Flink流式计算与批处理 —— 词频统计
也是因为最近处理业务上的问题,如果我希望看到某些实时数据的变化那么必然会涉及到流式计算,大数据处理框架从原始的 MapReduce、Hive 到 DAG的Tez,再到Spark的近实时处理是一个不断进化的过程,对于要求更高的场景还是Apache Flink比较在行,Apache Flink是一个带状态的流式计算框架,Flink不但能进行流式计算,也能进行批处理,也就是离线计算。下面是最近两天学习Flink的一些笔记,后面会逐步完善和校正。
大数据处理计算模式概览
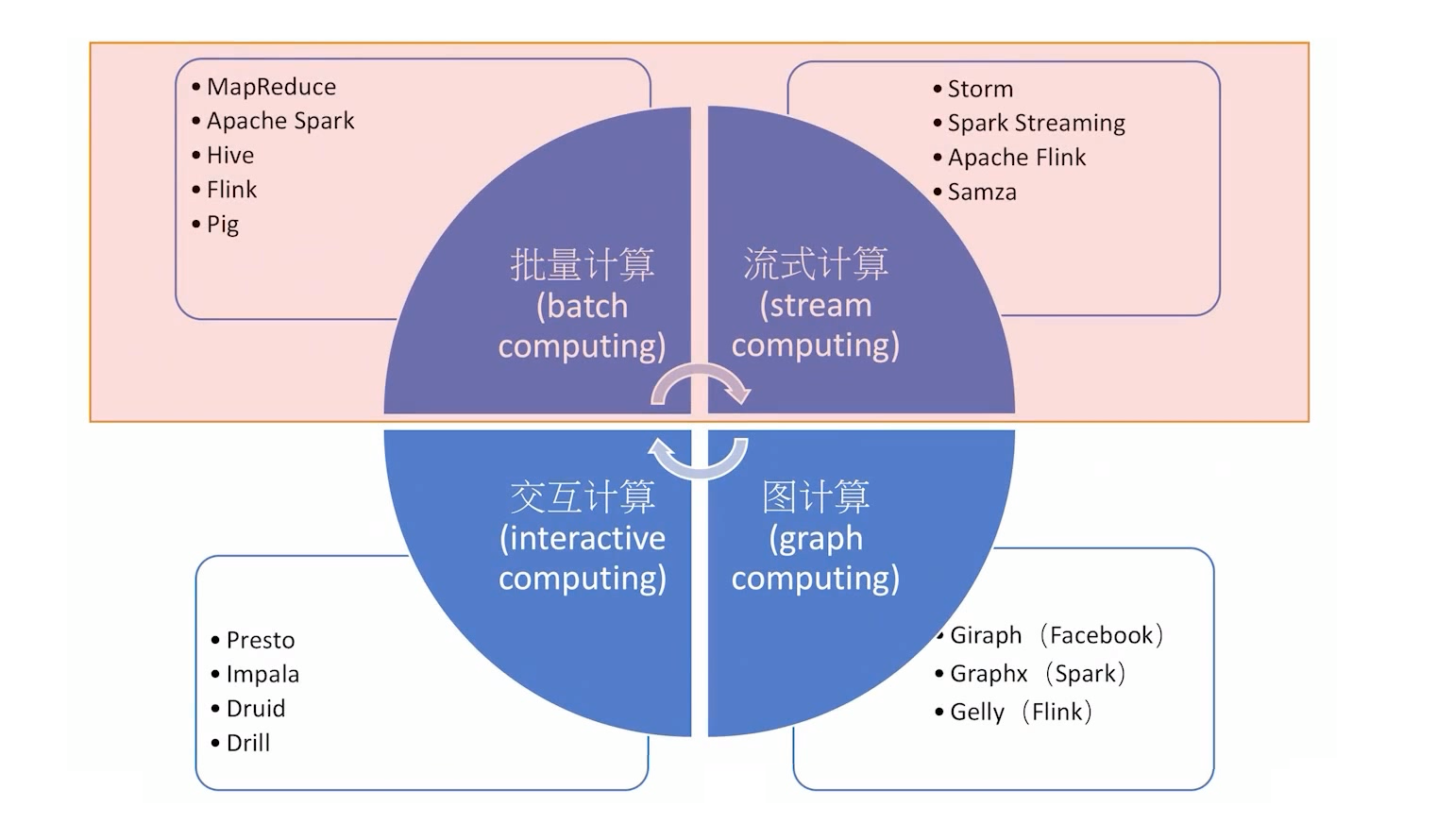
流计算与批计算对比:
1、数据时效性不同:流式计算实时、低延迟,批量计算非实时、高延迟。
2、数据特征不同:流式计算的数据一般是动态的、没有边界的,而批处理的数据一般则是静态数据。
3、应用场景不同:流式计算应用在实时场景,时效性要求比较高的场景,如实时推荐、业务监控等批量计算一般 批处理应用在实时性要求不高、离线计算的场景下,数据分析、离线报表等。
4、运行方式不同:流式计算的任务持续进行的,批量计算的任务则一次性完成。
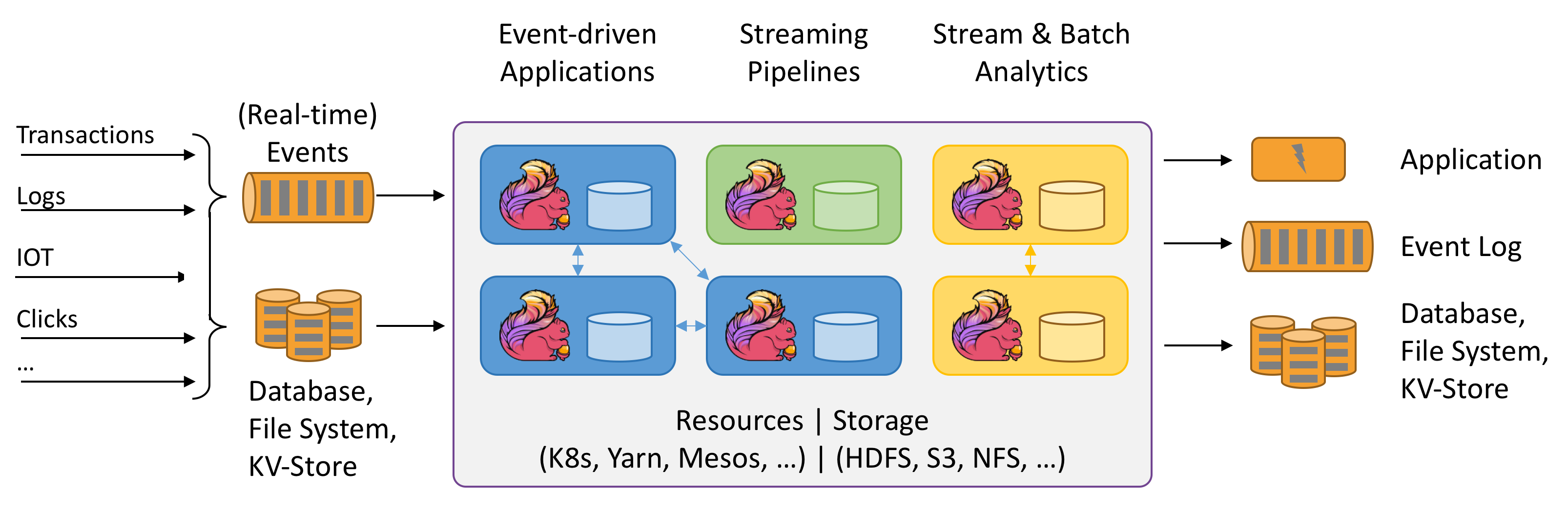
Apache Flink 概览
上图来自 Apache Flink 官网: https://flink.apache.org/ , 其实最好的学习途径就是先看官方文档,没有人比官方文档更加清晰易懂,看完了之后简单总结一下:
从上图得知:
1、数据来源与计算形式:Flink的数据来源可以是业务数据、日志、IOT采集数据、点击数据(可以理解为行为交互数据),实时事件数据支持流式计算,同时也支持从DB、KV、File中读取批量数据进行批处理。
2、事件驱动、支持数据管道 & ETL
3、支持 Hadoop Yarn、Apache Mesos、K8S部署,水平扩展性强,支持的的数据存储形式HDFS、NFS
4、处理完后的数据同样可以输出到应用、Log、DB或者KV
5、Flink 具备低延迟、高吞吐、基于内存计算等特点

Flink核心特性
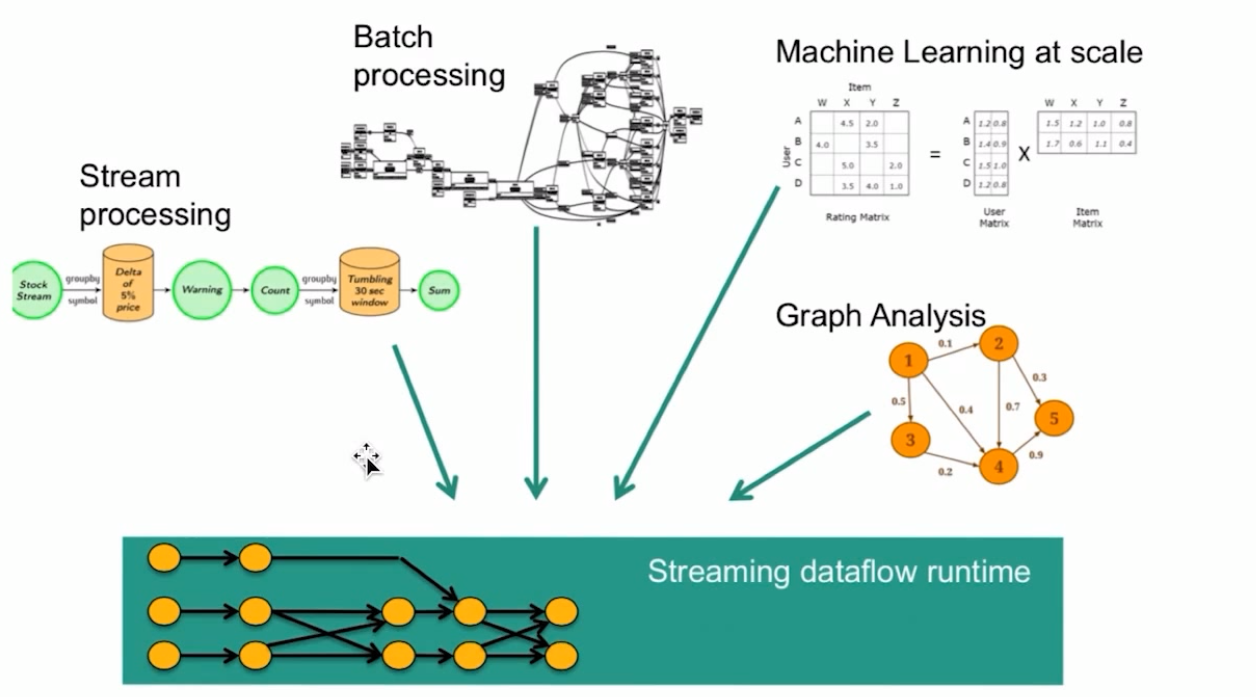
1、统一数据处理组件栈,处理不同类型的数据需求,包括流计算、批处理、机器学习相关、图计算
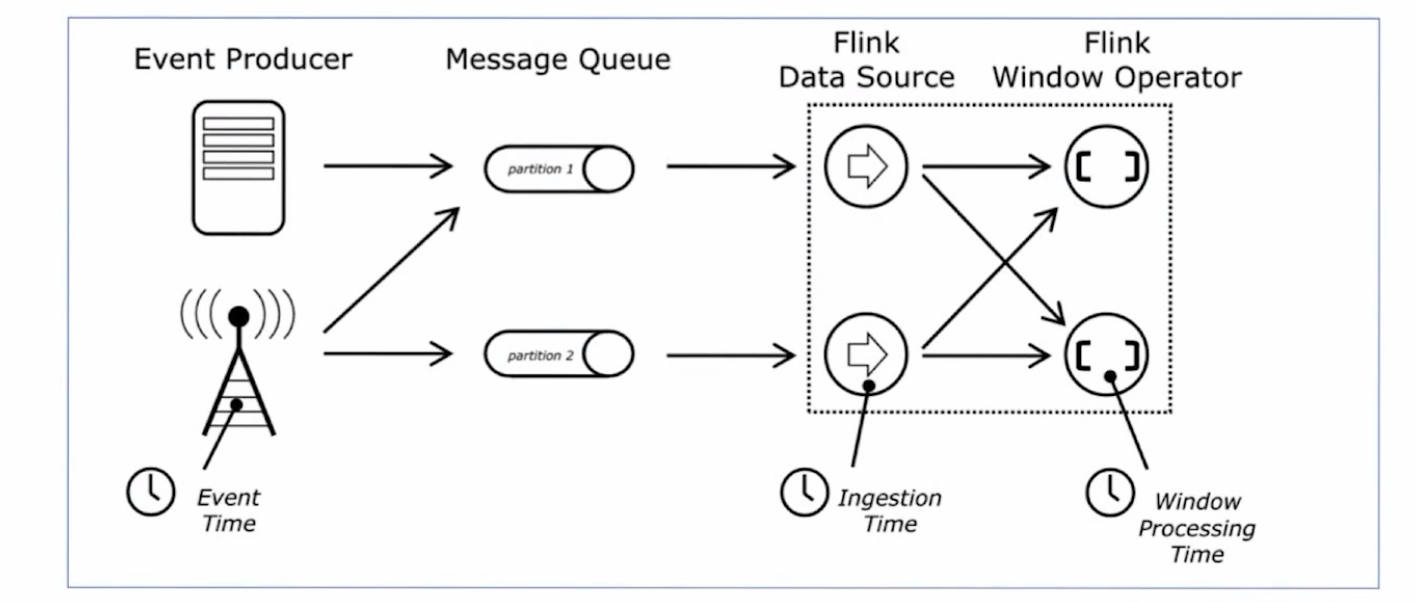
2、时间模式:支持事件时间(Event Time),接入时间(Ingestion Time),处理时间(ProcessingTime)等时间概念
3、基于轻量级分布式快照的实现的容错机制
4、支持有状态计算:状态是 Flink 中的一等公民,Flink提供了多种状态类型:list、map、value
5、支持高度灵活的窗口操作
6、带反压的连续流支持,下游算子处理速度跟不上的时候通过Flow Control将信号传递给上游算子
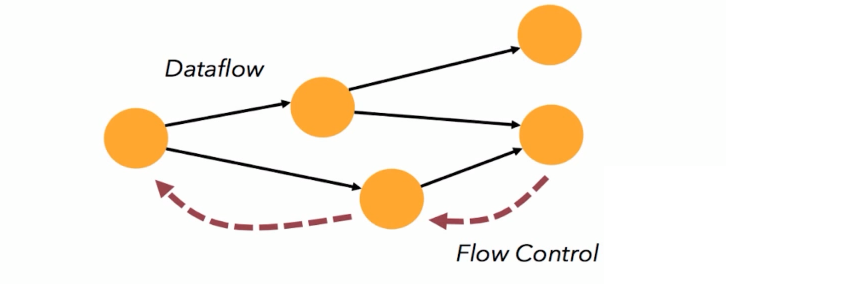
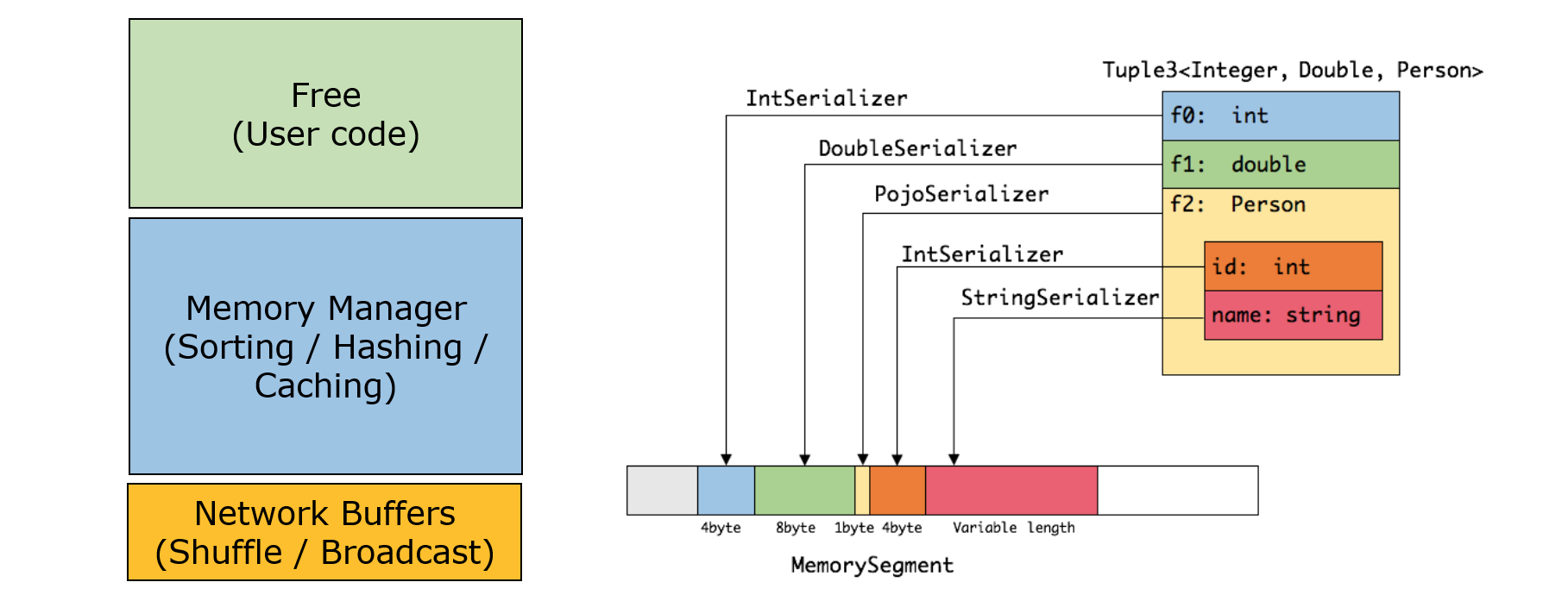
7、基于JVM实现了独立的内存管理,只存储实际数据的二进制内容,节省空间,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对高速缓存更友好 ,提升性能的同时, 减少了Full GC和OOM的发生
8、分层次API:Table API / SQL 、 DataStream API ( 流操作的原语支持,Java 和 Scala )、 ProcessFunction
有界流 & 无界流概念
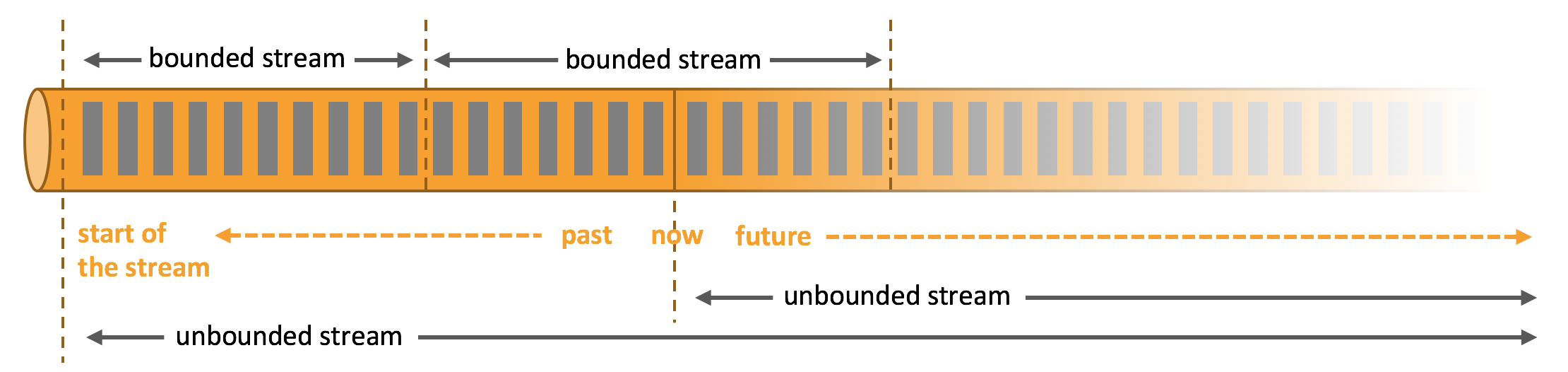
有界流 & 无界流在Flink中属于特别重要的概念,对于离线计算来讲,就是处理的有界流,也叫做批处理。流式计算通常来讲就是处理的无界流,即只有开始,没有结束,从运行的那一刻起就需要不断处理来自数据源的新数据。
构建Flink工程
Maven Archetype 构建
首先通过Maven来建立一个简易Flink工程,通过 Maven Archetype 的构建方式:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.14.4 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
这样即可得到了一个示例工程,里面的依赖和示例代码可以参考,通过也有log4j的配置文件。
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 拿数据
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
// 处理数据
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
// 结果写回
alerts
.addSink(new AlertSink())
.name("send-alerts");
env.execute("Fraud Detection");
}
}
从上面的示例代码中可以的得到一个Flink编程范式,即拿数据、处理数据、再到结果输出的过程:
1、对接数据源 2、使用引擎进行逻辑处理 3、结果写回某处/输出
MR:InputFormat => Mapper => Reducer => ……
Hive:Table(s) => SQL =>insert…
Spark:RDD/DF/DS => Transaction> Action/Output
Flink:Source => Transaction => Sink / CH
这一点对于大部分大数据处理框架来说都是大同小异的!
Maven 模块化构建
第二个构建工程的方式就是 Maven modules 多模块方式构建,IDEA 直接新建 module即可,Maven子模块想要用父工程的依赖管理,首先在父工程的dependencyManagement 中定义好依赖(注意需要去掉依赖的作用域 scope),子工程再逐个引入(去除version、scope等信息),子工程不用再关心版本问题。
子工程 pom.xml
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
</dependency>
</dependencies>
父工程 pom.xml
<dependencyManagement>
<dependencies>
<!-- This dependency is provided, because it should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
Flink统计词频Demo
流式计算统计词频
对于流式计算得先找到一个数据流,这里简单用 nc 命令代替,nc 式类Unix下的一款非常强大的网络工具库,通过命令行输入如下命令就可以建立Socket服务并且通过终端把字符串发送至客户端:
root@ubuntu:~# nc -lk 9527
hello,hello,world,flink,flink,hello
hello,hello,world,flink,flink,hello
这里9527是服务监听的端口号。
SteamingWCApp.java
package cn.tim.flink;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 基于 Flink 流式处理 —— 词频统计
* 结合 Linux nc命令(功能强大的网络工具)作为 socket 数据流来源
* nc -lk 9527
* hello,hello,world,flink,flink,hello
*/
public class SteamingWCApp {
public static void main(String[] args) throws Exception {
// 上下文 -> 流处理的上下文
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 对接数据源,对接 Socket数据
DataStreamSource<String> source = env.socketTextStream("192.168.31.32", 9527);
// 业务逻辑处理
source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> out) throws Exception {
String[] words = s.split(",");
for(String word: words) {
out.collect(word.toLowerCase().trim());
}
}
}).filter(new FilterFunction<String>() { // 空字符串过滤
@Override
public boolean filter(String s) throws Exception {
return StringUtils.isNotEmpty(s);
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
})
// .keyBy(0).sum(1) // 已过时:第一个位置做keyBy -> 0, 对第二个位置做求和操作 -> 1
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.sum(1)
.print();
env.execute("SteamingWCApp");
/*
* 7> (world,1)
* 4> (hello,1)
* 10> (flink,1)
* 10> (flink,2)
* 4> (hello,2)
* 4> (hello,3)
*/
}
}
批处理统计词频
Flink同样支持批处理,在统计词频的这个问题中,示例数据写在了 data/word.data这个文本文件里,内容就是一些单词,data/word.data 如下:
flink,flink,hello,world,flink
flink,flink,hello,world,flink
flink,flink,hello,world,flink
BatchWCApp.java
package cn.tim.flink;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 离线计算 —— 词频统计
*/
public class BatchWCApp {
public static void main(String[] args) throws Exception {
// 离线计算环境 -> 批处理的上下文
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文集读文本数据
DataSource<String> source = env.readTextFile("data/word.data");
// 设置过滤器和算子
source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] words = s.split(",");
for(String word: words) {
collector.collect(word.toLowerCase().trim());
}
}
}).filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return StringUtils.isNotEmpty(s);
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
}).groupBy(0)
.sum(1)
.print();
/*
* (flink,9)
* (world,3)
* (hello,3)
*/
// 批处理无需exec
}
}
Github 对应代码仓库: https://github.com/zouchanglin/apache-flink/tree/main/modules-flink/flink-basic