Java内存模型的回顾

本篇文章主要讲述了Java内存模型中的程序计数器、虚拟机栈、本地方法栈、元空间与堆,以及堆中的常量池。前面通过javap反编译class文件得到int add(int a, int b)函数的栈帧,主要分析了栈帧中JVM指令对应的局部变量表、操作数栈、程序计数器的状态变化。以及JDK7以后出现了替代永久代的元数据区,并分析了元数据区替换了永久代有哪些好处,主要分析了给字符串常量池带来的影响,并通过代码验证了元数据区相比永久代的优越性。学习了JVM性能调优的三个参数的意义和普通用法,最后探讨了并验证了JDK1.6与JDK1.7+的版本String类的intern方法的不同表现结果,分析了出现不同结果的原因,其实主要是JDK1.6的版本是建立副本再放入字符串常量池,而JDK1.7+版本时直接把堆上的对象的引用入池。
线程私有的空间
程序计数器( Program Counter Register )
1、当前线程所执行的字节码行号指示器(逻辑)
2、改变计数器的值来选取下一条需要执行的字节码指令
3、和线程是一对一的关系即:线程私有
4、对Java方法计数,如果是Native方法则计数器值为Undefined
5、由于只是对指令行号进行计数,所以不会发生内存泄漏
Java虚拟机栈(Stack)
Java虚拟机栈是Java方法执行的内存模型,包含多个栈帧,栈帧里面有哪些内容呢?
局部变量表、操作栈、动态链接、返回地址等。局部变量表包含了方法执行过程中的所有变量。操作数栈主要是:入栈、出栈、复制、交换、产生消费变量。
public class ByteCodeSimple {
public static int add(int a, int b){
int c = 0;
c = a + b;
return c;
}
}
通过javac编译出class文件,再通过javap -verbose ByteCodeSimple.class编译出如下内容:

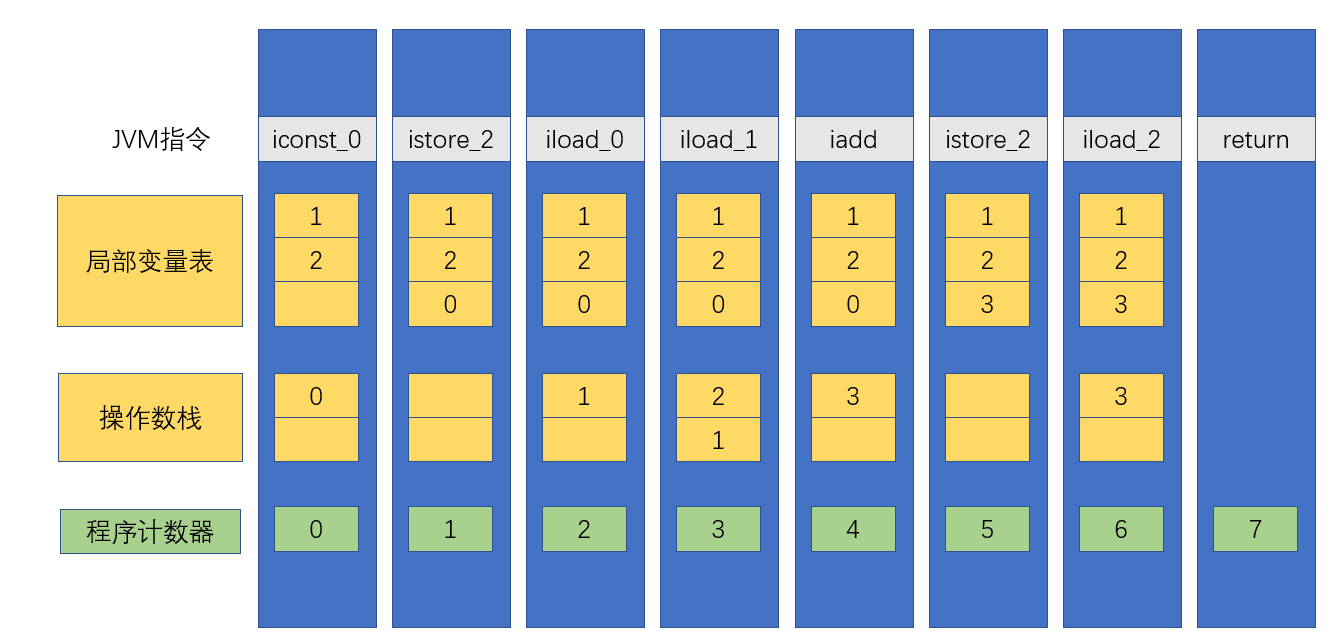
每一个蓝色的长方形就代表了一个栈帧的存在状态,对应上面的代码,总共有7个栈帧状态图。
iconst指令就是将操作数0压入操作数栈中,入参为1,2因此局部变量表就是1和2。istore指令的意思就是把操作数栈的元素给pop出来,放入局部变量表的第二个变量中(因为是istore_2),iload_0就是将局部变量表中第0个的元素压入到操作数栈当中,接着又把局部变量表中第1个元素压入到操作数栈中,接着执行iadd指令(将操作数栈中的元素取出来,执行相加的操作,将结果放回栈顶),接着把栈顶的结算结果弹栈,放到局部变量表中的第二个变量里面,然后再次把局部变量表中的第二个变量放到操作数栈当中。最后调用ireturn这个指令把栈顶的元素给返回,最后执行的是销毁栈帧。
所以可以看出调用一个Java方法就是需要建立栈帧,如果递归层数过多,超出虚拟机栈的深度限制,就会引发java.lang.StackOverFlowError异常。
另一个异常就是java.lang.OutOfMemoryError,虚拟机栈过多会引发java.lang.OutOfMemoryError异常,如要尝试可以使用如下代码,Windows测试之前请备份好重要文档
public void stackLeakByThread(){
while (true){
new Thread(() -> {
while (true){
}
}).start();
}
}
本地方法栈,与虚拟机栈相似,主要作用于标注了native的方法。
线程共享的空间
先说说MetaSpace(元空间)与永久代的区别:
首先,得明白方法区只是JVM的一个规范,而MetaSpace和永久代均是方法区的实现,在Java7之后,原先位于方法区的字符串常量池已经被移动到了堆中,并且在JDK8以后,使用MetaSpace替代了永久代。不仅仅只是名字上的替代:
1、元空间使用本地内存,而永久代使用的是JVM的内存,使用本地内存有什么好处呢?那就是默认的类的元数据分配只受到本地内存大小的限制,解决了空间不足的问题, 所有的被intern的String被存储在PermGen的串常量池中,解决了以前在老版本的JDK中出现的OutOfMemoryError的问题,JVM默认在运行的时候会根据需要动态的设置其大小。
2、字符串常量池存在永久代中,容易出现性能问题和内存溢出
3、永久代会为GC带来不必要的复杂性
4、方便HotSpot与其他JVM如Jrockit的集成
堆这个空间其实就是存放对象实例用的(当然也包括数组和字符串常量池)。Java堆空间可以处于物理上不连续的空间,只要逻辑是连续的即可。
JVM三大性能调优参数
-Xms、-Xmx、-Xss
-Xss 规定了每个线程虚拟机栈的大小,一般来说256K足够用了,此配置将会影响并发线程数的大小
-Xms 堆的初始值,即进程刚创建时的堆的大小,一旦除过了堆的初始容量,将会自动扩容
-Xmx 堆能达到的最大值
通常情况下我们将 -Xms 和 -Xmx 设置成一样的,因为当堆内存不够用的时候,会发生扩容,此时会产生内存抖动,影响程序运行时的稳定性。
内存分配策略
1、静态存储:编译时确定每个数据目标在运行时的存储空间需求
2、栈式存储:数据区需求在编译时未知,运行时模块入口前确定,如:虚拟机栈
3、堆式存储:编译时或运行时模块入口都无法确定,动态分配,如:对象的存储和销毁
Java内存模型中堆和栈的区别
1、管理方式:栈自动释放,堆需要GC
2、空间大小:栈比堆小
3、碎片相关:栈产生的碎片远小于堆
4、分配方式:栈支持静态和动态分配,而堆仅支持动态分配
5、效率:栈的效率比堆高
不同JDK版本的intern()
String对象的intern方法就是把字符串放入字符串常量池中。
JDK6:当调用intern方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,将此字符串对象添加到字符串常量池中,并且返回该字符串对象的引用。
JDK6+:当调用intern 方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,如果该字符串对象已经存在于Java堆中,则将堆中对此对象的引用添加到字符串常量池中,并且返回该引用;如果堆中不存在,则在池中创建该字符串并返回其引用。
先演示一个OutOfMemoryError:PermGen space的例子
下面是一个一直向常量池中放入随机字符串的程序示例:
public class PermGenErrTest {
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
getRandomString(1000000).intern();
}
System.out.println("success");
}
private static String getRandomString(int length) {
String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random = new Random();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < length; i++) {
int num = random.nextInt(62);
stringBuilder.append(str.charAt(num));
}
return stringBuilder.toString();
}
}
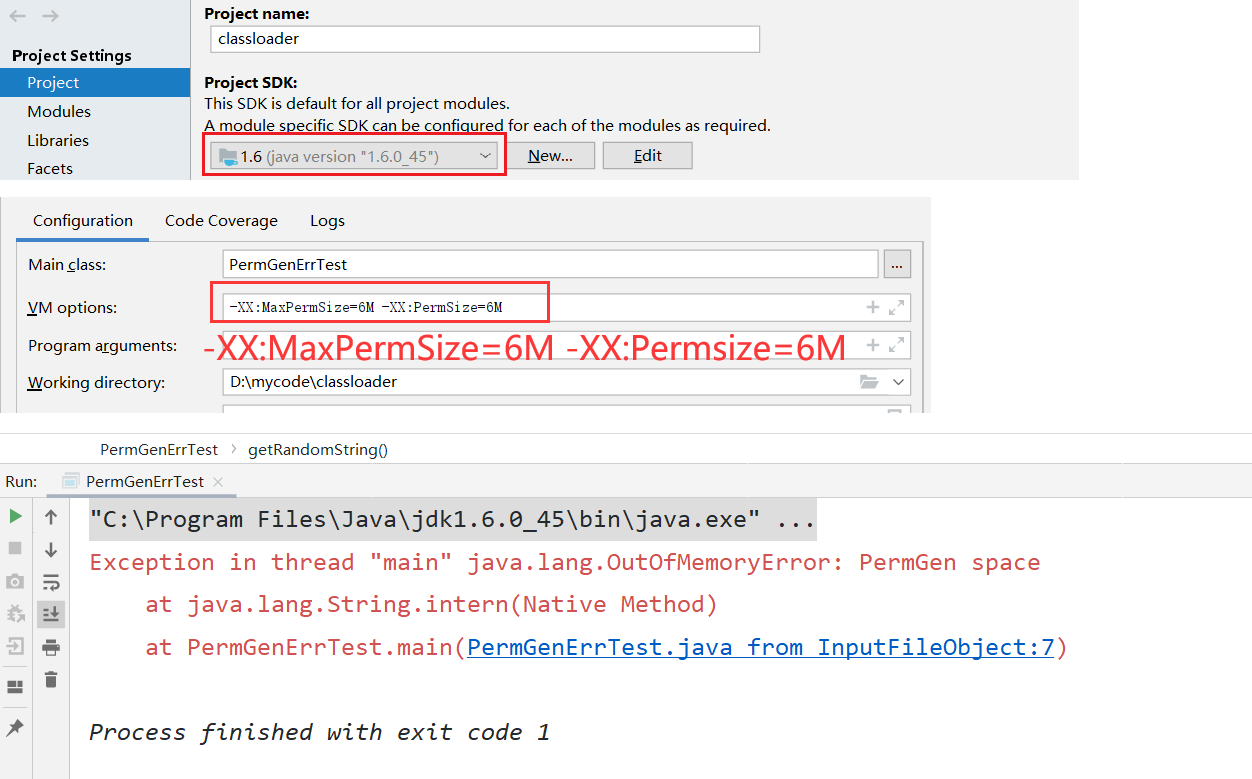
我的JDK版本选择了JDK1.6,并且配置了永久代的初始大小为6M,而且最大为6M,然后一直往常量池里面放字符串,最终出现了OutOfMemoryError:PermGen space,那么如果是换成JDK1.7+呢?

可以看到成功执行完毕,而且JDK1.7+是不受MaxPerSize这个参数的限制的,因为已经移除了永久代。
不同JDK版本的intern()
对于JDK1.6会输出什么?JDK1.7+呢?
public class InternDifference {
public static void main(String[] args) {
String s1 = new String("a");
s1.intern();
String s2 = "a";
System.out.println(s1 == s2);
String s3 = new String("a") + new String("a");
s3.intern();
String s4 = "aa";
System.out.println(s3 == s4);
}
}
对于JDK1.7+,输出结果是false、true
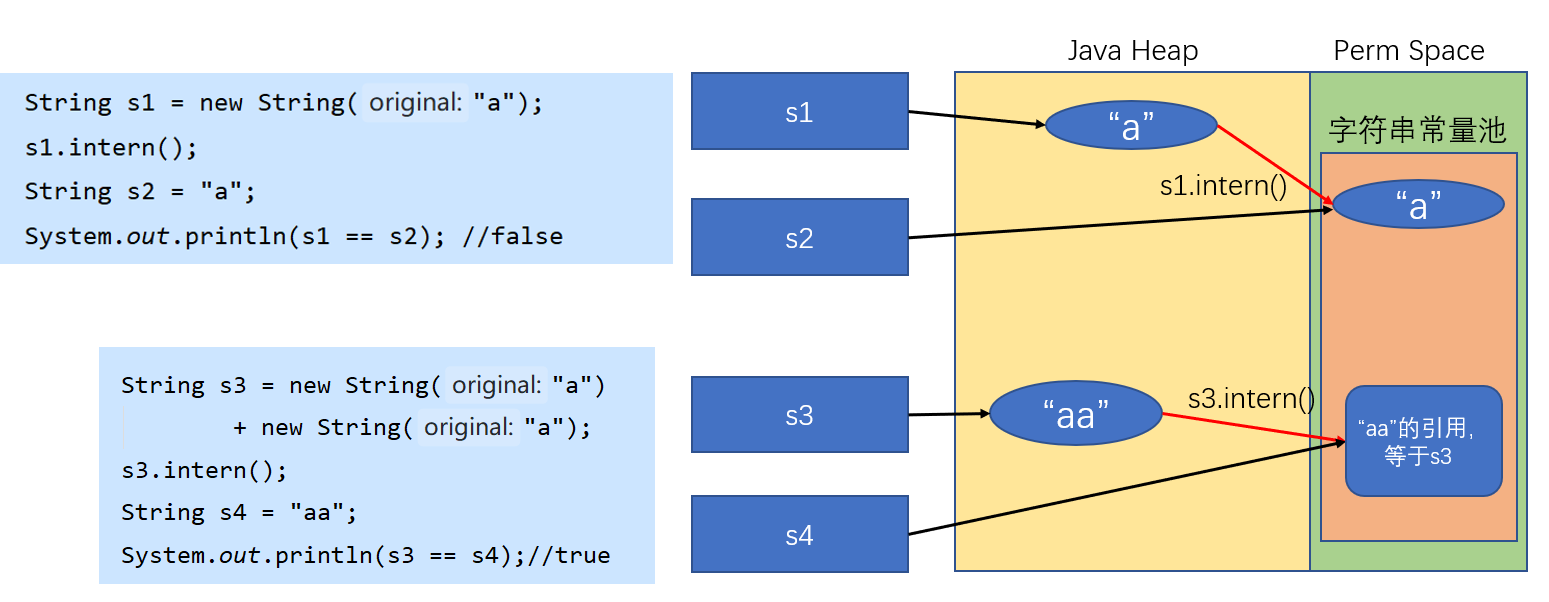
String s = new String(“a”)的时候, “a”会被首先创建,放入字符串常量池中,然后new出的对象放在堆中,在调用intern()的时候,会尝试将字符串对象放入字符串常量池中,但是发现字符串常量池中已经有了,就不能放了,在String s2 = “a"的时候,会先在常量池中寻找有没有对应的字符串,如果有,就直接返回它的引用。所以s1 == s2 比较的是字符串常量池中的"a” 的地址和堆中对象的地址,肯定是flase。在String s3 = new String(“a”) + new String(“a”),字符串常量池是不会创建“aa”这个字符串的,因为“”中只有单个a,所以在调用intern()的时候,会尝试将“aa”也就是堆中的那个字符串对象的引用放入常量池中,并将该引用返回,由于这两个都是同一个地址引用,于是s3==s4是true。
对于JDK1.6,输出结果是false、false**
String s1 = new String(“a”)的时候, “a”会被首先创建,放入字符串常量池中,然后new出的对象放在堆中,在调用intern()的时候,会尝试将字符串对象放入字符串常量池中,但是发现字符串常量池中已经有了,就不能放了,在String s2 = “a"的时候,会先在常量池中寻找有没有对应的字符串,如果有,就直接返回它的引用。所以s1 == s2 比较的是字符串常量池中的"a” 的地址和堆中对象的地址,肯定是flase。 在String s3 = new String(“a”) + new String(“a”),字符串常量池是不会创建“aa”这个字符串的,因为“”中只有单个a,所以在调用intern()的时候,会尝试将“aa”也就是堆中的那个字符串对象放入常量池中,并返回字符串常量池中“aa”的引用,但是由于常量池中放的相当于是一个对象副本,当返回它的引用时,地址是永久区的,因此s3和s4不会相等。