JDK8新特性
虽然已经用过了一些Java8的新特性,但是总来没有仔细总结一下。Java8自从2014年就发布了,到目前为止只有一小部分公司在用JDK7及其以下的版本,大部分已经迁移至Java8,甚至Java11(关于Java9和Java11的特性我会在之后两篇文章中记述),目前只看Java8那些最主要的、也是最常用的新特性,我到目前为止用到的最多的也就是Stream API和Lambda表达式,新时间日期的API也比较常用。
Java8新特性简介
JDK8的新特性主要的从以下几个方面谈起:
1、速度更快: 优化垃圾回收机制(永久代被移除,使用元空间,元空间受物理内存大小限制);数据结构整改(如HashMap,这也就意味着HashSet也跟着变化了);ConcurrentHashMap也变了,从之前的锁分段机制改成了大量的CAS操作,HashMap和ConcurrentHashMap都是由原来的链表改成了链表+红黑树的结构;所以速度明显提高。
2、代码更少: 通过Lambda表达式来减少不必要的代码编写量,代码更少更简洁。
3、强大的Stream API: 有了Stream API就意味着在Java中操作数据就像SQL语句一样简单,其实比SQL语句还简单
4、便于并行: 对Fork/Join框架进行了提升,之前得开发者自己给任务做分隔,代码复杂度很高。但是自从JDK8以来,对Fork/Join框架进行了大幅度的提升,很方便的从串行切换到并行。
5、最大化减少空指针异常 Optional: 通过Optional容器类来提供一些解决方法,最大化避免空指针异常
Lambda表达式
Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
public class LambdaDemo {
public static void main(String[] args) {
Comparator<Integer> integerComparator = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
};
TreeSet<Integer> integerTreeSet = new TreeSet<>(integerComparator);
//lambda表达式
Comparator<Integer> integerComparator1 = (o1, o2) -> Integer.compare(o1, o2);
TreeSet<Integer> integerTreeSet1 = new TreeSet<>(integerComparator1);
//lambda表达式
Comparator<Integer> integerComparator2 = Integer::compare;
TreeSet<Integer> integerTreeSet2 = new TreeSet<>(integerComparator1);
}
}
上面的例子可能不是很形象的说明Lambda表达式的作用,下面可以看看实际一点的使用例子,有一个员工集合Employee,现在需要根据年龄或者薪水过滤出对应的数据:
public class Employee {
private int age; // 年龄
private int salary; // 薪水
private String name; // 姓名
public Employee(int age, int salary, String name) {
this.age = age;
this.salary = salary;
this.name = name;
}
// Getter / Setter / toString
}
各种过滤条件的演示:
public class LambdaDemo {
public static void main(String[] args) {
List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim")
);
List<Employee> retListByAge = filterByAge(employeeList);
retListByAge.forEach(System.out::println);
System.out.println("----------------------------------------");
List<Employee> retListBySalary = filterBySalary(employeeList);
retListBySalary.forEach(System.out::println);
}
// 根据年龄过滤
private static List<Employee> filterByAge(List<Employee> employeeList) {
ArrayList<Employee> retList = new ArrayList<>();
for(Employee employee: employeeList){
if(employee.getAge() > 20) retList.add(employee);
}
return retList;
}
// 根据工资过滤
private static List<Employee> filterBySalary(List<Employee> employeeList) {
ArrayList<Employee> retList = new ArrayList<>();
for(Employee employee: employeeList){
if(employee.getSalary() > 5000) retList.add(employee);
}
return retList;
}
}
现在我们用策略模式进行改进:
// 过滤策略
public interface MyFilterPredict {
boolean filter(Employee employee);
}
策略对应的实现类:
// 根据年龄定义的过滤器
public class EmployeeAgeFilterPredict implements MyFilterPredict {
@Override
public boolean filter(Employee employee) {
return employee.getAge() > 20;
}
}
// 根据薪水定义的过滤器
public class EmployeeSalaryFilterPredict implements MyFilterPredict {
@Override
public boolean filter(Employee employee) {
return employee.getSalary() > 5000;
}
}
使用的时候:
public class LambdaDemo {
public static void main(String[] args) {
List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim")
);
List<Employee> retListByAge = commonFilter(employeeList, new EmployeeAgeFilterPredict());
retListByAge.forEach(System.out::println);
System.out.println("-----------------------------");
List<Employee> retListBySalary = commonFilter(employeeList, new EmployeeSalaryFilterPredict());
retListBySalary.forEach(System.out::println);
}
// 按照自定义策略过滤
private static List<Employee> commonFilter(List<Employee> employeeList, MyFilterPredict myFilterPredict) {
ArrayList<Employee> retList = new ArrayList<>();
for (Employee employee: employeeList)
if(myFilterPredict.filter(employee)) retList.add(employee);
return retList;
}
}
但是我们实际上并不需要写策略接口对应的实现类,直接使用匿名内部类即可:
public static void main(String[] args) {
List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim")
);
List<Employee> retListByAge = commonFilter(employeeList, new MyFilterPredict() {
@Override
public boolean filter(Employee employee) {
return employee.getAge() > 20;
}
});
retListByAge.forEach(System.out::println);
System.out.println("-----------------------------");
List<Employee> retListBySalary = commonFilter(employeeList, new MyFilterPredict() {
@Override
public boolean filter(Employee employee) {
return employee.getSalary() > 5000;
}
});
retListBySalary.forEach(System.out::println);
}
直接使用匿名内部类那么就意味着可以直接用Lambda表达式来代替:
public static void main(String[] args) {
List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim")
);
List<Employee> retListByAge = commonFilter(employeeList, employee -> employee.getAge() > 20);
retListByAge.forEach(System.out::println);
System.out.println("-----------------------------");
List<Employee> retListBySalary = commonFilter(employeeList, employee -> employee.getSalary() > 5000);
retListBySalary.forEach(System.out::println);
}
其实,retListByAge.forEach(System.out::println); 也是Lambda表达式的一个用法。但是还有更骚的用法,那就是用Stream来解决这个问题:
public class LambdaDemo {
public static void main(String[] args) {
List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim")
);
employeeList.stream()
.filter((e) -> e.getAge() > 20)
.forEach(System.out::println);
System.out.println("-----------------------------");
employeeList.stream()
.filter((e) -> e.getSalary() > 5000)
.forEach(System.out::println);
}
// 薪水大于1000的有4个,但是我只需要前面两个
employeeList.stream()
.filter((e) -> e.getSalary() > 1000)
.limit(2)
.forEach(System.out::println);
// 只把名字提取出来
List<String> nameList = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toList());
nameList.forEach(System.out::println);
}
不知道上面的例子是否能体会到Lambda表达式的简介易用呢?现在具体来看看Lambda表达式的语法:
Lambda表达式在Java语言中引入了一个新的语法元素和操作符。这个操作符为->,该操作符被称为Lambda操作符或箭头操作符。它将Lambda 分为两个部分:
- 左侧:指定了Lambda表达式需要的所有参数;
- 右侧:指定了Lambda体,即Lambda表达式要执行的功能。
语法格式一:无参数、无返回值
public class LambdaDemo {
public static void main(String[] args) {
Runnable runnable = ()-> System.out.println("Hello");
runnable.run();
}
}
语法格式二:有一个参数、无返回值(只有一个参数时,参数的小括号可不写)
import java.util.function.Consumer;
public class LambdaDemo {
public static void main(String[] args) {
Consumer<String> consumer = (e) -> System.out.println(e);
consumer.accept("Hello");
Consumer<String> consumer = e -> System.out.println(e);
consumer.accept("Hello");
}
}
语法格式三:有两个以上的参数、并且Lambda体中有多条语句
public class LambdaDemo {
public static void main(String[] args) {
Comparator<Integer> comparator = (x, y) -> {
System.out.println("Hello");
return Integer.compare(x, y);
};
}
}
语法格式四:若Lambda体中一条语句,return 和大括号都可以省略不写
public class LambdaDemo {
public static void main(String[] args) {
Comparator<Integer> comparator = (x, y) -> Integer.compare(x, y);
}
}
语法格式六:Lambda表达式中的参数列表的数据类型可以不写,JVM会根据上下文推导
public class LambdaDemo {
public static void main(String[] args) {
Comparator<Integer> comparator = (Integer x, Integer y) -> Integer.compare(x, y);
Comparator<Integer> comparator = (x, y) -> Integer.compare(x, y);
}
}
Lambda表达式需要函数式接口的支持,接口中只有一个抽象方法的接口,称为函数式接口。可以使用@FunctionInterface注解修饰,可以检查是否是函数式接口,如下图MyFilterPredict接口由于有两个接口,所以不能被称作是函数式接口,@FunctionInterface注解自然就会报错,因为如果接口中含有两个或两个以上的接口,那么Lambda表达式就无法表示到执行的是哪个方法,所以就不能被称为函数式接口:

下面我们看看Jaba提供的四大内置核心函数式接口:
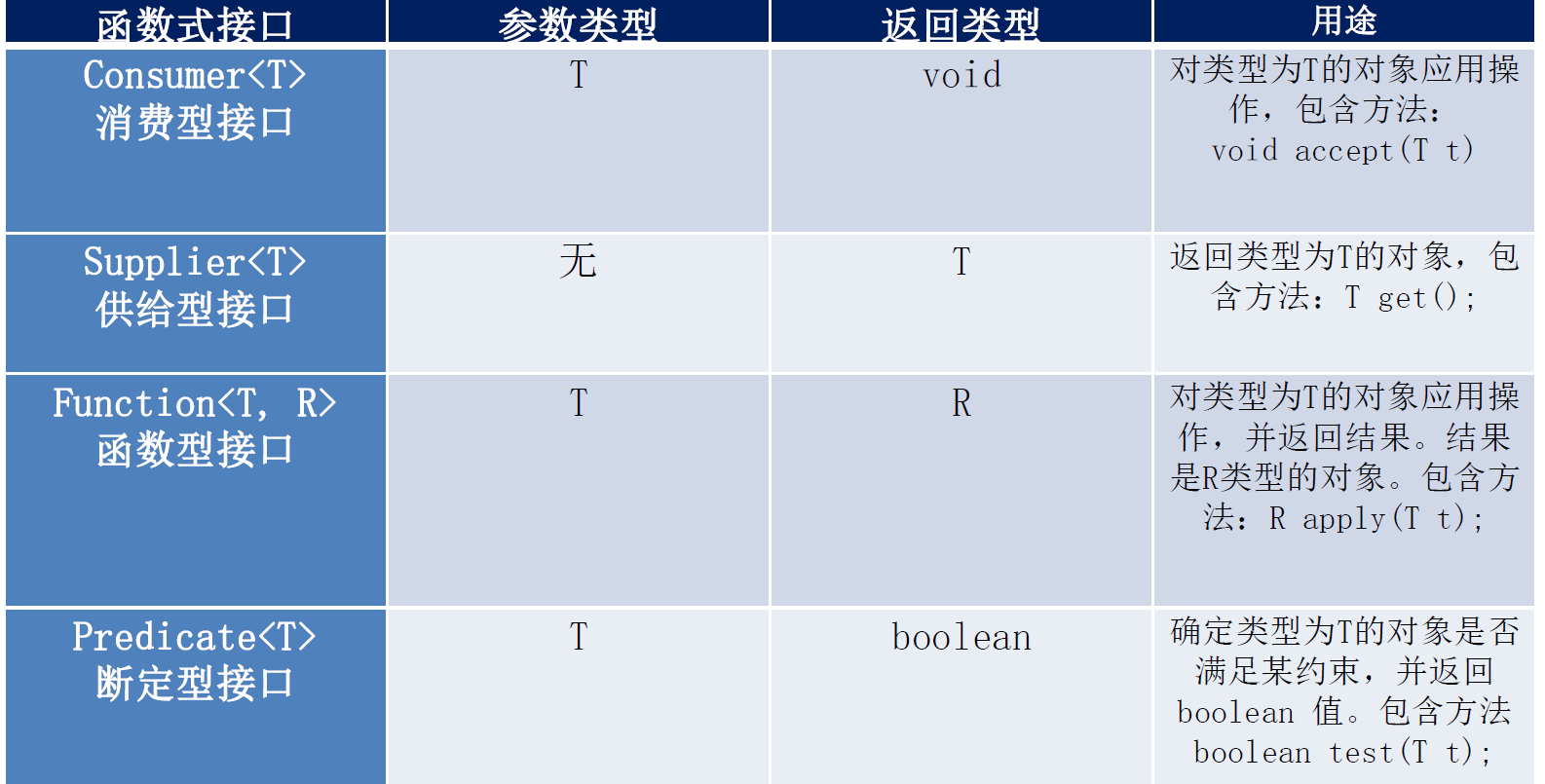
消费型接口:对传入的参数进行操作,并且无返回值
public class LambdaDemo {
public static void main(String[] args) {
consume(100.0, (m)-> System.out.println("旅游消费金额:" + m + "元"));
}
private static void consume(double money, Consumer<Double> consumer) {
consumer.accept(money);
}
}
消费型接口:对传入的参数进行操作,并且无返回值
import java.util.function.Supplier;
public class LambdaDemo {
public static void main(String[] args) {
//Lambda表达式内定义数字的产生方式
List<Integer> integerList = supply(10, () -> (int) (Math.random() * 100));
integerList.forEach(System.out::println);
}
//获得N个数字存入的List
private static List<Integer> supply(int length, Supplier<Integer> supplier) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < length; i++)
list.add(supplier.get());
return list;
}
}
函数型接口:参数类型为T、返回类型是R
public class LambdaDemo {
public static void main(String[] args) {
Integer length = calcLength("Hello", (x) -> x.length());
System.out.println(length);
}
private static Integer calcLength(String string, Function<String, Integer> function) {
return function.apply(string);
}
}
断言型接口:做一些判断操作
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class LambdaDemo {
public static void main(String[] args) {
List<String> stringList = Arrays.asList("And", "Animal", "Basic", "ABC");
List<String> retList = predication(stringList, (x) -> x.startsWith("A"));
for(String str: retList) System.out.print(str + " ");
}
private static List<String> predication(List<String> stringList, Predicate<String> predicate) {
return stringList.stream()
.filter(predicate)
.collect(Collectors.toList());
}
}
其实除了这四大核心函数式接口还有其他的接口:
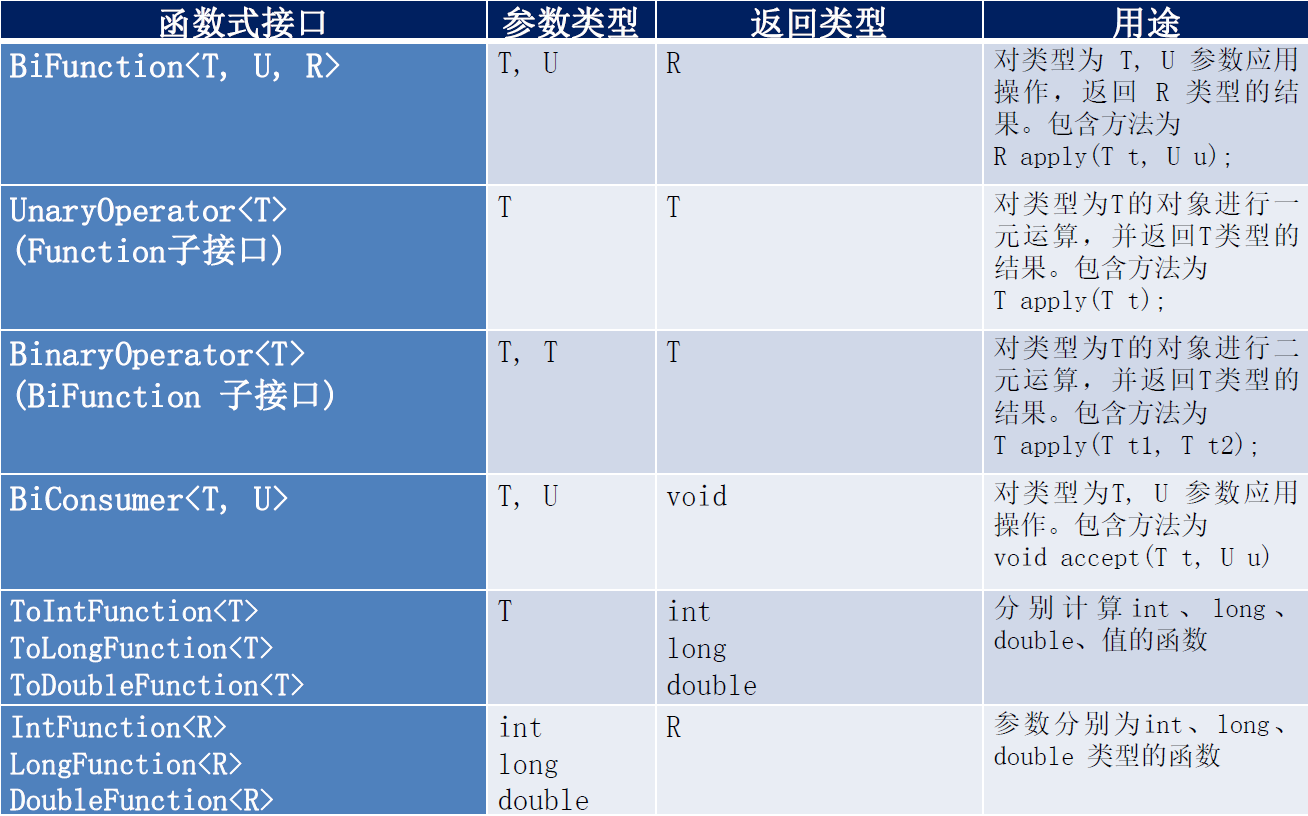
方法引用与构造器引用
方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致! )
方法引用:使用操作符:: 将方法名和对象或类的名字分隔开来。如下三种主要使用情况:
对象 :: 实例方法类 :: 静态方法类 :: 实例方法
下面是 对象::实例方法 这种格式:
import java.util.function.Consumer;
public class MedthodRef {
public static void main(String[] args) {
Consumer<String> consumer = (x) -> System.out.println(x);
Consumer<String> consumer = System.out::println;
}
}
下面是 类::静态方法 这种格式:
import java.util.function.Supplier;
public class MedthodRef {
public static void main(String[] args) {
Supplier<Double> supplier = Math::random;
Comparator<Integer> comparator = Integer::compareTo;
}
}
Lambda体中调用方法的参数列表与返回值类型,要与函数式接口中抽象方法的函数列表和返回值类型保持一致!
下面是 类::实例方法 这种格式:
import java.util.function.BiPredicate;
public class MedthodRef {
public static void main(String[] args) {
BiPredicate<String, String> biPredicate = (x, y) -> x.equals(y);
BiPredicate<String, String> biPredicate = String::equals;
}
}
注意:当需要引用方法的第一个参数是调用对象,并且第二个参数是需要引用方法的第二个参数(或无参数)时:ClassName: :methodName
构造器引用
格式:ClassName::new 与函数式接口相结合,自动与函数式接口中方法兼容。可以把构造器引用赋值给定义的方法,与构造器参数列表要与接口中抽象方法的参数列表一致!
public class Employee {
// 年龄
private int age;
// 薪水
private int salary;
// 姓名
private String name;
public Employee() { }
public Employee(int age, int salary, String name) {
this.age = age;
this.salary = salary;
this.name = name;
}
public Employee(int age) {
this.age = age;
}
public Employee(Integer age, Integer salary) {
this.age = age;
this.salary = salary;
}
// Getter / Setter / toString ...
}
由于构造器参数列表要与接口中抽象方法的参数列表一致,所以我给Employee类加了上述几个构造方法
import java.util.Comparator;
import java.util.function.BiFunction;
import java.util.function.BiPredicate;
import java.util.function.Function;
import java.util.function.Supplier;
public class MedthodRef {
public static void main(String[] args) {
// 自动匹配无参构造器
Supplier<Employee> supplier = Employee::new;
Function<Integer, Employee> function0 = (x) -> new Employee(x);
// 自动匹配Age带参构造器
Function<Integer, Employee> function1 = Employee::new;
Employee employee0 = function1.apply(18);
System.out.println(employee0);
BiFunction<Integer, Integer, Employee> biFunction = Employee::new;
Employee employee1 = biFunction.apply(18, 5500);
System.out.println(employee1);
}
}
数组引用
数组引用其实也是和上面一样的:
import java.util.function.Function;
public class MedthodRef {
public static void main(String[] args) {
Function<Integer, String[]> function = (x) -> new String[x];
Function<Integer, String[]> function = String[]::new;
String[] strings = function.apply(10);
System.out.println(strings.length);
}
}
Stream API
Java8中有两大最为重要的改变。第一个是Lambda 表达式;另外一个则是Stream API(java.util.stream.*)。Stream是Java8中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API对集合数据进行操作,就类似于使用SQL 执行的数据库查询。也可以使用Stream API来并行执行操作。简而言之,StreamAPI提供了一种高效且易于使用的处理数据的方式。
Stream的概念
那么流(Stream)到底是什么呢?其实流可以理解为数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。集合讲的是数据,流讲的是计算!需要注意以下几点:
- Stream自己不会存储元素。
- Stream不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream三个操作步骤
1、创建Stream:一个数据源(如:集合、数组) ,获取一个流
2、中间操作:一个中间操作链,对数据源的数据进行处理
3、终止操作(终端操作):一个终止操作,执行中间操作链,并产生结果
下面是常用的创建的操作:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
/*
* Stream<E> stream() 返回一个顺序流
* Stream<E> parallelStream() 返回一个并行流
*/
public class StreamDemo {
public static void main(String[] args) {
// 1、获取流的第一种方式: stream()获取数组流
List<String> list = new ArrayList<>();
Stream<String> stringStream0 = list.stream();
// 2、获取流的第二种方式:Arrays的静态方法stream()获取数组流
Employee[] employeeArray = new Employee[10];
Stream<Employee> employeeStream = Arrays.stream(employeeArray);
// 3、获取流的第三种方式:通过Stream类中的静态方法of()
Stream<String> stringStream1 = Stream.of("AAA", "BBB", "CCC");
// 4、获取流的第四种方式:创建无限流
// ①迭代的方式
Stream<Integer> integerStream = Stream.iterate(0, (x) -> x + 2);
integerStream.limit(10).forEach(System.out::println);
// ②生成的方式
Stream<Double> doubleStream = Stream.generate(() -> Math.random());
doubleStream.limit(5).forEach(System.out::println);
}
}
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为惰性求值 下面是一些中间操作:

下面是筛选重复对象、根据条件过滤对象的示例:
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim"),
new Employee(25, 8500, "Tim")
);
public static void main(String[] args) {
employeeList.stream()
.filter((x)-> x.getAge() > 20)
.forEach(System.out::println);
System.out.println("----------------");
employeeList.stream()
.distinct()
.forEach(System.out::println);
}
}
那么映射又是什么意思呢?map——接收Lambda,将元素转换成其他形式或提取信息。接收一个函数作为参数, 该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim"),
new Employee(25, 8500, "Tim")
);
public static void main(String[] args) {
List<String> stringList = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee");
stringList.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
System.out.println("-------------------");
employeeList.stream()
.map(Employee::getName)
.forEach(System.out::println);
}
}
如何用Stream排序呢?其实也很简单,在之前的讲解Lambda表达式的例子中我们已经用过了:
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 8500, "Tim"),
new Employee(25, 8500, "Tim")
);
public static void main(String[] args) {
employeeList.stream()
.sorted((x, y) -> {
//年龄一样按照姓名排序
if(x.getAge() == y.getAge()){
return x.getName().compareTo(y.getName());
}else{
return x.getAge() - y.getAge();
}
})
.forEach(System.out::println);
}
}
接下来看看Stream的终止操作,终止操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如: List、Integer, 甚至是void。

接下来看看Stream查找与匹配:
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 3500, "Tim"),
new Employee(25, 3500, "Tim")
);
public static void main(String[] args) {
// 判断是不是所有员工工资都是3500
boolean match = employeeList.stream()
.allMatch((e) -> e.getSalary() == 3500);
System.out.println(match);
// 判断是不是至少有一个员工姓名是Tim
boolean timExist = employeeList.stream()
.anyMatch((e) -> e.getName().equals("Tim"));
System.out.println(timExist);
// 判断是否存在员工年龄小于20
boolean ageMatch = employeeList.stream()
.noneMatch((e) -> e.getAge() < 20);
System.out.println(ageMatch);
// 根据员工工资排序,并得到第一个结果
Optional<Employee> employee = employeeList.stream()
.sorted(Comparator.comparingInt(Employee::getSalary))
.findFirst();
System.out.println(employee.get());
// 获取员工工资最高的员工信息
Optional<Employee> maxEmployee = employeeList.stream()
.max(Comparator.comparingInt(Employee::getSalary));
System.out.println(maxEmployee.get());
// 获取员工最低工资
Optional<Integer> minSalary = employeeList.stream()
.map(Employee::getSalary)
.min(Integer::compareTo);
System.out.println(minSalary);
}
}
接下来看看Stream的归约,归约可以将流中元素反复结合起来,得到一个值。
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 3500, "Tim"),
new Employee(25, 3500, "Tim")
);
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
Integer sum = list.stream()
.reduce(0, (x, y) -> x + y);
System.out.println(sum);
System.out.println("------------------------");
Optional<Integer> salarySum = employeeList.stream()
.map(Employee::getSalary)
.reduce(Integer::sum);
System.out.println(salarySum.get());
}
}
备注: map和reduce的连接通常称为map-reduce 模式,因Google用它来进行网络搜索而出名。
接下来看看收集,Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
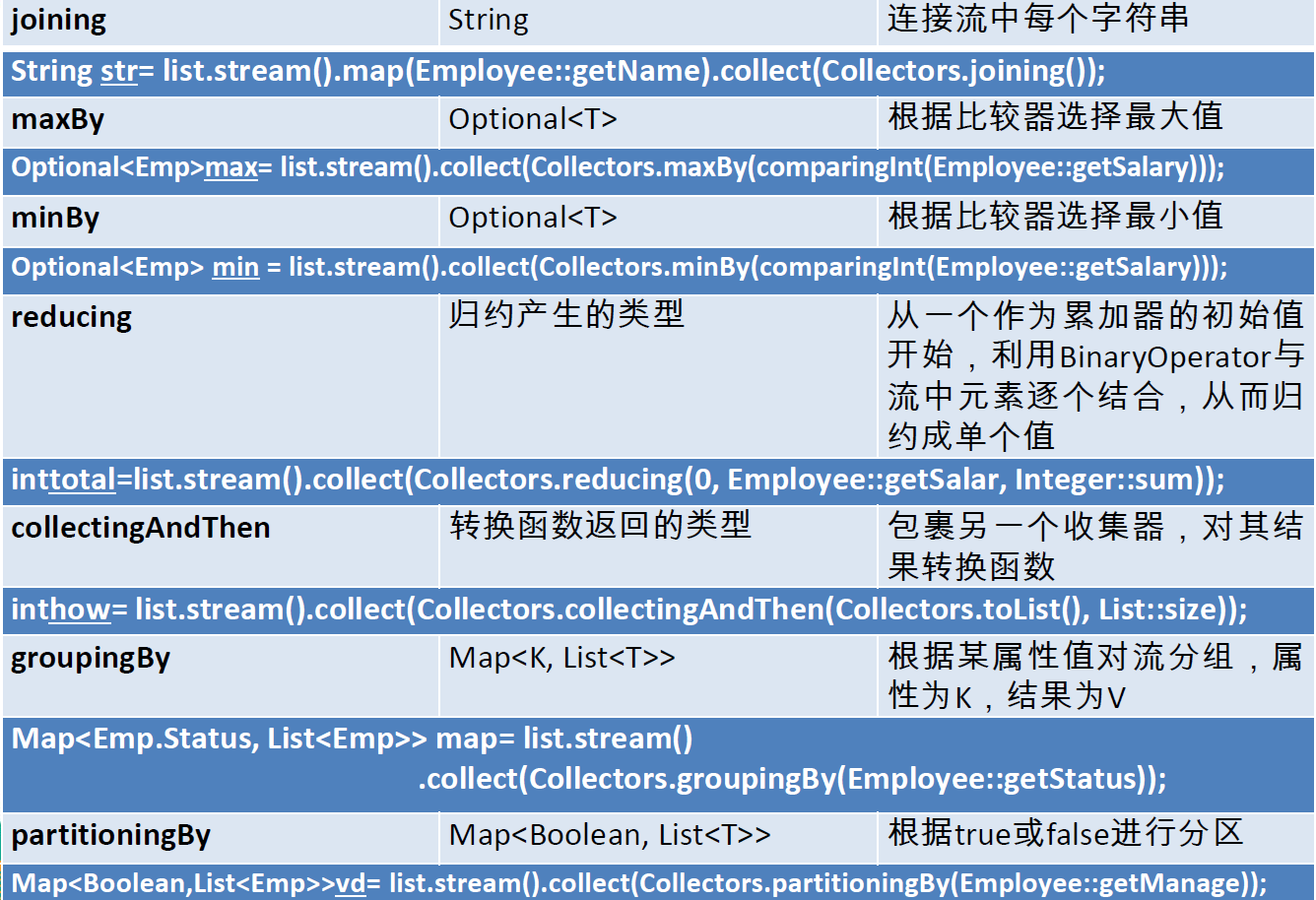
public class StreamDemo {
private static List<Employee> employeeList = Arrays.asList(
new Employee(18, 5500, "Tom"),
new Employee(28, 4500, "Jone"),
new Employee(20, 3500, "Jack"),
new Employee(25, 3500, "Tim"),
new Employee(25, 3500, "Tim")
);
public static void main(String[] args) {
// 收集员工的姓名到List中
List<String> nameList = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toList());
nameList.forEach(System.out::println);
System.out.println("---------------------");
// 收集员工的姓名到Set中
Set<String> nameSet = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
nameSet.forEach(System.out::println);
// 收集员工的姓名到其他结构中
LinkedHashSet<String> linkedHashSet = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(LinkedHashSet::new));
linkedHashSet.forEach(System.out::println);
// 收集员工的工资平均值
Double averageSalary = employeeList.stream()
.collect(Collectors.averagingInt(Employee::getSalary));
System.out.println(averageSalary);
// 收集员工工资总和
Long summarySalary = employeeList.stream()
.collect(Collectors.summingLong(Employee::getSalary));
System.out.println(summarySalary);
}
}
并行流与顺序流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。Java8中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API可以声明性地通过parallel() 与sequential()在并行流与顺序流之间进行切换。
Fork/Join框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若千个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join汇总。关于Fork/Join框架可以看我之前的一篇博客 《 ForkJoin框架与读写锁 》
早在JDK1.7的时候Fork/Join框架就有了,但是使用起来稍微复杂。Fork/Join框架采用“工作窃取” 模式(work-stealing)当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上,在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行。那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行。这种方式减少了线程的等待时间,提高了性能。
import java.util.concurrent.RecursiveTask;
// 一个并行计算的示例
public class ForkJoinCalculate extends RecursiveTask<Long> {
private static final long serialVersionUID = -2761358406351641206L;
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
// 范围
private long start;
private long end;
// 临界值
private static final long THRESHOLD = 10000;
@Override
protected Long compute() {
long length = end - start;
if(length <= THRESHOLD){
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{
// 拆分为子任务
long mid = (end - start) / 2 + start;
ForkJoinCalculate calculateLeft = new ForkJoinCalculate(start, mid);
calculateLeft.fork();
ForkJoinCalculate calculateRight = new ForkJoinCalculate(mid + 1, end);
calculateRight.fork();
return calculateLeft.join() + calculateRight.join();
}
}
}
测试性能:
package newjdk8.forkjoin;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream;
public class TestForkJoinCalculate {
public static void main(String[] args) {
// 计算500亿的累加
long n = 50000000000L;
forkJoinTest(n); //8723毫秒
oneThreadCalc(n); //14337毫秒
streamCalc(n); //4375毫秒
}
private static void streamCalc(long n) {
Instant start = Instant.now();
long reduce = LongStream.range(0, n)
.parallel()
.reduce(0, Long::sum);
System.out.println(reduce);
Instant end = Instant.now();
System.out.println("Stream " + Duration.between(start, end).toMillis());
}
private static void oneThreadCalc(long n) {
Instant start = Instant.now();
long sum = 0L;
for (long i = 0; i <= n; i++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("单线程 " + Duration.between(start, end).toMillis());
}
private static void forkJoinTest(long n) {
Instant start = Instant.now();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> forkJoinTask = new ForkJoinCalculate(0, n);
Long sum = pool.invoke(forkJoinTask);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("Fork/Join " + Duration.between(start, end).toMillis());
}
}
注意:parallel并行流底层就是使用了Fork/Join框架
Option尽量避免空指针
Optional<T>类(java. util. Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存在,现在Optional可以更好的表达这个概念。并且可以避免空指针异常。

Option这种容器在SpringDataJpa中经常用到,所以在此不再记述。
接口中的默认方法与静态方法
接口中的默认方法
Java 8中允许接口中包含具有具体实现的方法,该方法称为默认方法,默认方法使用default 关键字修饰。我觉得JDK8出现了函数式接口,为了兼容JDK7所以出现了default修饰的接口级别的默认方法。
public interface MyFunc{
default String getName(){
return "HelloWorld";
}
}
public class MyCLass implements MyFunc {
}
public class Test {
public static void main(String[] args) {
MyFunc myFunc = new MyCLass();
System.out.println(myFunc.getName()); // HelloWorld
}
}
接口默认方法的类优先原则:若一个接口中定义了一个默认方法,而另外一个父类或接口中又定义了一个同名的方法时:
- 选择父类中的方法。如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。
- 接口冲突。如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法),那么必须覆盖该方法来解决冲突。
public interface MyFunc{
default String getName(){
return "HelloWorld";
}
}
public class MyCLass implements MyFunc {
public String getName(){
return "MyClass";
}
}
public class Test {
public static void main(String[] args) {
MyFunc myFunc = new MyCLass();
System.out.println(myFunc.getName()); // MyClass
}
}
那么如果有两个接口应该怎么办呢?
MyFunc.java
public interface MyFunc{
default String getName(){
return "HelloWorld";
}
}
MyFunc2.java
public interface MyFunc2 {
default String getName(){
return "HelloWorld2";
}
}
MyClass.java,因为不知道该用谁的默认方法,所以报错
public class MyCLass implements MyFunc, MyFunc2 {
//Error 因为不知道该用谁的默认方法
}
MyCLass.Java ,以下两种解决方案:
public class MyCLass implements MyFunc, MyFunc2 {
@Override
public String getName() {
// 1、要么就指定用谁的
return MyFunc.super.getName();
}
@Override
public String getName() {
// 2、要么就实现自己的
return "MyClass";
}
}
接口中的静态方法
这个其实没啥好说的,就是接口中允许存在静态方法:
MyFunc.java
public interface MyFunc{
static void show(){
System.out.println("Show Static Method");
}
}
Test.java
public class Test {
public static void main(String[] args) {
MyFunc.show();
}
}
新时间日期API
LocalDate、LocalTime、 LocalDateTime 类的实例是不可变的对象,分别表示使用ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息,且也不包含与时区相关的信息。
比如我们比较常用的SimpleDateFormat,这个我们经常使用的类存在线程安全问题:
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.*;
public class TestSimpleDateFormat {
public static void main(String[] args) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
ExecutorService executorService = Executors.newFixedThreadPool(10);
Callable<Date> callable = () -> format.parse("2020-04-17");
List<Future<Date>> futureList = new ArrayList<>();
for (int i = 0; i < 20; i++) {
futureList.add(executorService.submit(callable));
}
for(Future<Date> dateFuture: futureList){
System.out.println(dateFuture.get());
}
executorService.shutdown();
}
}
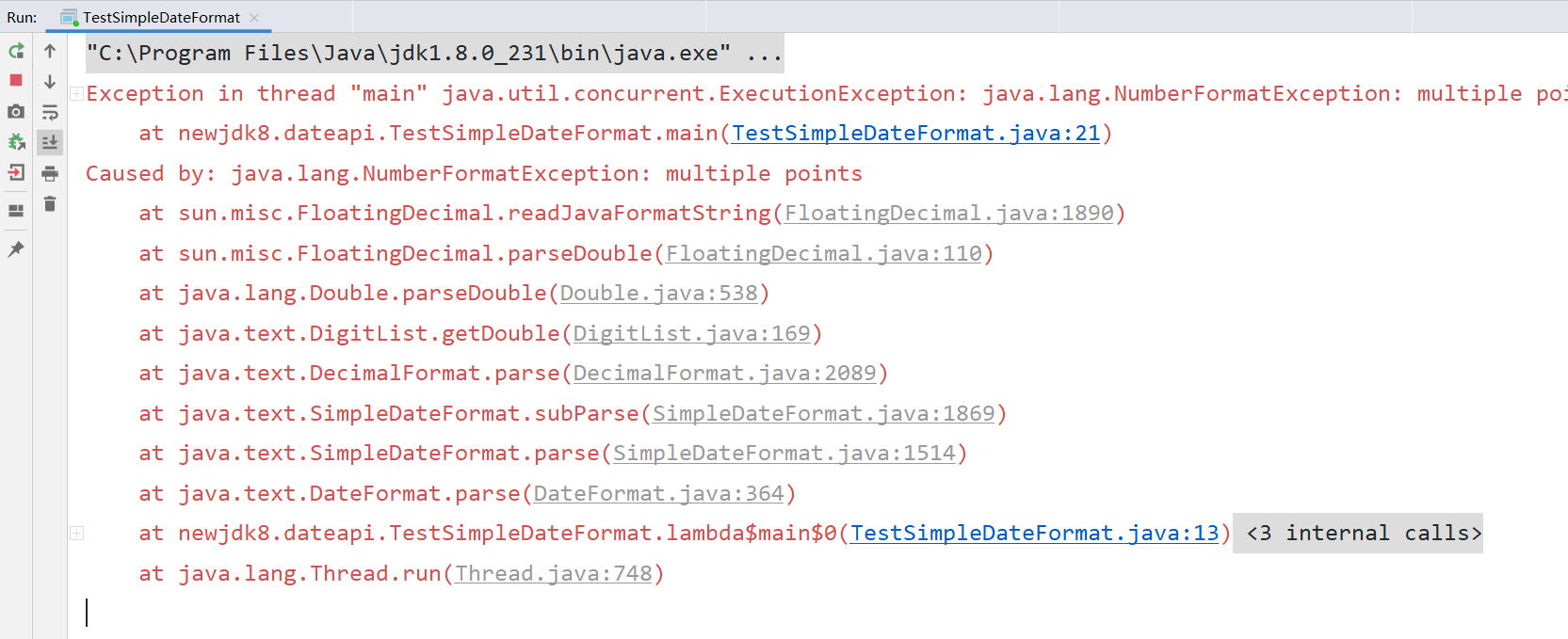
我们可以用ThreadLocal,DateFormatThreadLocal.java
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateFormatThreadLocal {
private static final ThreadLocal<DateFormat> df = new ThreadLocal<DateFormat>(){
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyy-MM-dd");
}
};
public static Date convert(String source) throws ParseException {
return df.get().parse(source);
}
}
这样的话我们只需要按照如下方式使用即可:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.*;
public class TestSimpleDateFormat {
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Callable<Date> callable = () -> DateFormatThreadLocal.convert("2020-04-17");
List<Future<Date>> futureList = new ArrayList<>();
for (int i = 0; i < 20; i++) {
futureList.add(executorService.submit(callable));
}
for(Future<Date> dateFuture: futureList){
System.out.println(dateFuture.get());
}
executorService.shutdown();
}
}
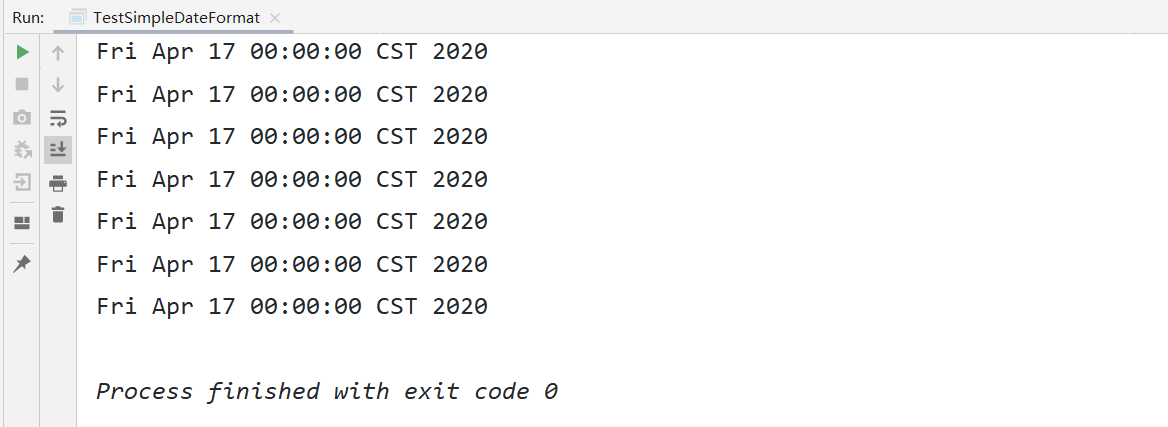
现在,我们不需要使用ThreadLocal来辅助了,直接用LocalDate这个线程安全的工具来搞定,就和String一样,线程安全,无论做出怎么样的改变都会产生一个新的实例对象:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.*;
public class TestSimpleDateFormat {
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(10);
//DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ISO_LOCAL_DATE;
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
Callable<LocalDate> callable = () -> LocalDate.parse("2020-04-17", dateTimeFormatter);
List<Future<LocalDate>> futureList = new ArrayList<>();
for (int i = 0; i < 20; i++) {
futureList.add(executorService.submit(callable));
}
for(Future<LocalDate> dateFuture: futureList){
System.out.println(dateFuture.get());
}
executorService.shutdown();
}
}
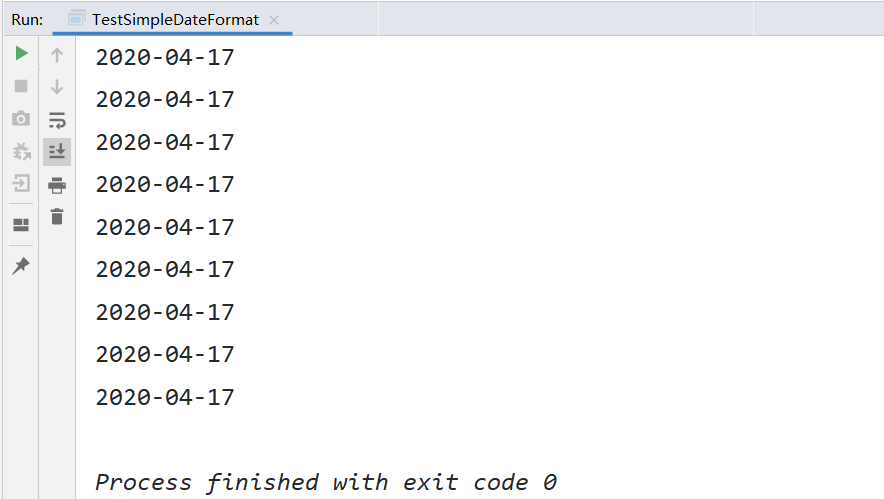
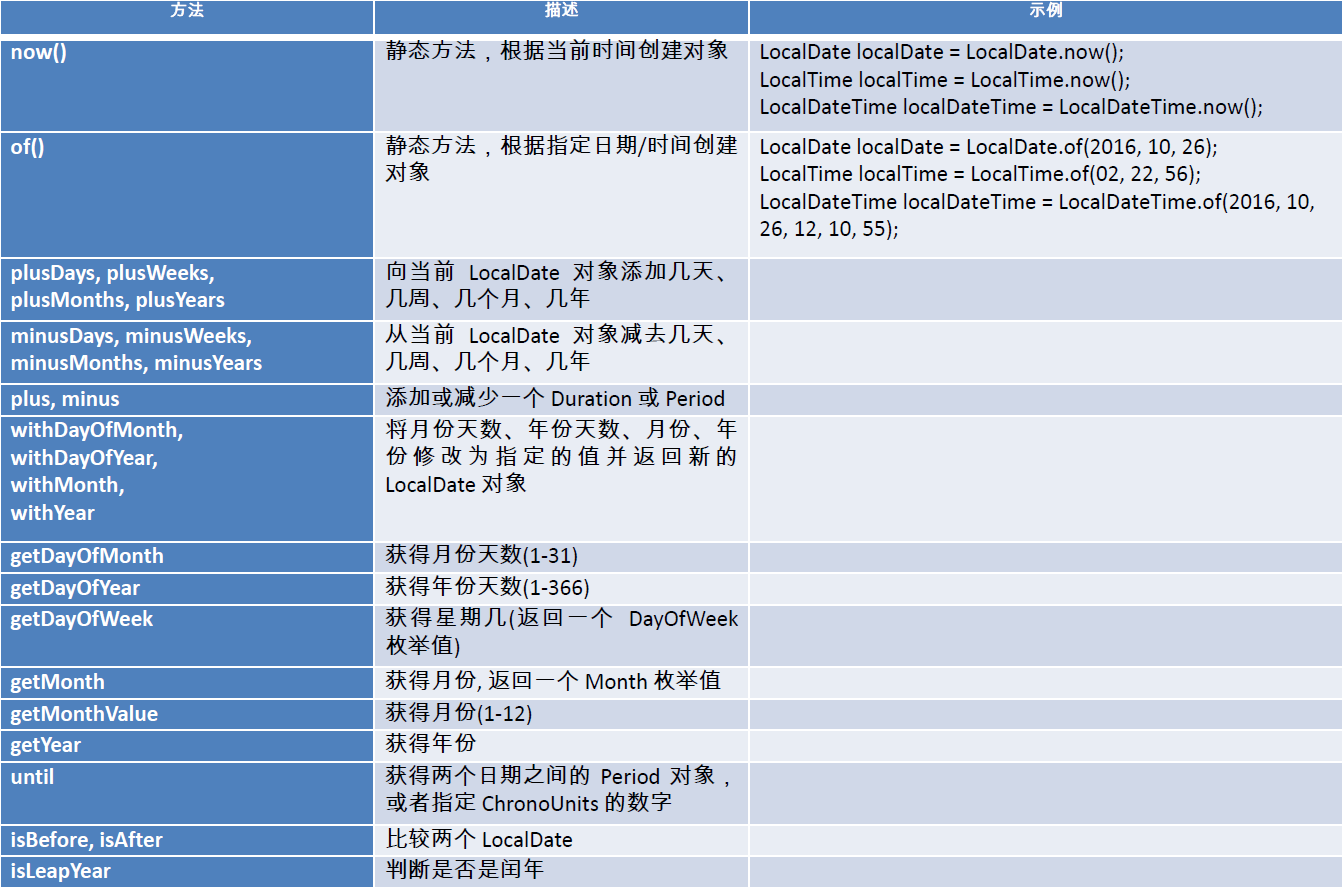
下面是这些API的使用示例:
Duration:用于计算两个时间间隔。 Period:用于计算两个日期间隔。
Instant时间戳用于时间戳的运算。它是以Unix元年(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的描述进行运算。
TemporalAdjuster:时间校正器。有时我们可能需要获取例如:将日期调整到下个周日等操作。
TemporalAdjusters:该类通过静态方法提供了大量的常用TemporalAdjuster的实现。
java.time.format.DateTimeFormatter类:该类提供了三种格式化方法:
- 预定义的标准格式
- 语言环境相关的格式
- 自定义的格式
Java8中加入了对时区的支持,带时区的时间为分别为:ZonedDate、ZonedTime、 ZonedDateTime 其中每个时区都对应着ID,地区ID都为{区 域}/{城市}的格式,例如: Asia/Shanghai等
- Zoneld:该类中包含了所有的时区信息
- getAvailableZonelds():可以获取所有时区时区信息
- of(id):用指定的时区信息获取Zoneld对象
import java.time.DayOfWeek;
import java.time.Duration;
import java.time.Instant;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.OffsetDateTime;
import java.time.Period;
import java.time.ZoneId;
import java.time.ZoneOffset;
import java.time.ZonedDateTime;
import java.time.format.DateTimeFormatter;
import java.time.temporal.TemporalAdjusters;
import java.util.Set;
import org.junit.Test;
public class TestLocalDateTime {
// ZonedDate、ZonedTime、ZonedDateTime:带时区的时间或日期
@Test
public void test7(){
LocalDateTime ldt = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
System.out.println(ldt);
ZonedDateTime zdt = ZonedDateTime.now(ZoneId.of("US/Pacific"));
System.out.println(zdt);
}
@Test
public void test6(){
Set<String> set = ZoneId.getAvailableZoneIds();
set.forEach(System.out::println);
}
// DateTimeFormatter : 解析和格式化日期或时间
@Test
public void test5(){
//DateTimeFormatter dtf = DateTimeFormatter.ISO_LOCAL_DATE;
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss E");
LocalDateTime ldt = LocalDateTime.now();
String strDate = ldt.format(dtf);
System.out.println(strDate);
LocalDateTime newLdt = ldt.parse(strDate, dtf);
System.out.println(newLdt);
}
// TemporalAdjuster : 时间校正器
@Test
public void test4(){
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt);
LocalDateTime ldt2 = ldt.withDayOfMonth(10);
System.out.println(ldt2);
LocalDateTime ldt3 = ldt.with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
System.out.println(ldt3);
//自定义:下一个工作日
LocalDateTime ldt5 = ldt.with((l) -> {
LocalDateTime ldt4 = (LocalDateTime) l;
DayOfWeek dow = ldt4.getDayOfWeek();
if(dow.equals(DayOfWeek.FRIDAY)){
return ldt4.plusDays(3);
}else if(dow.equals(DayOfWeek.SATURDAY)){
return ldt4.plusDays(2);
}else{
return ldt4.plusDays(1);
}
});
System.out.println(ldt5);
}
// Duration : 用于计算两个“时间”间隔
// Period : 用于计算两个“日期”间隔
@Test
public void test3(){
Instant ins1 = Instant.now();
System.out.println("--------------------");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
Instant ins2 = Instant.now();
System.out.println("所耗费时间为:" + Duration.between(ins1, ins2));
System.out.println("----------------------------------");
LocalDate ld1 = LocalDate.now();
LocalDate ld2 = LocalDate.of(2011, 1, 1);
Period pe = Period.between(ld2, ld1);
System.out.println(pe.getYears());
System.out.println(pe.getMonths());
System.out.println(pe.getDays());
}
// Instant : 时间戳(使用 Unix元年1970年1月1日 00:00:00 所经历的毫秒值)
@Test
public void test2(){
Instant ins = Instant.now(); //默认使用 UTC 时区
System.out.println(ins);
OffsetDateTime odt = ins.atOffset(ZoneOffset.ofHours(8));
System.out.println(odt);
System.out.println(ins.getNano());
Instant ins2 = Instant.ofEpochSecond(5);
System.out.println(ins2);
}
// LocalDate、LocalTime、LocalDateTime
@Test
public void test1(){
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt);
LocalDateTime ld2 = LocalDateTime.of(2016, 11, 21, 10, 10, 10);
System.out.println(ld2);
LocalDateTime ldt3 = ld2.plusYears(20);
System.out.println(ldt3);
LocalDateTime ldt4 = ld2.minusMonths(2);
System.out.println(ldt4);
System.out.println(ldt.getYear());
System.out.println(ldt.getMonthValue());
System.out.println(ldt.getDayOfMonth());
System.out.println(ldt.getHour());
System.out.println(ldt.getMinute());
System.out.println(ldt.getSecond());
}
}
重复注解与类型注解
Java 8对注解处理提供了两点改进:可重复的注解及可用于类型的注解。
假设现在我有如下注解:
import static java.lang.annotation.ElementType.*;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
String value() default "Tim";
}
测试如下,像下面这种重复注解是不被允许的:
package newjdk8.dateapi.annotation;
public class TestAnnotation {
@MyAnnotation("AAA")
@MyAnnotation("BBB") // Error!
public void show(){
}
}
那么如何解决这个问题呢?我们还需要定义一个注解容器:
MyAnnotations.java
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import static java.lang.annotation.ElementType.*;
import static java.lang.annotation.ElementType.LOCAL_VARIABLE;
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotations {
MyAnnotation[] value();
}
MyAnnotation.java
import static java.lang.annotation.ElementType.*;
import java.lang.annotation.Repeatable;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Repeatable(MyAnnotations.class) // 指定容器
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
String value() default "Tim";
}
TestAnnotation.java
import java.lang.reflect.Method;
public class TestAnnotation {
public static void main(String[] args) throws NoSuchMethodException {
Class<TestAnnotation> annotationClass = TestAnnotation.class;
Method method = annotationClass.getMethod("show");
MyAnnotation[] myAnnotations = method.getAnnotationsByType(MyAnnotation.class);
for (MyAnnotation myAnnotation: myAnnotations){
System.out.println(myAnnotation.value());
}
}
@MyAnnotation("Hello")
@MyAnnotation("World")
public void show(){
}
}
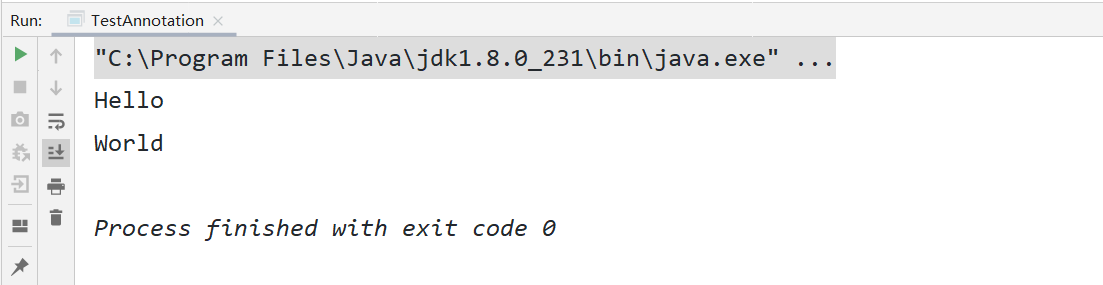
什么是类型注解呢?Target支持TYPE_PARAMETER,我们通过源码也是可以看到起始于JDK1.8
@Repeatable(MyAnnotations.class) // 指定容器
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE, TYPE_PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
String value() default "Tim";
}
/**
* Type parameter declaration
*
* @since 1.8
*/
TYPE_PARAMETER
那么就可以对类型进行注解:
public class TestAnnotation {
@MyAnnotation("Hello")
@MyAnnotation("World")
// 可以注解类型
public void show(@MyAnnotation("abc") String str){
}
}