select、poll和epoll多路复用
Nginx和Redis中都用到了epoll多路复用模型,本节将讲述常见的多路复用模型:select、poll和epoll,以及部分示例代码,还是先回顾IO的两个重要过程:
任何IO过程中,都包含两个步骤:第一是等待,第二是拷贝。而且在实际的应用场景中,等待消耗的时间往往都远远高于拷贝的时间。让IO更高效,最核心的办法就是让等待的时间尽量少。
在以前的文章中介绍了五种IO模型,分别是阻塞式IO、非阻塞式IO、信号驱动IO、多路复用IO、异步IO;前四种都属于同步IO。今天重点介绍的是多路复用IO,多路复用IO通俗讲就是一次等待多个文件描述符,减少了等待时间,提高了IO过程的效率(此IO过程并不是只是从内核态到用户态数据的拷贝,而是从发起IO请求直到IO完成的过程),接下来将介绍Linux的三种多路复用模型。
非阻塞IO
在介绍多路复用IO之前,先看看非阻塞IO吧:一个文件描述符,默认都是阻塞IO,我们可以通过fcntl函数来将文件描述符设置为非阻塞
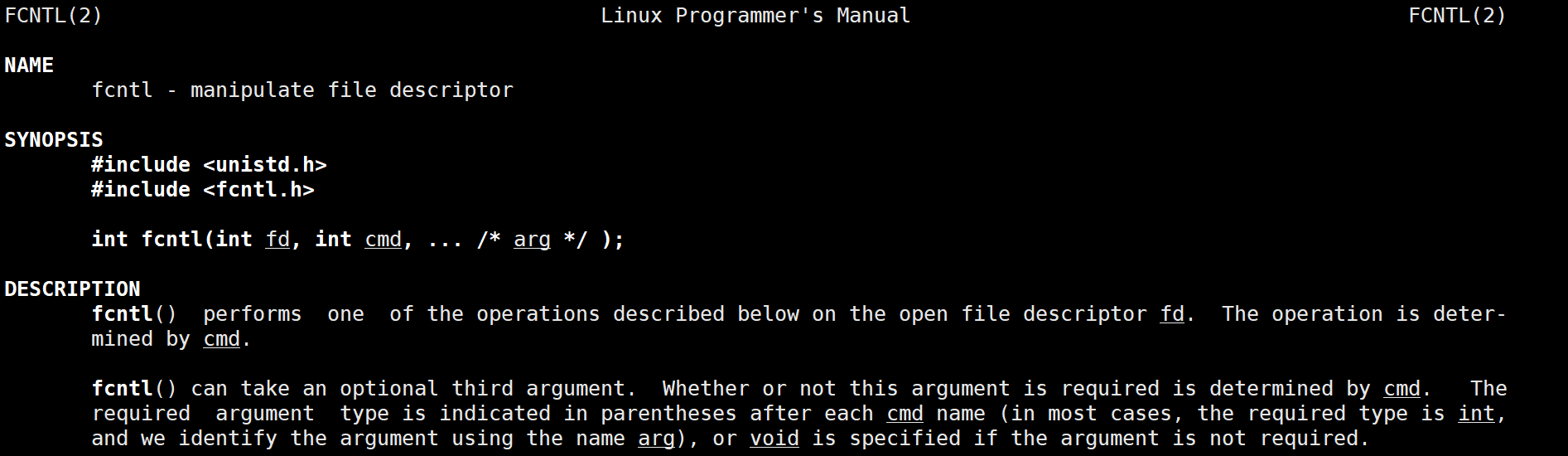
传入的cmd的值不同,后面追加的参数也不相同。fcntl函数有5种功能:
- 复制一个现有的描述符(cmd=F_DUPFD)
- 获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD).
- 获得/设置文件状态标记(cmd=F_GETFL或F_SETFL).
- 获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN).
- 获得/设置记录锁(cmd=F_GETLK,F_SETLK或F_SETLKW).
我们此处只是用第三种功能,获取/设置文件状态标记,就可以将一个文件描述符设置为非阻塞。对fcntl封装实现一个将文件描述符更改为非阻塞的功能:

使用F_GETFL将当前的文件描述符的属性取出来(这是一个位图),然后再使用F_SETFL将文件描述符设置回去。设置回去的同时,加上一个O_NONBLOCK参数。下面使用轮询方式读取标准输入:

select 多路复用
系统提供select函数来实现多路复用输入/输出模型,select系统调用是用来让我们的程序监视多个文件描述符的状态变化的;程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变;
select函数
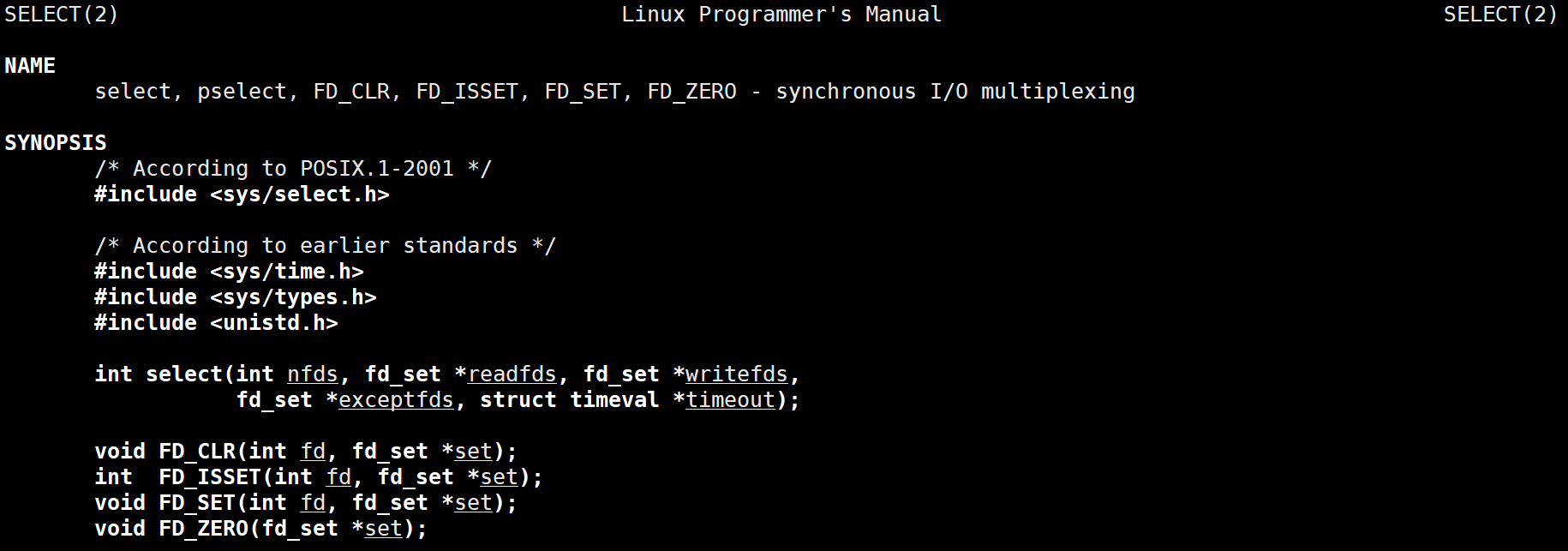
参数nfds是需要监视的最大的文件描述符值+1;rdset、wrset、exset分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集合及异常文件描述符的集合;参数timeout为结构timeval,用来设置select()的等待时间
- NULL:则表示select()没有timeout,select将一直被阻塞,直到某个文件描述符上发生了事件;
- 0:仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发生。
- 特定的时间值:如果在指定的时间段里没有事件发生,select将超时返回。
void FD_CLR(int fd, fd_set *set) 用来清除描述词组set中相关fd的位 int FD_ISSET(int fd, fd_set *set) 用来测试描述词组set中相关fd的位是否为真 void FD_SET(int fd, fd_set *set) 用来设置描述词组set中相关fd的位 void FD_ZERO(fd_set *set) 用来清除描述词组set的全部位
select 函数返回值:执行成功则返回文件描述词状态已改变的个数;如果返回0代表在描述词状态改变前已超过timeout时间,没有返回;当有错误发生时则返回-1,错误原因存于errno,此时参数readfds,writefds,exceptfds和timeout的值变成不可预测。
错误值可能为:
- EBADF 文件描述词为无效的或该文件已关闭
- EINTR 此调用被信号所中断
- EINVAL 参数n为负值
- ENOMEM 核心内存不足
select特点
可监控的文件描述符个数取决与sizeof(fd_set)的值,我的服务器上sizeof(fd_set)=128,每bit表示一个文件 描述符,则我服务器上支持的最大文件描述符是128*8=1024。fd_set的大小可以调整,可能涉及重新编译内核。
int main(){
printf("%lu\n", sizeof(fd_set)); //128
return 0;
}
将fd加入select监控集的同时,还要再使用一个数据结构array保存放到select监控集中的fd,一是用于再select 返回后,array作为源数据和fd_set进行FD_ISSET判断。二是select返回后会把以前加入的但并无事件发生的fd清空,则每次开始select前都要重新从array取得fd逐一加入(FD_ZERO最先),扫描array的同时取得fd最大值maxfd,用于select的第一个参数。
select缺点
每次调用select, 都需要手动设置fd集合, 从接口使用角度来说也非常不便,每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大,同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大,select支持的文件描述符数量太小。
使用select监控stdin
#include <stdio.h>
#include <stdbool.h>
#include <unistd.h>
#include <zconf.h>
int main(){
fd_set read_fds;
//清除全部标志位
FD_ZERO(&read_fds);
FD_SET(0, &read_fds);
while (true){
printf(">");
fflush(stdout);
int ret = select(1, &read_fds, NULL, NULL, NULL);
if(ret < 0){
perror("select");
continue;
}
if(FD_ISSET(0, &read_fds)){
char buf[1024] = {0};
read(0, buf, sizeof(buf) - 1);
printf("input:%s\n", buf);
} else{
printf("error!");
continue;
}
FD_ZERO(&read_fds);
FD_SET(0, &read_fds);
}
return 0;
}

poll 多路复用
poll函数
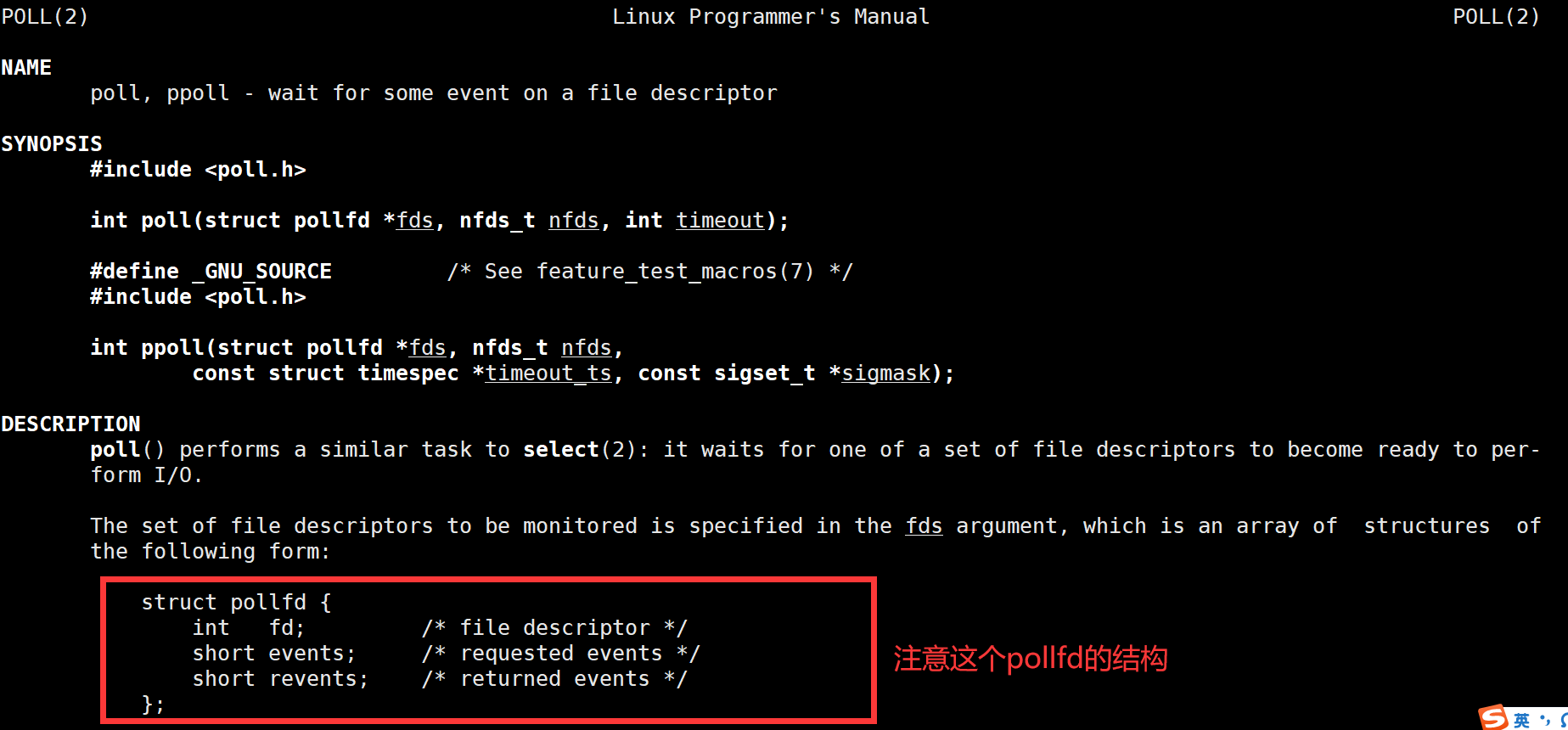
对于poll这个系统函数来说,fds是一个poll函数监听的结构列表。每一个元素中,包含了三部分内容:文件描述符,监听的事件集合,返回的事件集合。nfds表示fds数组的长度,timeout表示poll函数的超时时间,单位是毫秒(ms)。
下面是events和revents的取值
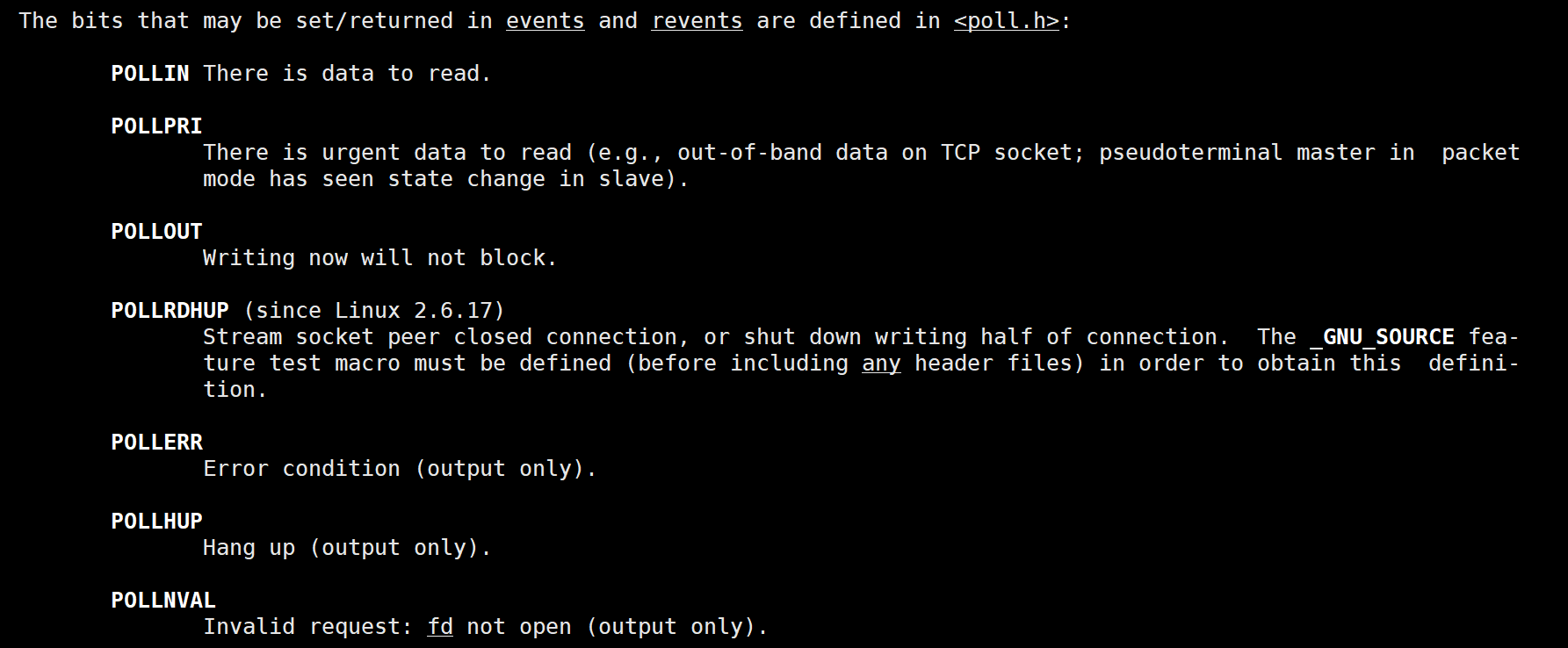
返回值:返回值小于0,表示出错;返回值等于0,表示poll函数等待超时;返回值大于0,表示poll由于监听的文件描述符就绪而返回。
poll特点
不同与select使用三个位图来表示三个fdset的方式,poll使用一个pollfd的指针实现,pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式(因为select三个集合简直要命),接口使用比select更方便。poll并没有最大数量限制 (但是数量过大后性能也是会下降),因为列表长度可以任意长,当然指的是内存充足的情况下;
poll缺点
poll中监听的文件描述符数目增多时,和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符,每次调用poll都需要把大量的pollfd结构从用户态拷贝到内核中。同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
使用poll监控stdin
#include <stdio.h>
#include <stdbool.h>
#include <unistd.h>
#include <zconf.h>
#include <poll.h>
int main(){
struct pollfd poll_fd;
poll_fd.fd = 0;
poll_fd.events = POLLIN;//数据可读事件
while (true){
int ret = poll(&poll_fd, 1, 1000);
if(ret < 0){
perror("poll");
continue;
}
if(ret == 0){
printf("poll timeout\n");
continue;
}
if(poll_fd.revents == POLLIN){
char buf[1024] = {0};
read(0, buf, sizeof(buf) - 1);
printf("stdin:%s\n", buf);
}
}
return 0;
}
epoll 多路复用
按照man手册的说法: 是为处理大批量句柄而作了改进的poll,它是在2.5.44内核中被引进的,对于有大量的连接,但是却只有少数连接是活跃的这种情况非常适用。
epoll有三个系统调用:
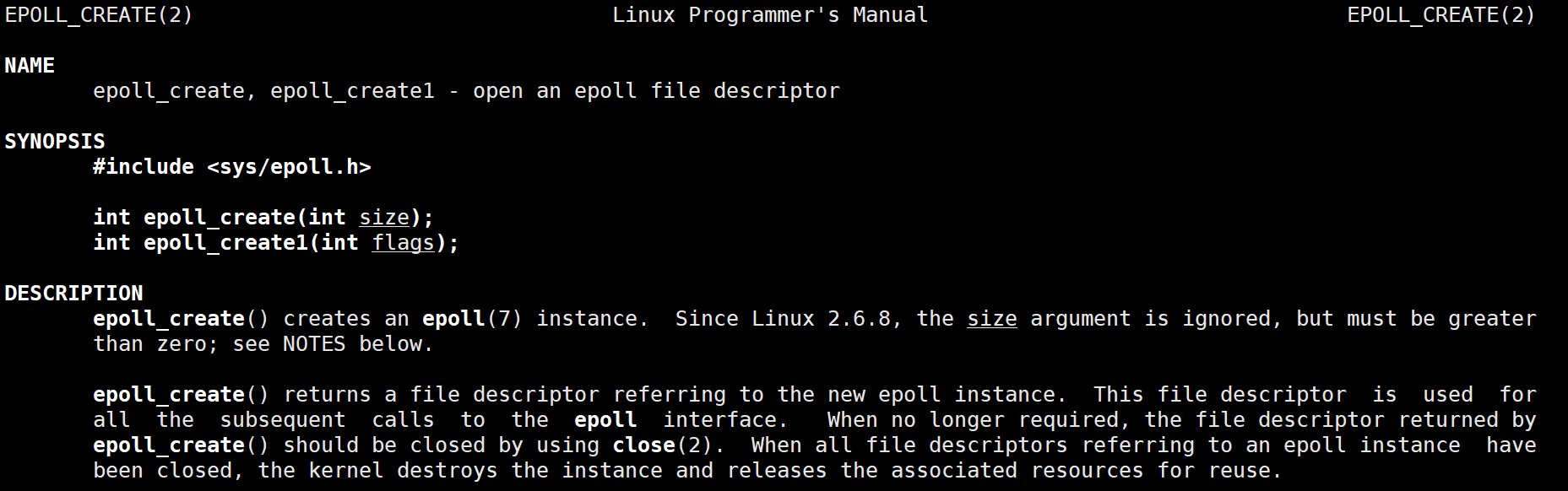
epoll_create
创建一个epoll的句柄,自从linux2.6.8之后,size参数是被忽略的。用完之后,必须调用close()关闭。
epoll_ctl
epoll_ctl是epoll的事件注册函数
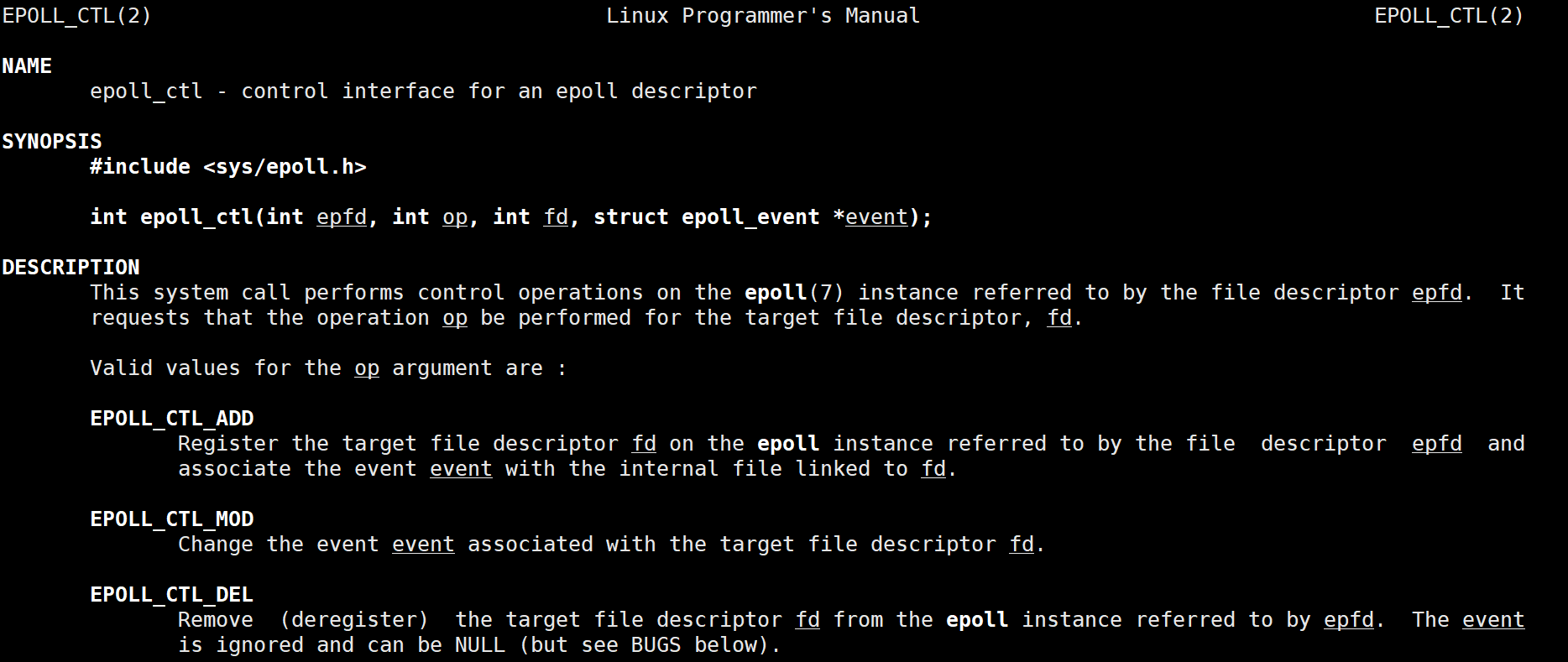
它不同于select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。
- 第一个参数是epoll_create()的返回值(epoll的句柄)
- 第二个参数表示动作,用三个宏来表示
- 第三个参数是需要监听的fd
- 第四个参数是告诉内核需要监听什么事
第二个参数的取值也如上图,分别是注册新的fd到epfd中;修改已经注册的fd的监听事件;从epfd中删除一个fd;第三个参数的取值如下图:
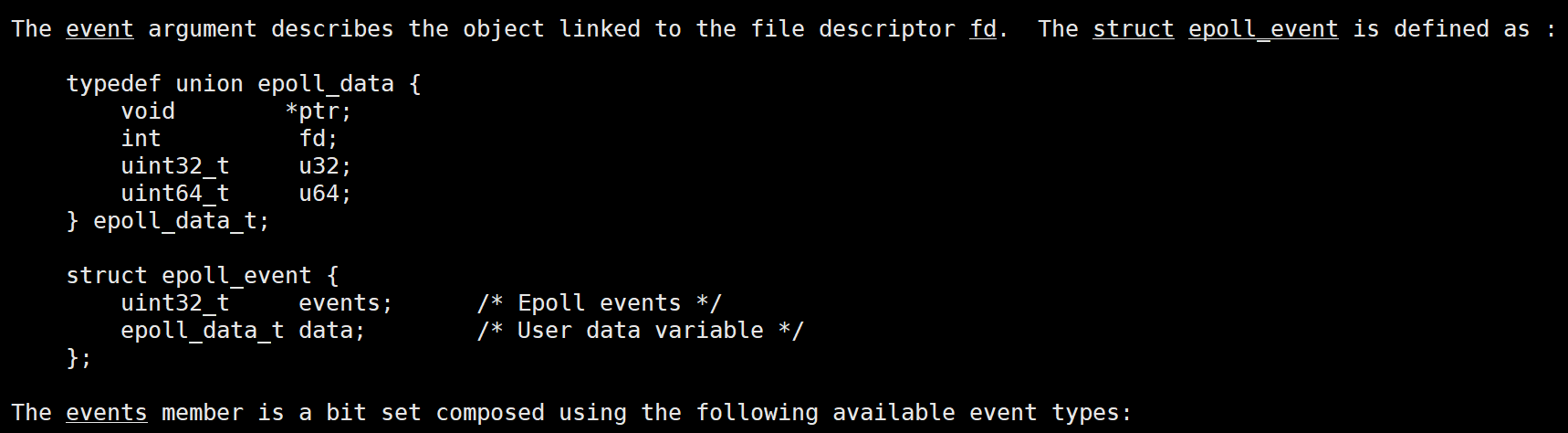
events可以是以下几个宏的集合
- EPOLLIN : 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭)
- EPOLLOUT : 表示对应的文件描述符可以写
- EPOLLPRI : 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来)
- EPOLLERR : 表示对应的文件描述符发生错误
- EPOLLHUP : 表示对应的文件描述符被挂断
- EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式, 这是相对于水平触发(Level Triggered)来说的
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
epoll_wait
收集在epoll监控的事件中已经发送的事件。
- 参数events是分配好的epoll_event结构体数组
- epoll将会把发生的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)
- maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size
- 参数timeout是超时时间 (毫秒,0会立即返回,-1是永久阻塞)
如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时, 返回小于0表示函数失败。
epoll工作原理
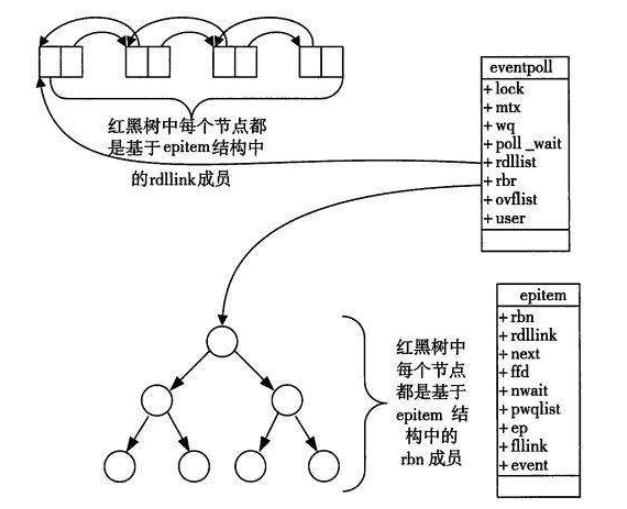
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。
struct eventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct list_head rdlist;
....
};
- 每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。
- 这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgN,其中n为树的高度)。
- 而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当响应的事件发生时会调用这个回调方法。
- 这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
- 在epoll中,对于每一个事件,都会建立一个epitem结构体。
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。 如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。这个操作的时间复杂度是O(1)。
总结一下, epoll的使用过程就是三部曲: 1、调用epoll_create创建一个epoll句柄; 2、调用epoll_ctl,将要监控的文件描述符进行注册; 3、调用epoll_wait,等待文件描述符就绪;
epoll的优点
1、接口使用方便:虽然拆分成了三个函数,但是反而使用起来更方便高效,不需要每次循环都设置关注的文件描述符,也做到了输入输出参数分离开;
2、数据拷贝轻量:只在合适的时候调用 EPOLL_CTL_ADD 将文件描述符结构拷贝到内核中,这个操作并不频繁,而select/poll都是每次循环都要进行拷贝;
3、事件回调机制:避免使用遍历,而是使用回调函数的方式,将就绪的文件描述符结构加入到就绪队列中,epoll_wait 返回直接访问就绪队列就知道哪些文件描述符就绪。这个操作时间复杂度O(1),即使文件描述符数目很多,效率也不会受到影响;
4、没有数量限制:文件描述符数目无上限;