Flink架构与核心API基础(一)
本篇文章主要学习 Flink的核心API的基础部分的笔记, 在学习之前先部署了一个单节点的Flink环境,然后重点需要了解的就是Flink的执行上下文(StreamExecutionEnvironment)、数据源(Source API)、转化相关操作(Transformation)、输出(Sink) 等,另外就是提交和取消作业的一些操作。
Flink单节点部署
Flink部署很简单,JDK环境8、11均可:
[root@localhost bin]# wget https://dlcdn.apache.org/flink/flink-1.12.7/flink-1.12.7-bin-scala_2.11.tgz
[root@localhost bin]# tar -zxvf flink-1.12.7-bin-scala_2.11.tgz
[root@localhost bin]# mv ~/flink-1.12.7 /usr/local
[root@localhost bin]# cd /usr/local/flink-1.12.7
因为只是想在本地启动一个 Flink,所以可以设置一个Standalone Cluster,也就是单节点运行Flink。但是通常在生产环境中是选择集群部署,本地直接运行 Flink:
[root@localhost bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host localhost.
Starting taskexecutor daemon on host localhost.
[root@localhost bin]# ./stop-cluster.sh
Stopping taskexecutor daemon (pid: 1916557) on host localhost.
Stopping standalonesession daemon (pid: 1916257) on host localhost.
如果要集群部署,可以编辑 conf/flink-conf.yaml ,配置master节点、内存等信息。
Flink架构与组件
1、Flink Client 将批处理或流式处理的应用程序编译成数据流图,然后将其提交给 JobManager;
2、JobManager Flink的中心工作协调组件, 三种模式:
- Application Mode
- Pre-Job Mode
- Session Mode
3、 TaskManager 实际执行 Flink 作业工作的服务;
具体的文档可以参考 https://nightlies.apache.org/flink/flink-docs-release
修改 slot 数量,默认是1:
taskmanager.numberOfTaskSlots: 4
Flink作业提交
提交一个WordCount的示例作业:
flink run -c org.apache.flink.streaming.examples.socket.SocketWindowWordCount /usr/local/flink-1.12.7/examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9527
列出全部的作业和正在运行中的作业
[root@localhost ~]# flink list -a
Waiting for response...
------------------ Running/Restarting Jobs -------------------
05.04.2022 22:22:17 : ea2a6b714cc8329332b45081db7c2a06 : Socket Window WordCount (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
05.04.2022 22:16:08 : 0bd2b3561569dc9a4161e870f3e853a9 : Socket Window WordCount (CANCELED)
--------------------------------------------------------------
[root@localhost ~]# flink list -r
Waiting for response...
------------------ Running/Restarting Jobs -------------------
07.04.2022 00:31:13 : ca2d7a25c6bee1bd767948ac5b50fecf : Socket Window WordCount (RUNNING)
--------------------------------------------------------------
通过UI提交作业,直接点击Add New,以SocketWordCount为例,参数如下:
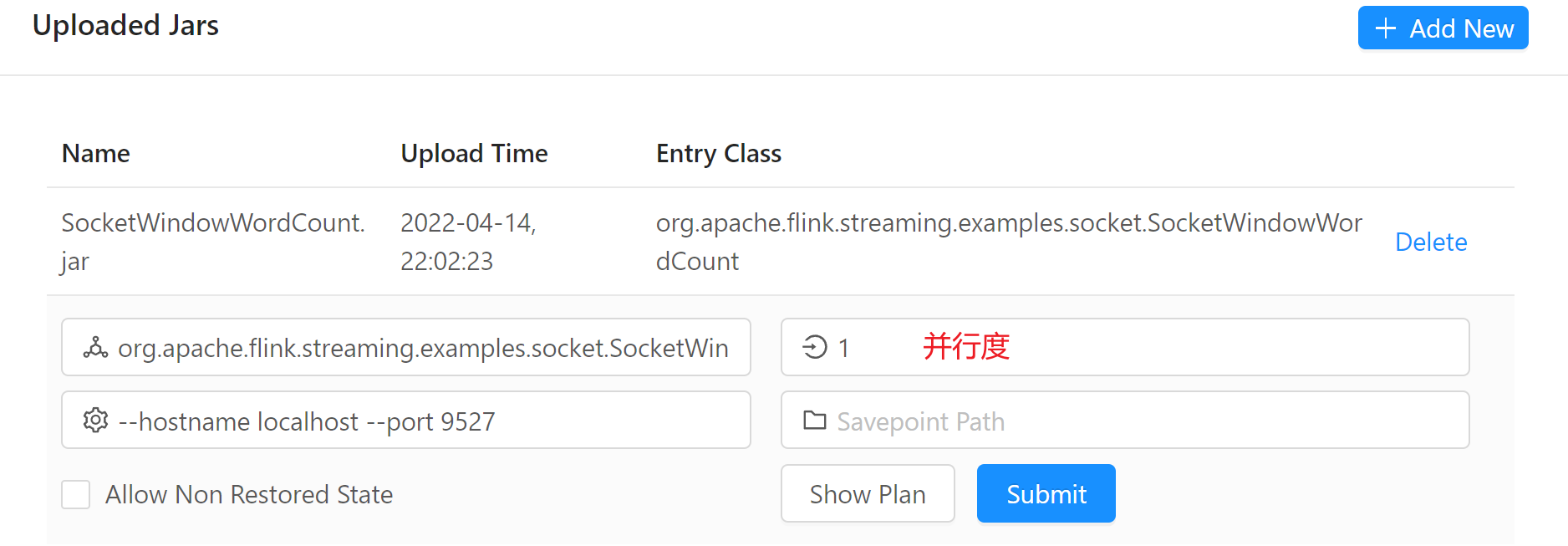
在并行度为1的时候和并行度为2的时候的区别:
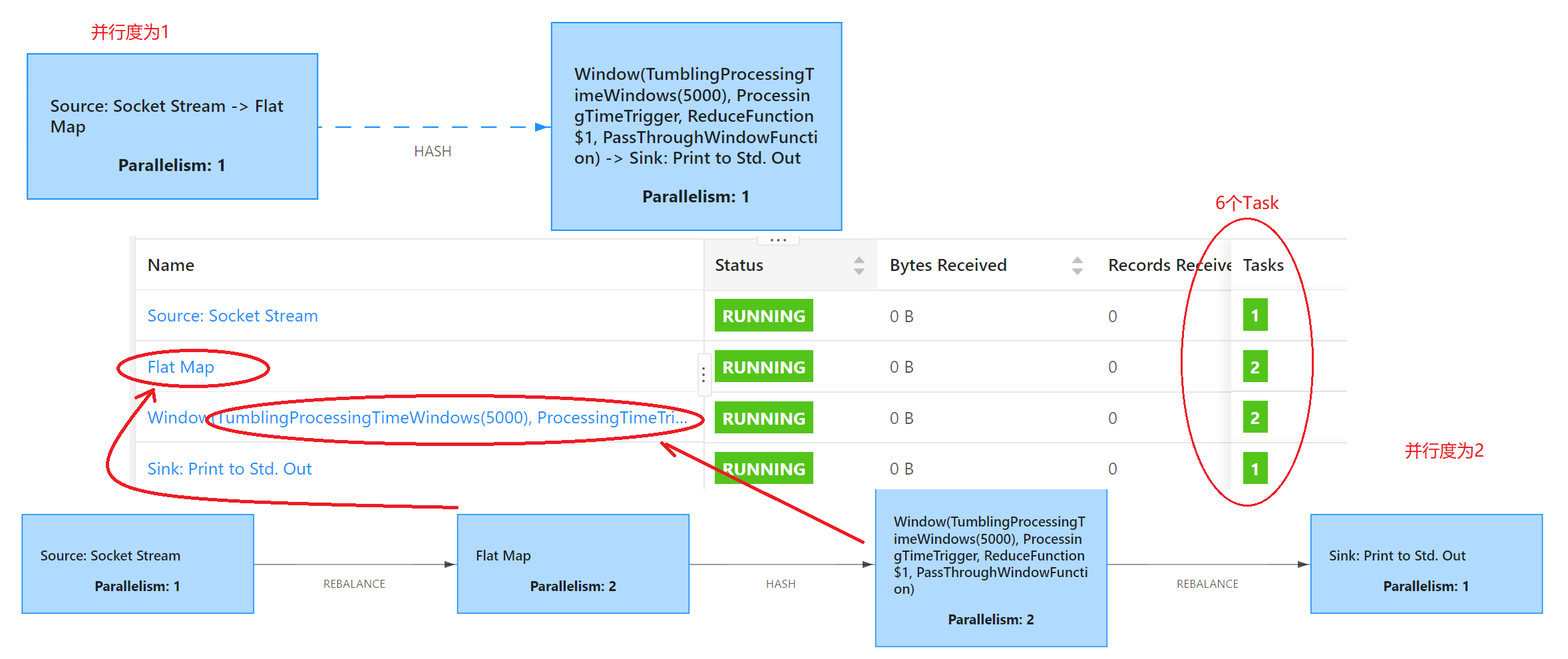
如果并行度发生变化时就会产生新的(子)Task。
Flink取消作业
可以先在Web面板上取消作业!
Flink实时处理核心API —— 基础篇
Flink DataStream API Guide :
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/
1、StreamExecutionEnvironment - 上下文环境
2、Source API - 数据源相关的API
3、Transformation API - 数据转换的一些API
4、SinkAPI
StreamExecutionEnvironment
获得执行上下文(getExecutionEnvironment用的最多)
// 创建上下文
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
LocalStreamEnvironment envLocal = StreamExecutionEnvironment.createLocalEnvironment();
LocalStreamEnvironment envLocalPar = StreamExecutionEnvironment.createLocalEnvironment(5);
// withWebUI
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment.createRemoteEnvironment();
获得执行上下文后开始读数据,比如读文本数据:
DataStream<String> text = env.readTextFile("file:///path/to/file");
Source API
// 创建上下文
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("127.0.0.1", 9527);
System.out.println(source.getParallelism()); // socketTextStream并行度 -> 1
// filter时不设置并行度就是和CPU核心数相关
SingleOutputStreamOperator<String> filterStream = source
.filter((FilterFunction<String>) s -> !"pk".equals(s))
.setParallelism(4); // 如果这里设置了并行度4,那么filterStream并行度就为4
System.out.println(filterStream.getParallelism());
filterStream.print();
env.execute("SourceApp"); // filter 并行度 -> 12
从集合并行读取:
private static void readFromCollection(StreamExecutionEnvironment env) {
env.setParallelism(5); // 对于env设置的并行度是全局的并行度
DataStreamSource<Long> source = env.fromParallelCollection(
new NumberSequenceIterator(1, 10), Long.class
);
source.setParallelism(3); // 对于算子层面的并行度,如果全局设置,以算子的并行度为准
System.out.println("source: " + source.getParallelism());
SingleOutputStreamOperator<Long> filter = source.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return aLong > 5;
}
});
System.out.println("filter: " + filter.getParallelism());
filter.print();
}
从消息队列读取,比如Kafaka,首先引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者 Scala 对象:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
System.out.println(stream.getParallelism());
stream.print();
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/kafka/
Transformation API
将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流拓扑,比如之前学过的 map、flatMap、filter、keyBy等,详细参考文档:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/overview/
下面是Map的两个小例子:
/**
* 读进来的数据是一行行的,也是字符串类型
*
* 将map算子对应的函数作用到DataStream,产生新的DataStream
* map会作用到已有的DataStream这个数据集的每一个元素上
*/
public static void test_map(StreamExecutionEnvironment env){
DataStreamSource<String> source = env.readTextFile("data/access.log");
SingleOutputStreamOperator<AccessLog> map = source.map((MapFunction<String, AccessLog>) s -> {
String[] split = s.trim().split(",");
if (split.length < 3) return null;
Long time = Long.parseLong(split[0]);
String domain = split[1];
Double traffic = Double.parseDouble(split[2]);
return new AccessLog(time, domain, traffic);
});
map.print();
/*
* 6> AccessLog{time=202512120010, domain='cn.tim', traffic=1000.0}
* 1> AccessLog{time=202512120010, domain='cn.tim', traffic=3000.0}
* 3> AccessLog{time=202512120010, domain='com.tim', traffic=7000.0}
* 8> AccessLog{time=202512120010, domain='com.tim', traffic=6000.0}
* 12> AccessLog{time=202512120010, domain='cn.tim', traffic=2000.0}
* 9> AccessLog{time=202512120010, domain='cn.xx', traffic=5000.0}
* 4> AccessLog{time=202512120010, domain='com.tim', traffic=4000.0}
*/
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
env.fromCollection(list)
.map((MapFunction<Integer, Integer>) integer -> integer * 2)
.print();
// 3> 4
// 4> 6
// 2> 2
}
flatMap、filter、keyBy等之前用过,也可以参考官方文档,此处不再赘述,来看其他的Transformation :
public static void test_keyBy(StreamExecutionEnvironment env){
DataStreamSource<String> source = env.readTextFile("data/access.log");
SingleOutputStreamOperator<AccessLog> map = source.map((MapFunction<String, AccessLog>) s -> {
String[] split = s.trim().split(",");
if (split.length < 3) return null;
Long time = Long.parseLong(split[0]);
String domain = split[1];
Double traffic = Double.parseDouble(split[2]);
return new AccessLog(time, domain, traffic);
});
// 按照domain分组,对traffic求和
// map.keyBy("domain").sum("traffic").print(); // 过时写法
map.keyBy(new KeySelector<AccessLog, String>() {
@Override
public String getKey(AccessLog accessLog) throws Exception {
return accessLog.getDomain();
}
}).sum("traffic").print();
// Lambda 写法,其实用Scala更爽
map.keyBy((KeySelector<AccessLog, String>) AccessLog::getDomain).sum("traffic").print();
}
下面是Reduce操作(示例程序依然是WordCount),比如求和等操作,keyBy过后得到的数据是 keyed data stream,Reduce操作需要传入的数据正好是 keyed data stream:
// WordCount
public static void test_reduce(StreamExecutionEnvironment env){
DataStreamSource<String> source = env.socketTextStream("127.0.0.1", 9527);
source.flatMap((FlatMapFunction<String, String>) (s, collector) -> {
String[] split = s.trim().split(",");
for (String s1 : split) {
collector.collect(s1);
}
}).returns(TypeInformation.of(new TypeHint<String>(){}))
.map((MapFunction<String, Tuple2<String, Integer>>) s -> Tuple2.of(s, 1))
// Lambda 指定返回类型
.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>(){}))
.keyBy(x -> x.f0)
.reduce((ReduceFunction<Tuple2<String, Integer>>)
(t2, t1) -> Tuple2.of(t2.f0, t2.f1 + t1.f1))
.print();
}
Sink API
下面看看Sink API,Sink其实就是输出,包括输出到文件、Socket、外部系统(比如Kafka)或打印到控制台 。Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里。
public static void test_sink(StreamExecutionEnvironment env){
DataStreamSource<String> source = env.socketTextStream("127.0.0.1", 9527);
System.out.println("source: " + source.getParallelism());
/*
* print() 源码
* PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
* return addSink(printFunction).name("Print to Std. Out");
*/
source.print().setParallelism(1); // 设置并行度为1
// 打印到标准错误流
source.printToErr();
// 参数就是加个前缀
source.print(" prefix ");
}
PrintSinkOutputWriter.java 的 open 函数源码解释了为什么多并行度打印时前缀不是从0开始的:
public void open(int subtaskIndex, int numParallelSubtasks) {
this.stream = !this.target ? System.out : System.err;
this.completedPrefix = this.sinkIdentifier;
// 判断并行度是否大于1
if (numParallelSubtasks > 1) {
if (!this.completedPrefix.isEmpty()) {
this.completedPrefix = this.completedPrefix + ":";
}
// 如果大于1,输出时就在subtaskIndex上加1
this.completedPrefix = this.completedPrefix + (subtaskIndex + 1);
}
if (!this.completedPrefix.isEmpty()) {
this.completedPrefix = this.completedPrefix + "> ";
}
}