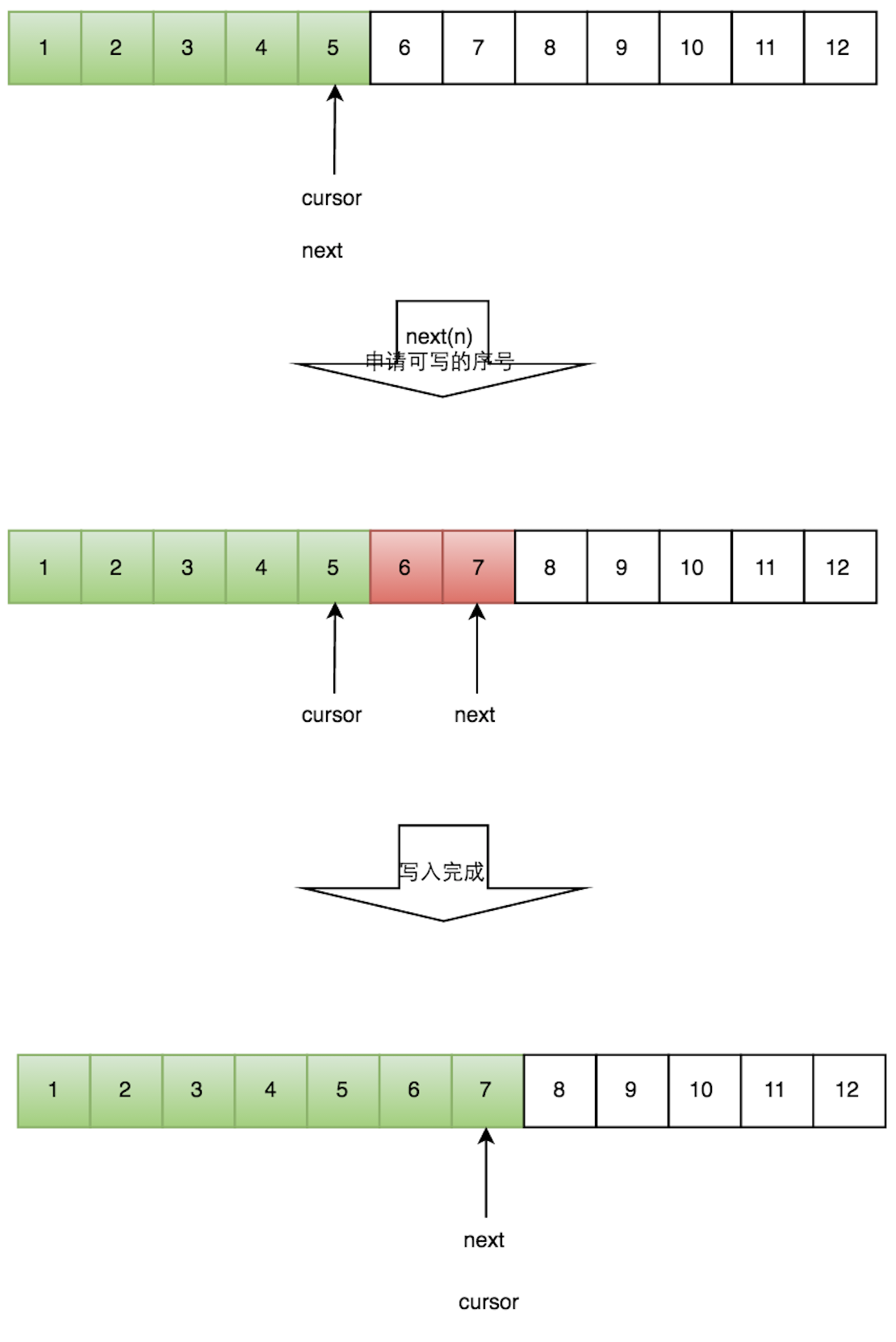
一个生产者
写数据
生产者单线程写数据的流程比较简单:
- 申请写入m个元素;
- 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。
多个生产者
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor 的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
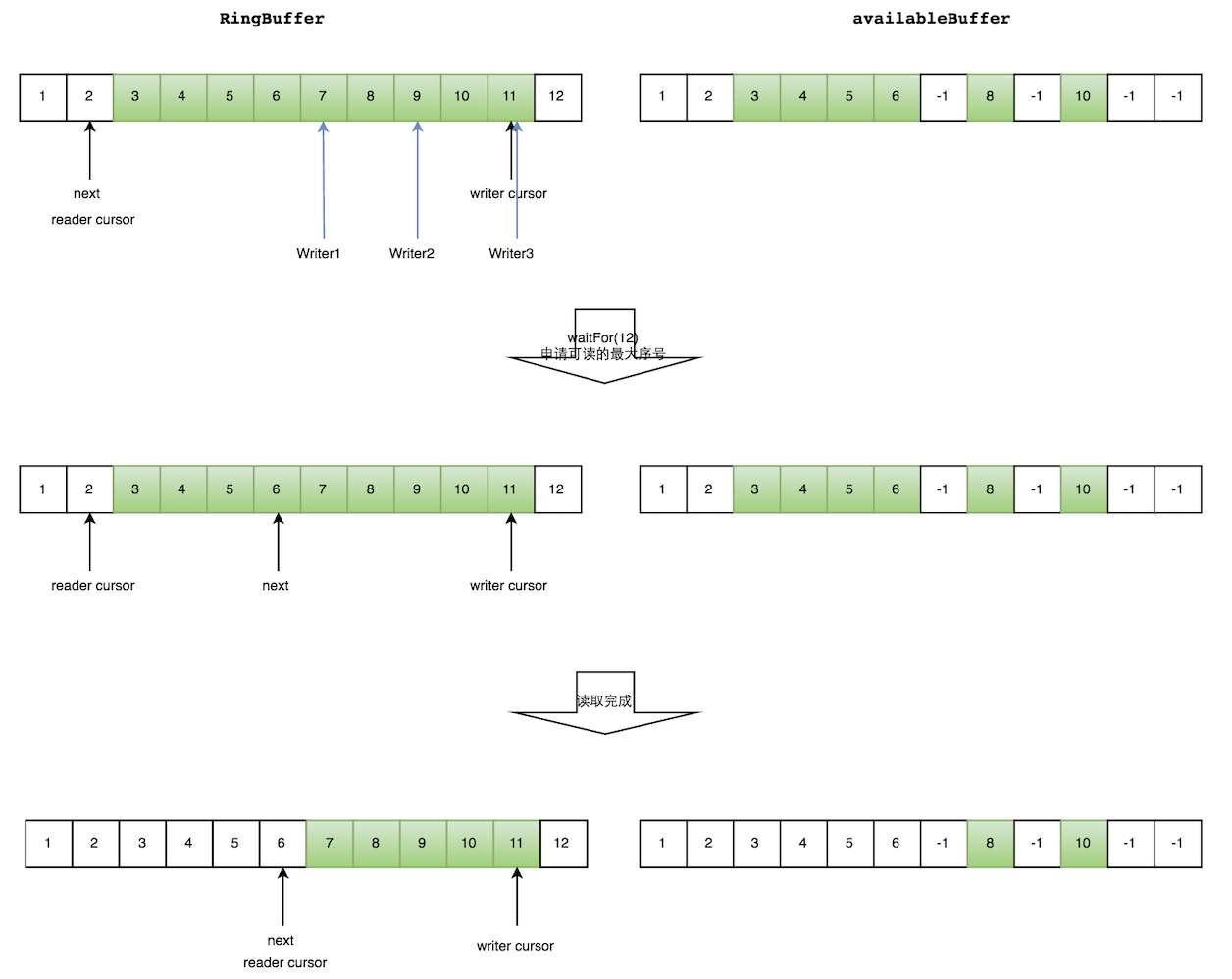
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor 在多个生产者的情况下,引入了一个与 Ring Buffer 大小相同的 buffer:available Buffer。当某个位置写入成功的时候,便把 availble Buffer 相应的位置置位,标记为写入成功。读取的时候,会遍历 available Buffer,来判断元素是否已经就绪。
下面分读数据和写数据两种情况介绍。
读数据
生产者多线程写入的情况会复杂很多:
- 申请读取到序号n;
- 若 writer cursor >= n,这时仍然无法确定连续可读的最大下标。从 reader cursor 开始读取 available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
如下图所示,读线程读到下标为2的元素,三个线程 Writer1/Writer2/Writer3 正在向 RingBuffer 相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断 writer cursor>=11。然后开始读取 availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是 WaitFor(11) 返回6。
然后,消费者读取下标从3到6共计4个元素。
写数据
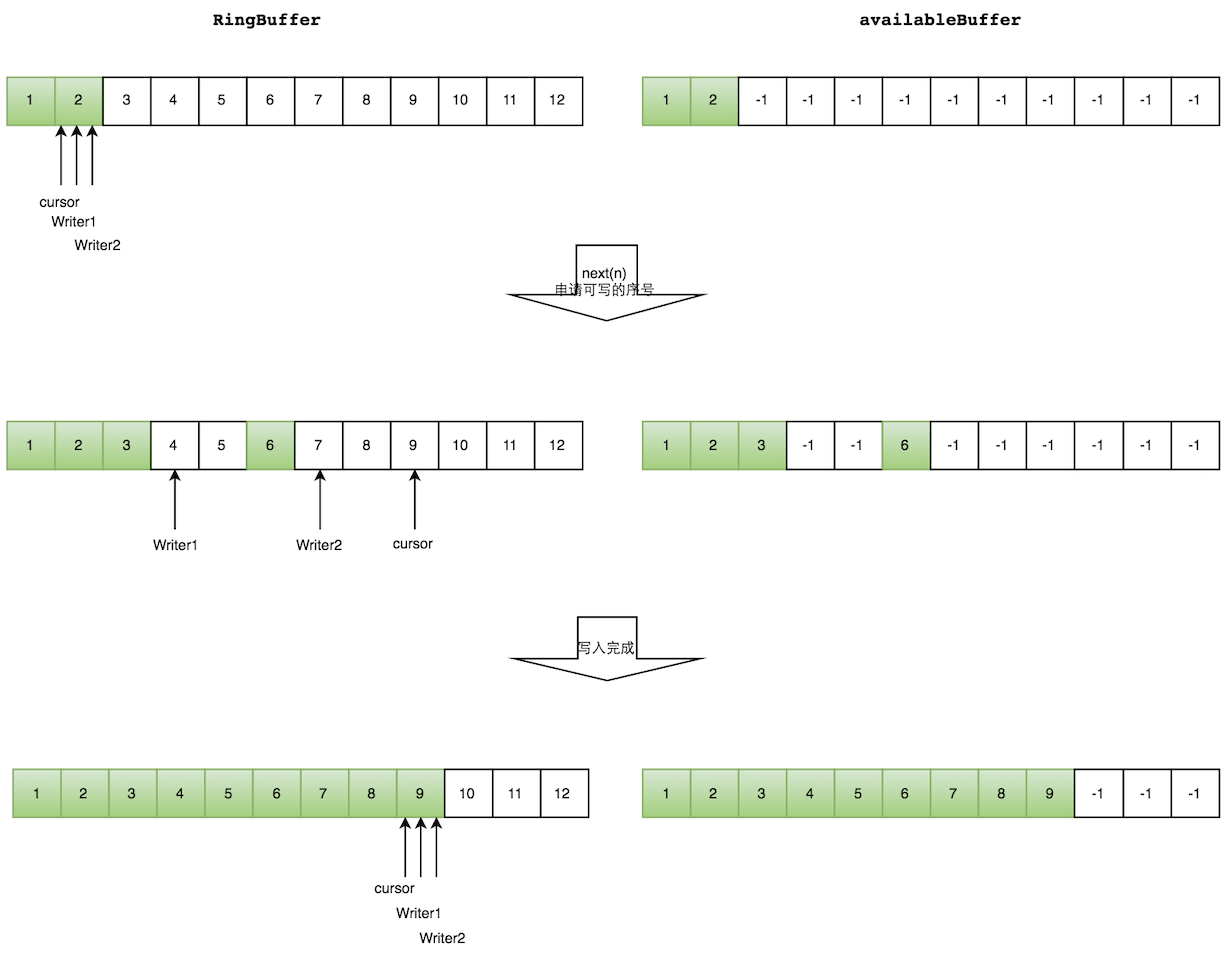
多个生产者写入的时候:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。
防止不同生产者对同一段空间写入的代码,如下所示:
public long tryNext(int n) throws InsufficientCapacityException {
if (n < 1) {
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do {
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current)) {
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
return next;
}
通过do/while循环的条件cursor.compareAndSet(current, next),来判断每次申请的空间是否已经被其他生产者占据。假如已经被占据,该函数会返回失败,While循环重新执行,申请写入空间。
消费者的流程与生产者非常类似,这儿就不多描述了。
Disruptor性能比较
测试环境是 OS:MacOS Catalina 10.15.7,CPU:2.6 GHz 六核Intel Core i7 16GB,JVM 1.8.0_281 64-bit
单生产者单消费者:
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import org.junit.Test;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
public class PressureTest {
int EVENT_NUM_OHM = 100000000;
int EVENT_NUM_FM = 50000000;
int EVENT_NUM_OM = 10000000;
static class Data {
private Long id;
private String name;
public Data(){}
public Data(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
@Test
public void testArrayBlockingQueuePerformance() {
final ArrayBlockingQueue<Data> queue = new ArrayBlockingQueue<>(2048);
final long startTime = System.currentTimeMillis();
// 向容器中添加元素
new Thread(() -> {
long i = 0;
while (i < EVENT_NUM_FM) {
try {
queue.put(new Data(i, "c" + i));
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}).start();
// 从容器中取出元素
long k = 0;
while (k < EVENT_NUM_FM) {
try {
queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
k++;
}
long endTime = System.currentTimeMillis();
System.out.println("ArrayBlockingQueue costTime = " + (endTime - startTime) + "ms");
// ArrayBlockingQueue costTime = 12522ms
}
class DataConsumer implements EventHandler<Data> {
long startTime;
int i;
public DataConsumer() {
this.startTime = System.currentTimeMillis();
}
@Override
public void onEvent(Data data, long seq, boolean bool) {
i++;
if (i == EVENT_NUM_OHM) {
long endTime = System.currentTimeMillis();
System.out.println("Disruptor costTime = " + (endTime - startTime) + "ms");
// Disruptor costTime = 6238ms
}
}
}
@Test
public void testDisruptorPerformance(){
int ringBufferSize = 2048;
Disruptor<Data> disruptor = new Disruptor<>(
Data::new,
ringBufferSize,
Executors.defaultThreadFactory(),
ProducerType.SINGLE,
new YieldingWaitStrategy());
DataConsumer consumer = new DataConsumer();
//消费数据
disruptor.handleEventsWith(consumer);
disruptor.start();
RingBuffer<Data> ringBuffer = disruptor.getRingBuffer();
for (long i = 0; i < EVENT_NUM_OHM; i++) {
long seq = ringBuffer.next();
Data data = ringBuffer.get(seq);
data.setId(i);
data.setName("c" + i);
ringBuffer.publish(seq);
}
}
}
多生产者单消费者:
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import org.junit.Test;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.Executors;
public class PressureTest {
int DATA_SIZE = 10000000;
static class Data {
private Long id;
private String name;
public Data(){}
public Data(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "name = " + name + ", id = " + id;
}
}
@Test
public void testArrayBlockingQueuePerformance() {
final ArrayBlockingQueue<Data> queue = new ArrayBlockingQueue<>(16);
// 向容器中添加元素
new Thread(() -> {
long i = 0;
while (i < DATA_SIZE) {
try {
queue.put(new Data(i, "AAA"));
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}).start();
new Thread(() -> {
long i = 0;
while (i < DATA_SIZE) {
try {
queue.put(new Data(i, "BBB"));
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}).start();
new Thread(() -> {
long i = 0;
while (i < DATA_SIZE) {
try {
queue.put(new Data(i, "CCC"));
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}).start();
final long startTime = System.currentTimeMillis();
// 从容器中取出元素
long k = 0;
while (k < DATA_SIZE * 3L) {
try {
queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
k++;
}
long endTime = System.currentTimeMillis();
System.out.println("ArrayBlockingQueue costTime = " + (endTime - startTime) + "ms");
// ArrayBlockingQueue costTime = 25297ms
}
class DataConsumer implements EventHandler<Data> {
long startTime;
int i;
public DataConsumer() {
this.startTime = System.currentTimeMillis();
}
@Override
public void onEvent(Data data, long seq, boolean bool) {
i++;
if (i == (DATA_SIZE * 3 - 1)) {
long endTime = System.currentTimeMillis();
System.out.println("Disruptor Consumer costTime = " + (endTime - startTime) + "ms");
// Disruptor Consumer costTime = 3172ms
}
}
}
@Test
public void testDisruptorPerformance(){
int ringBufferSize = 16;
Disruptor<Data> disruptor = new Disruptor<>(
Data::new,
ringBufferSize,
Executors.defaultThreadFactory(),
ProducerType.MULTI,
new YieldingWaitStrategy());
DataConsumer consumer = new DataConsumer();
//消费数据
disruptor.handleEventsWith(consumer);
disruptor.start();
RingBuffer<Data> ringBuffer = disruptor.getRingBuffer();
CountDownLatch countDownLatch = new CountDownLatch(3);
new Thread(new Producer(ringBuffer, "AAA", countDownLatch)).start();
new Thread(new Producer(ringBuffer, "BBB", countDownLatch)).start();
new Thread(new Producer(ringBuffer, "CCC", countDownLatch)).start();
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
class Producer implements Runnable{
RingBuffer<Data> ringBuffer;
String producerName;
CountDownLatch countDownLatch;
public Producer(RingBuffer<Data> ringBuffer,
String producerName,
CountDownLatch countDownLatch) {
this.ringBuffer = ringBuffer;
this.producerName = producerName;
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
for (long i = 0; i < DATA_SIZE; i++) {
long seq = ringBuffer.next();
Data data = ringBuffer.get(seq);
data.setId(i);
data.setName(producerName);
ringBuffer.publish(seq);
}
countDownLatch.countDown();
}
}
}
可以看出,Disruptor 在性能上略胜一筹。其他情况下的性能测试可以参考 《高性能队列——Disruptor》 即可。
Disruptor的等待策略
BlockingWaitStrategy
Disruptor 默认的等待策略是 BlockingWaitStrategy。这个策略的内部适用一个锁和条件变量来控制线程的执行和等待(Java基本的同步方法)。BlockingWaitStrategy 是最慢的等待策略,但也是 CPU 使用率最低和最稳定的选项。然而,可以根据不同的部署环境调整选项以提高性能。
所以 BlockingWaitStrategy 最好是在 CPU 资源紧缺,吞吐量和延迟并不重要的场景下使用。
TimeoutBlockingWaitStrategy
TimeoutBlockingWaitStrategy 等待策略与 BlockingWaitStrategy 一样,唯一的区别就是在加锁的基础上还可以加上超时限制,也是最好是在 CPU 资源紧缺,吞吐量和延迟并不重要的场景下使用。
PhasedBackoffWaitStrategy
PhasedBackoffWaitStrategy 等待策略与 BlockingWaitStrategy 有两个区别,PhasedBackoffWaitStrategy 采用自旋锁等待,而 BlockingWaitStrategy 使用同步锁等待。另外 PhasedBackoffWaitStrategy 在等待时可以让出 CPU 资源,也是最好是在 CPU 资源紧缺,吞吐量和延迟并不重要的场景下使用。
SleepingWaitStrategy
和BlockingWaitStrategy一样,SpleepingWaitStrategy的CPU使用率也比较低。它的方式是循环等待并且在循环中间调用LockSupport.parkNanos(1)来睡眠,(在Linux系统上面睡眠时间60µs).然而,它的优点在于生产线程只需要计数,而不执行任何指令。并且没有条件变量的消耗。但是,事件对象从生产者到消费者传递的延迟变大了。SleepingWaitStrategy最好用在不需要低延迟,而且事件发布对于生产者的影响比较小的情况下。比如异步日志功能。
YieldingWaitStrategy
YieldingWaitStrategy是可以被用在低延迟系统中的两个策略之一,这种策略在减低系统延迟的同时也会增加CPU运算量。YieldingWaitStrategy策略会循环等待sequence增加到合适的值。循环中调用Thread.yield()允许其他准备好的线程执行。如果需要高性能而且事件消费者线程比逻辑内核少的时候,推荐使用YieldingWaitStrategy策略。例如:在开启超线程的时候。
BusySpinWaitStrategy
BusySpinWaitStrategy是性能最高的等待策略,同时也是对部署环境要求最高的策略。这个性能最好,用在事件处理线程比物理内核数目还要小的时候。例如:在禁用超线程技术的时候。
几种并行模式
单一写者模式
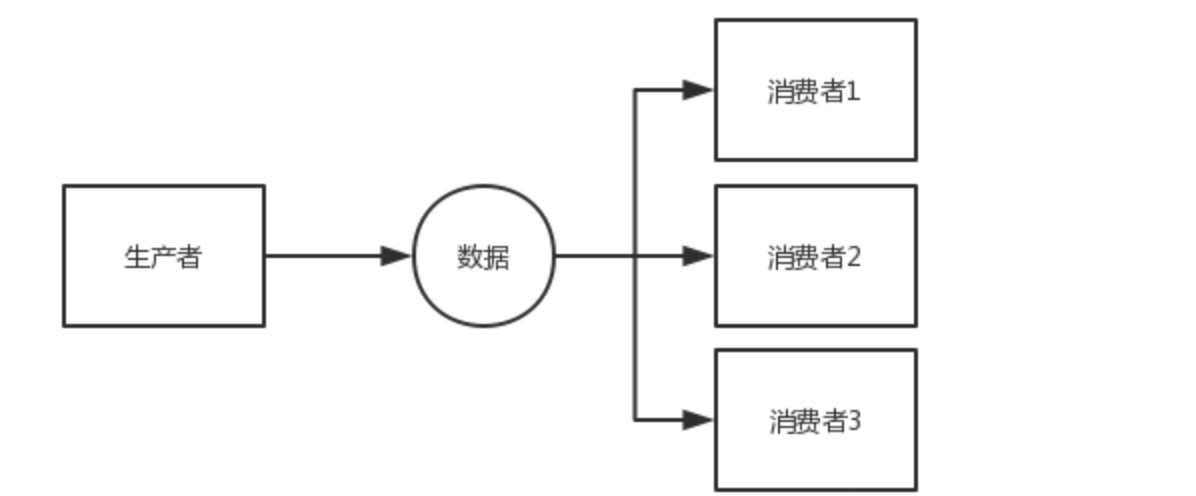
public class singleProductorLongEventMain {
public static void main(String[] args) throws Exception {
//.....// Construct the Disruptor with a SingleProducerSequencer
Disruptor<LongEvent> disruptor = new Disruptor(factory,
bufferSize,
ProducerType.SINGLE, // 单一写者模式,
executor);//.....
}
}
一次生产,串行消费

/**
* 串行依次执行
* p --> c11 --> c21
*/
public static void serial(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler()).then(new C21EventHandler());
disruptor.start();
}
菱形方式执行
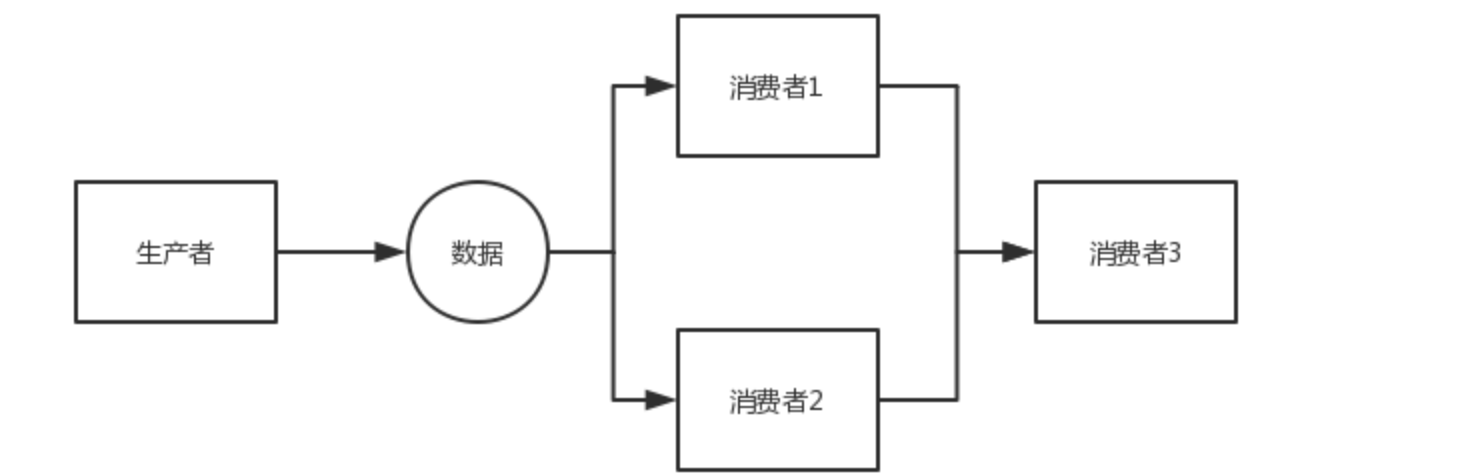
public static void diamond(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler(),new C12EventHandler()).then(new C21EventHandler());
disruptor.start();
}
链式并行计算
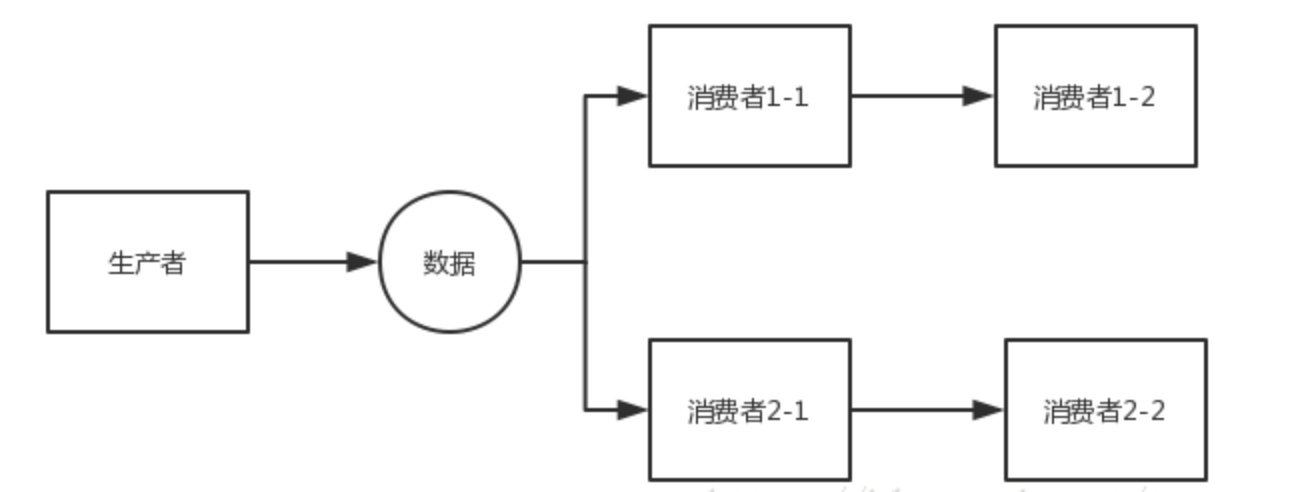
public static void chain(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler()).then(new C12EventHandler());
disruptor.handleEventsWith(new C21EventHandler()).then(new C22EventHandler());
disruptor.start();
}
相互隔离模式
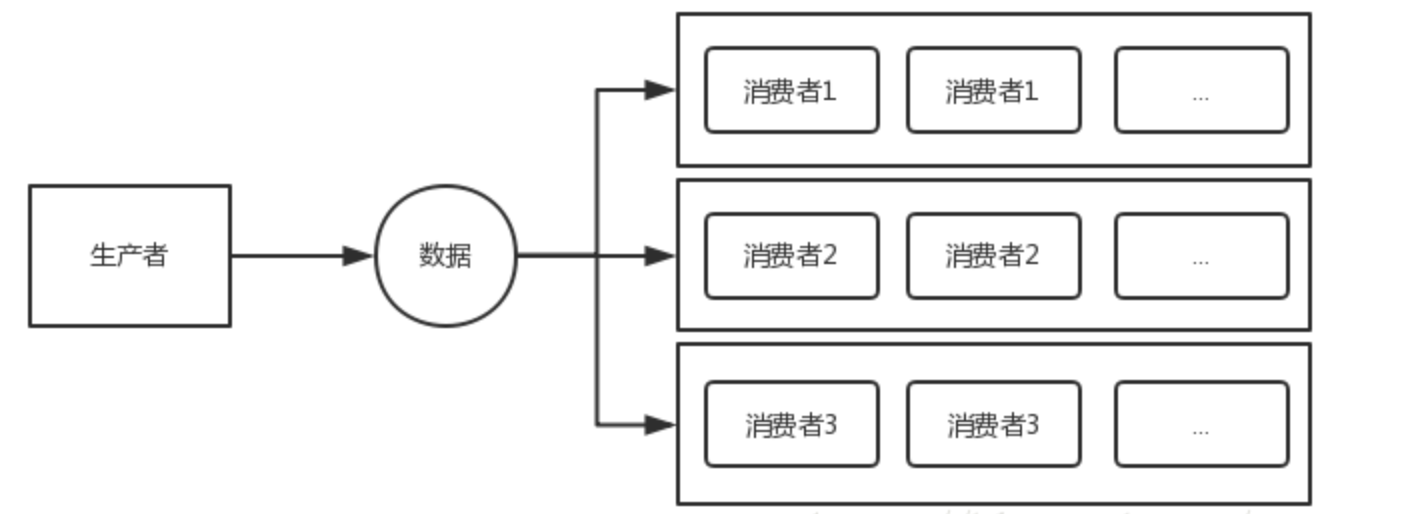
public static void parallelWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new C11EventHandler());
disruptor.handleEventsWithWorkerPool(new C21EventHandler(),new C21EventHandler());
disruptor.start();
}
航道模式
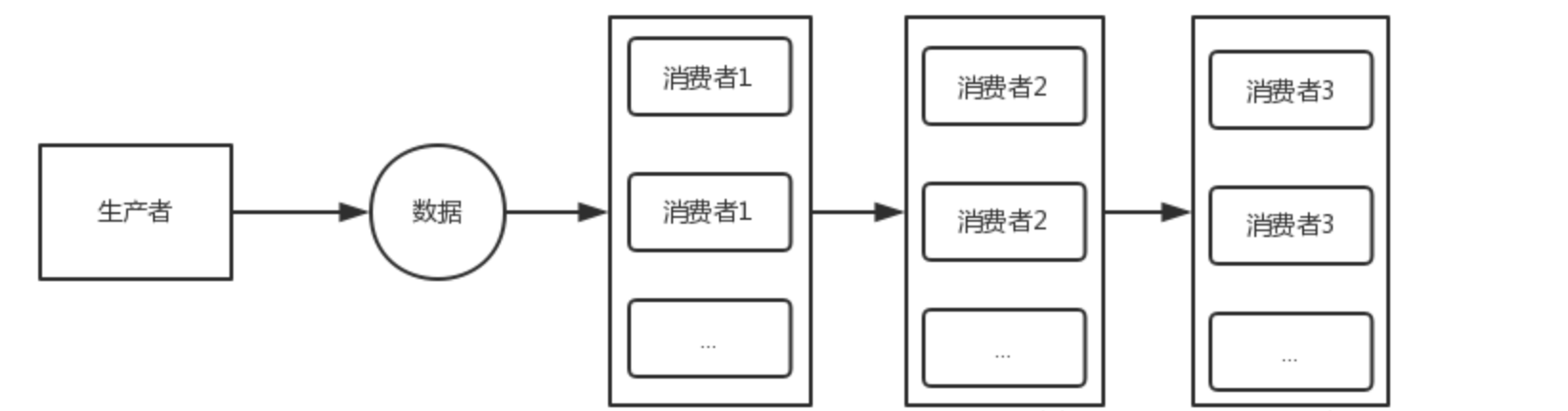
/**
* 串行依次执行,同时C11,C21分别有2个实例
* p --> c11 --> c21
*/
public static void serialWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new C11EventHandler()).then(new C21EventHandler(),new C21EventHandler());
disruptor.start();
}