RISC汇编与中断向量表
摩尔定律让算力放缓,以前学习的都是32位的x86汇编,不得不说x86架构的指令集真的是历史包袱太重了,x86架构的不足在当代急需超强的算力的背景下越发明显,功耗大、通用寄存器数量少、计算机硬件利用率低、寻址范围小等问题凸显,难以跟上算力发展的速度。与此同时,ARM架构在移动互联网盛行的当下却开始焕发出别样的生命力。于是最近看了看ARM架构下的衍生RISC-V架构,顺便回顾一下计算机组成原理的相关内容。
汇编环境搭建
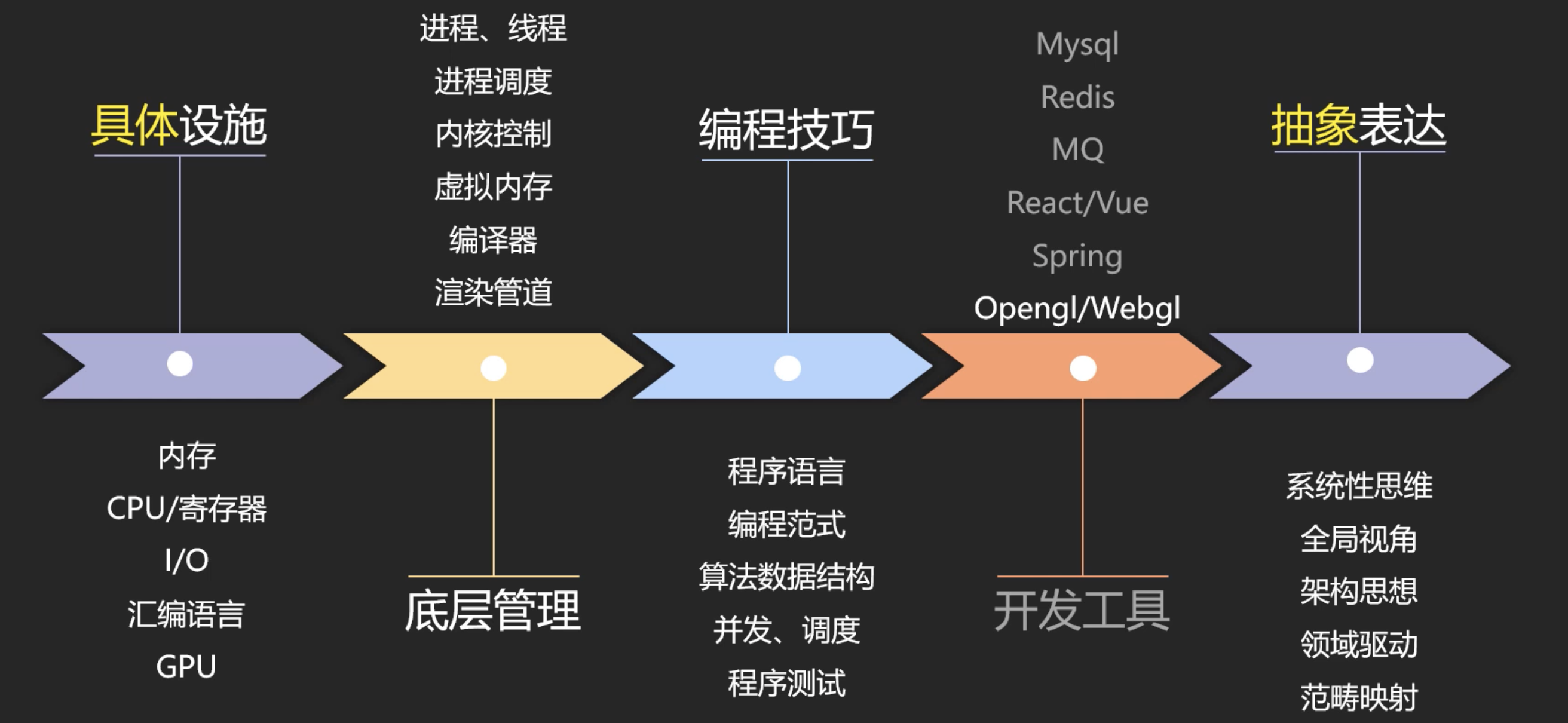
最近的内容其实也主要就是包含了上图中具体设施、底层管理和编程技巧的一些内容。上面也说道了由于X86的特性,还是开源的RISC-V指令集更加有利于学习。其实本质都是一样的,在学习RISC-V指令集的时候我使用了MARS,MARS是一个轻量级的交互式开发环境(包含MIPS汇编程序和运行时模拟器的IDE),用于使用MIPS汇编语言进行编程,旨在与Patterson和Hennessy的计算机组织和设计一起用于教育使用。这里是它的官网: http://courses.missouristate.edu/kenvollmar/mars/

下载完成后是一个4MB左右的Jar可执行文件,需要使用Java环境,如果有Java运行环境(JRE)可直接使用,否则应先下载JRE或者JDK才可以,打开后是这样的:
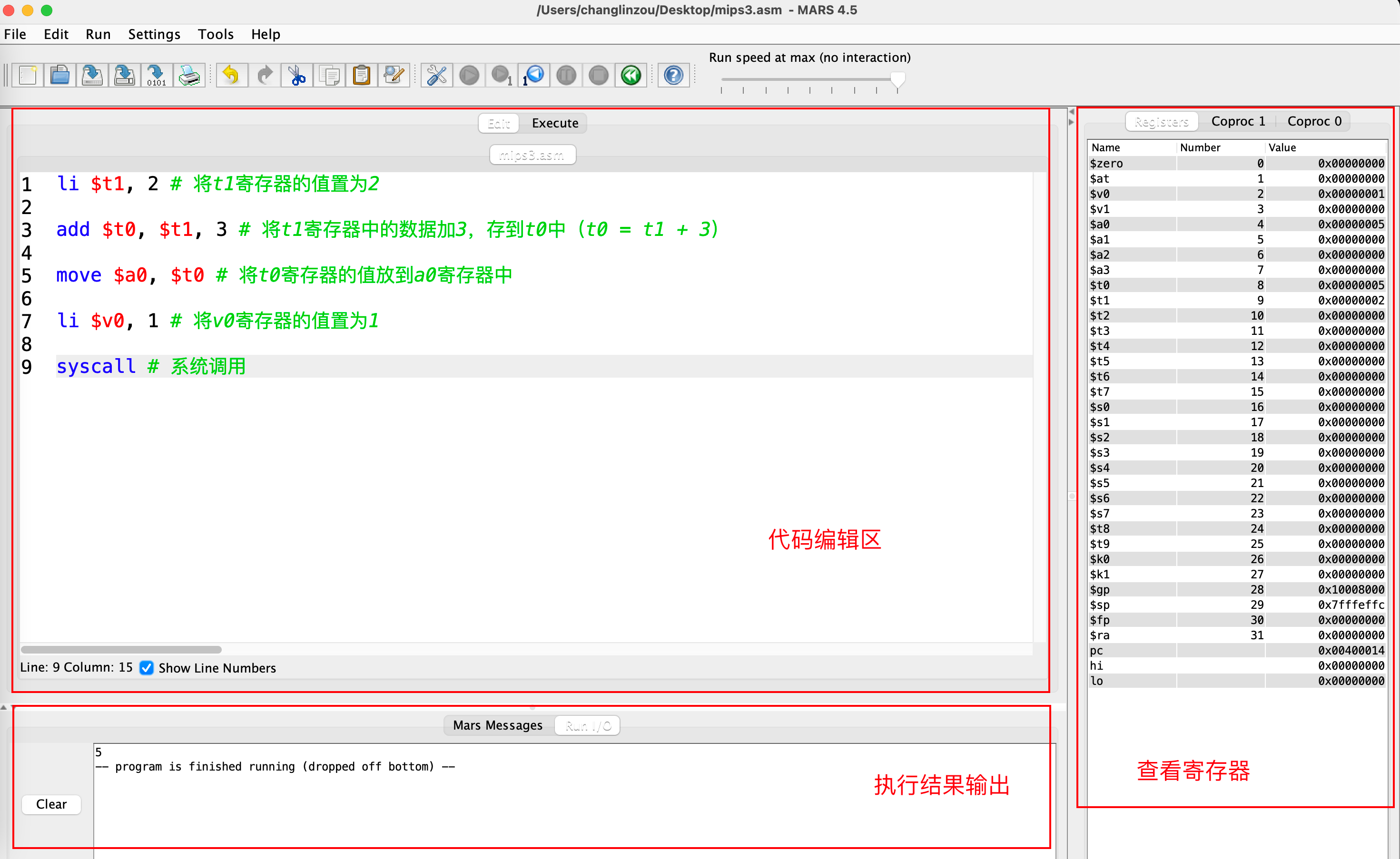
上图中的汇编代码对应的C代码是:
#include <stdio.h>
int main(){
int r, x;
x = 2;
r = x + 3;
printf("%d", r);
return 0;
}
汇编相关概念
汇编语言特点
ASM也是汇编语言源程序的扩展名,汇编程序员也称汇编为ASM,汇编语言(Assembly Language)是面向机器的程序设计语言,汇编语言是一种功能很强的程序设计语言,也是利用计算机所有硬件特性并能直接控制硬件的语言。
在汇编语言中,用助记符( Mnemonic)代替操作码,用地址符号(Symbol)或标号(Label)代替地址码。这样用符号代替机器语言的二进制码,就把机器语言变成了汇编语言,因此汇编语言亦称为符号语言。使用汇编语言编写的程序,机器不能直接识别,要由一种程序将汇编语言翻译成机器语言,这种起翻译作用的程序叫汇编程序,汇编程序是系统软件中语言处理系统软件。汇编程序把汇编语言翻译成机器语言的过程称为汇编。汇编语言比机器语言易于读写、调试和修改,同时具有机器语言全部优点。但在编写复杂程序时,相对高级语言代码较大,而且汇编语言依赖于具体的处理器体系结构,不能通用,因此不能直接在不同处理器体系结构之间移植。
综上汇编语言的特点如下:
1、面向机器的低级语言,通常是为特定计算机或系列计算机专门设计的。
2、保持了机器语言的优点,具有直接和简捷的特点。
3、可有效地访问、控制计算机的各种硬件设备,如磁盘、存储器、CPU、I/O
反汇编与伪指令
反汇编:将可执行的文件中的二进制经过分析转变为汇编程序。
反编译:将可执行的程序经过分析转变为高级语言的源代码格式,一般完全的转换不太可能,编译器的优化等因素在里面
伪指令(伪汇编指令):用于告诉汇编程序如何进行汇编的指令,它既不控制机器的操作也不被汇编成机器代码,只能为汇编程序所识别并指导汇编如何进行。将相对于程序或相对于寄存器的地址载入寄存器中。
预处理指令(伪编译指令):比如#define和#ifdef,一般被用来使源代码在不同的执行环境中被方便的修改或者编译。源代码中这些指令会告诉预处理器执行特定的操作。比如告诉预处理器在源代码中替换特定字符等操作。
通过这样的对比其实可以非常深刻的理解反汇编与伪指令的含义,这与反编译与预处理指令如出一辙。
指令解码与助记符
以CPU计算5000×0.2的例子来看看数据空间地址与指令空间地址:

其中这些指令其实本质就是一个二进制串:
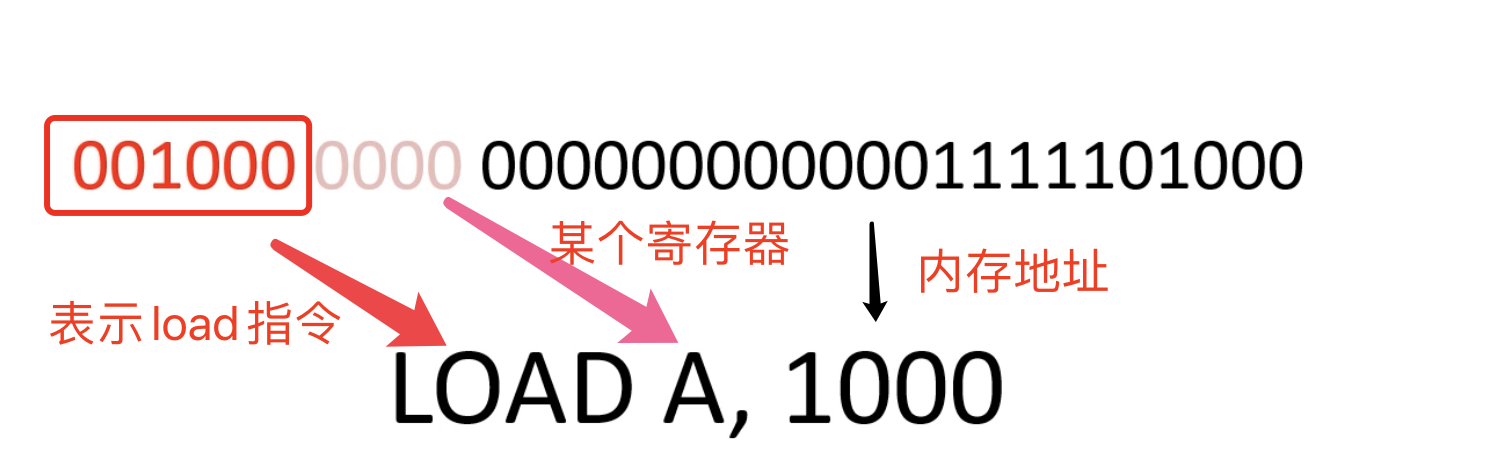
下面对指令集做一个大致预览,其中ADD、SUB、MUL、AND、OR等都是基本的数学运算或者逻辑运算,LOAD、STORE、MOV等都是对寄存器加载数据控制相关的指令,最后还有流程控制相关的BRANCH、BREQ、BRNE、BRIO等指令。
程序指针也叫作PC指针,是一个特殊的寄存器,存储下一条要的程序所在的内存地址:
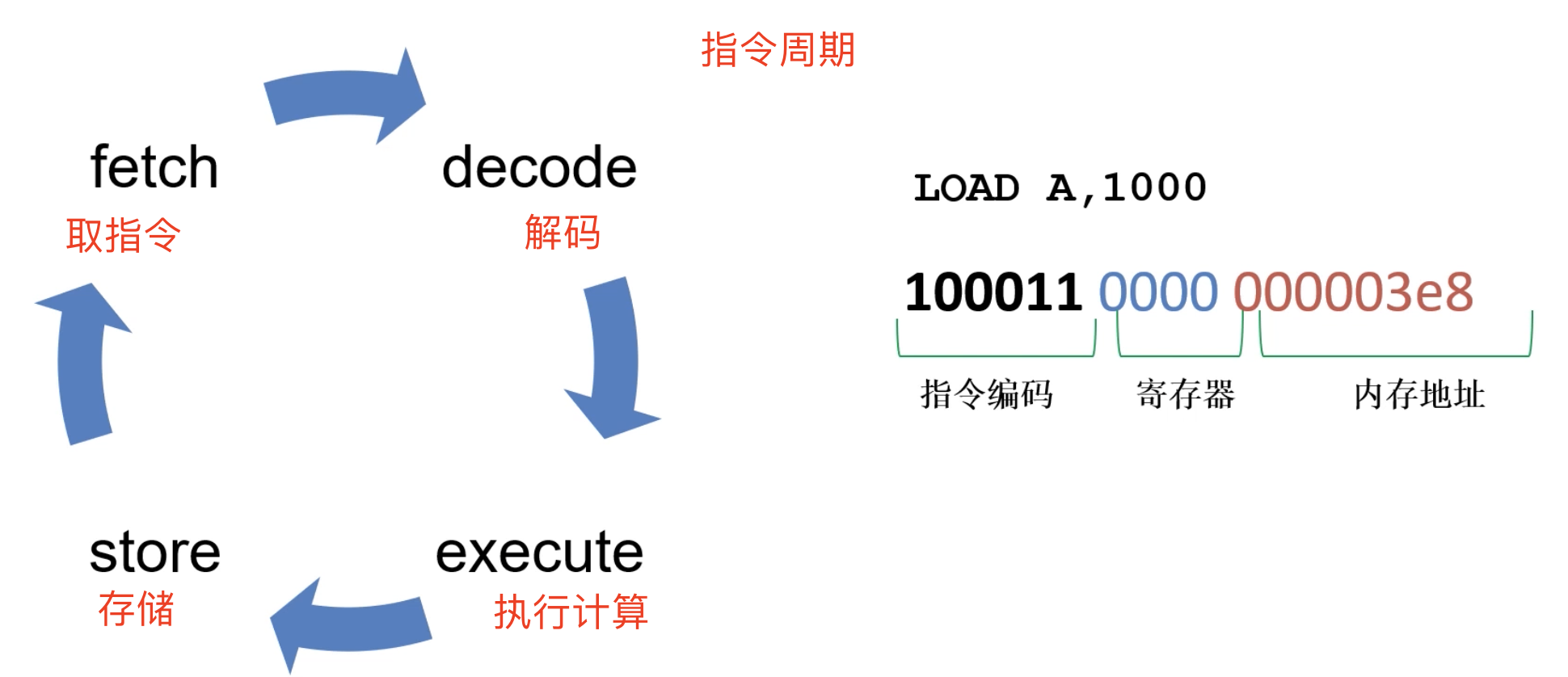
所以整个计算过程如下图所示:
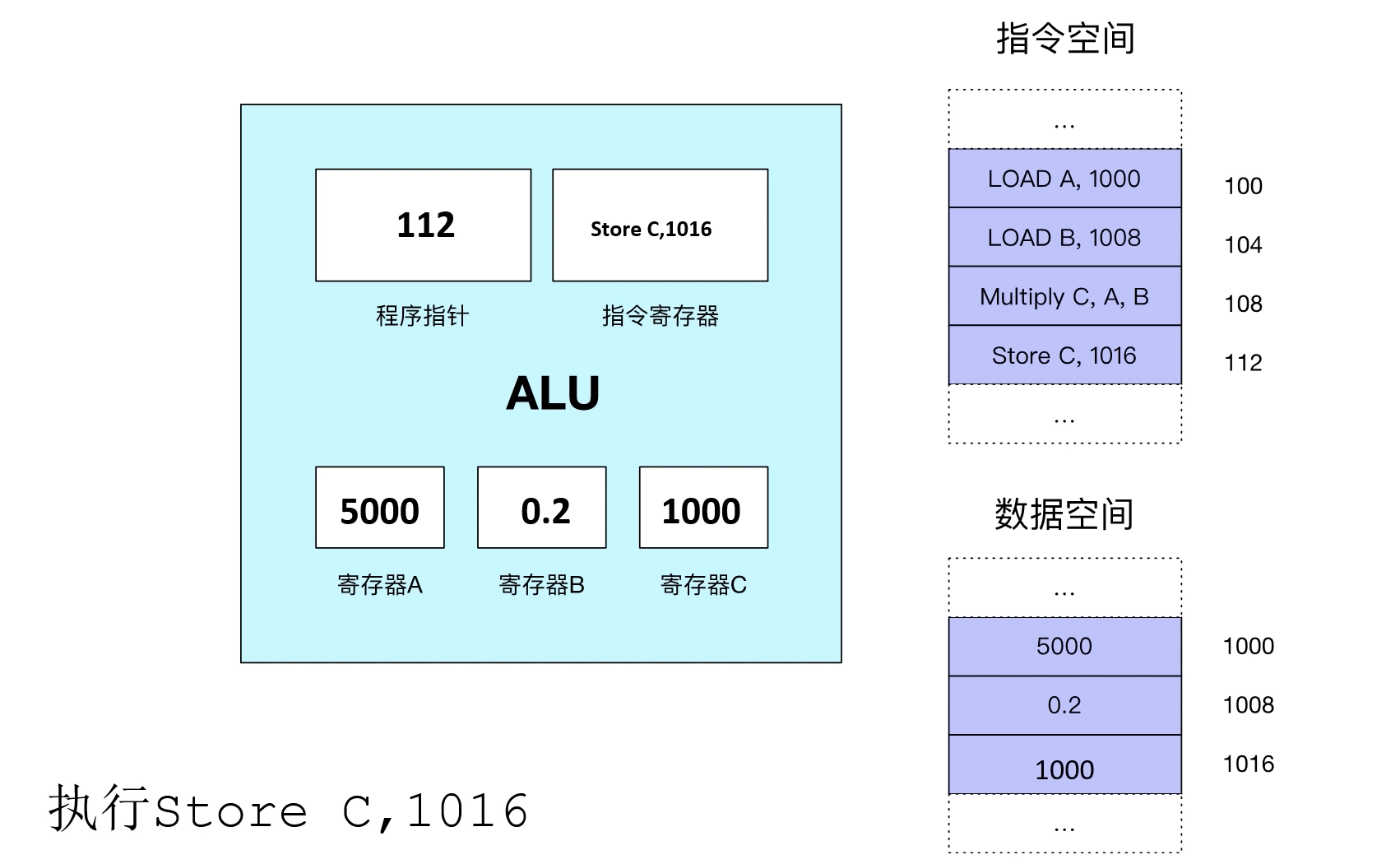
所以需要知道的重点就是:
1、计算机通过指令指挥计算机工作
2、CPU被时钟驱动,不断的读取PC指针指向的指令,并增加PC指针从内存中读取指令并执行,如此周而复始。
3、不同的CPU架构使用不同指令,目前使用最广泛的是RISC (精简指令集)
指令解码的过程:对于这个RISC来说所有指令的长度都是一样的。对于MIPS-32架构【一种采取精简指令集(RISC)的处理器架构】的指令示例:

不同的opcode对应着不同的拆分方式:
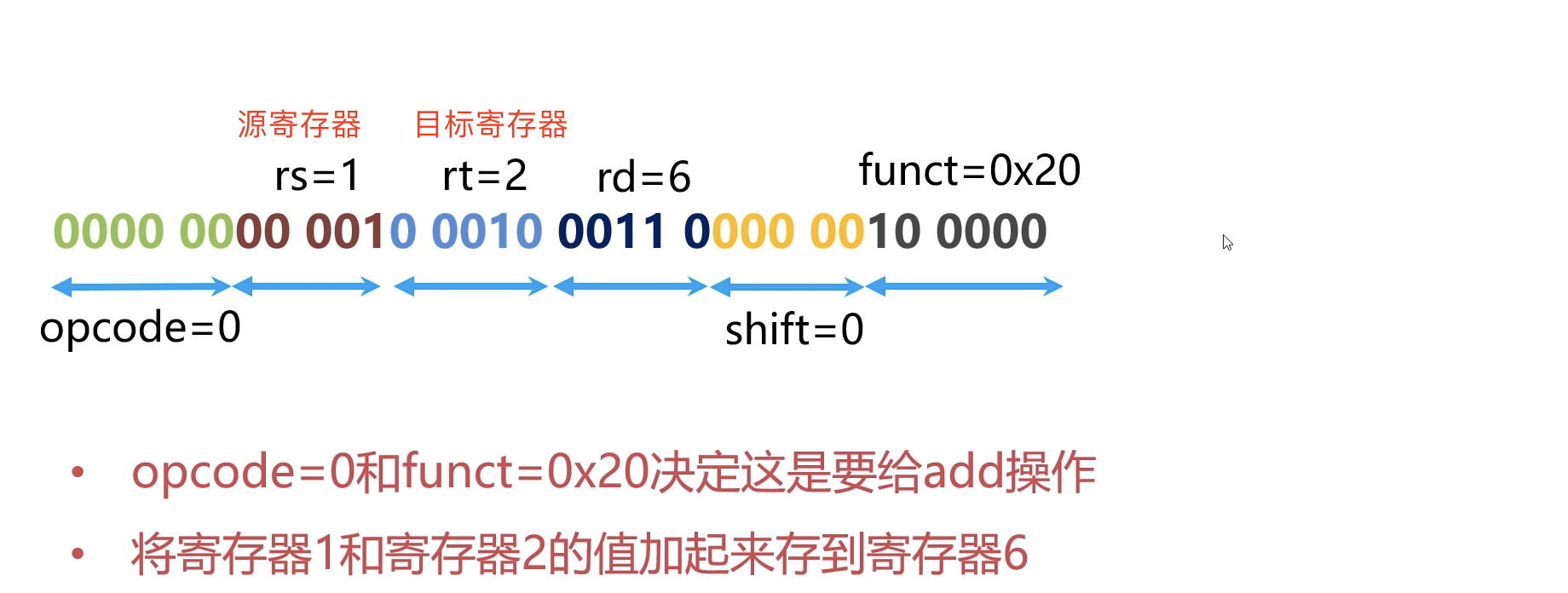 还比如下面这条opcode=25的时候:
还比如下面这条opcode=25的时候:

所以需要知道的是CPU根据opcode的不同来识别这条指令应该如何去解码和执行的。
助记符:32位RISC指令集中,opcode是6位数字,这太过于抽象,不好记忆,因此我们通常采用助记符来记忆他们,所以就形成了上面的各种汇编指令。
四种寻址模式
寻址模式是指令集的一部分,决定指令有几个操作符,地址如何计算。不需要记有哪些寻址模式,这个不重要,不同指令集寻址模式也不同;通过学习寻址模式看到的其实是如何利用好二进制指令。
1、寄存器寻址
操作符是寄存器,利用n位寻址2n次方个寄存器,比如add $r10, $r1, $r2,把1号寄存器和2号寄存器的内容相加后存储到10号寄存器。

2、立即寻址
操作符中有值,例如addi $r1, $zero, 1000 数字大小有限制,如32位机器就是[-2^15-1 ~ 2^15]

3、偏移量寻址
根据基地址和偏移量进行寻址,最终的地址是在基地址和偏移量上计算,例如:lw $r0, 8($sp)
 sp作为基寄存器,偏移量是8,通过这样的偏移量计算得到的内存地址,把改地址的值放到目标寄存器中
sp作为基寄存器,偏移量是8,通过这样的偏移量计算得到的内存地址,把改地址的值放到目标寄存器中
4、PC相对寻址
下一个PC指针的位置依赖当前位置到Label的距离(当前代码行和Label所在的代码行之差),比如 beq $r3, $r9, LABAL
 r3寄存器与r9寄存器中的值相同的时候就跳转到Label,相当于goto语句的作用
r3寄存器与r9寄存器中的值相同的时候就跳转到Label,相当于goto语句的作用
内存读写指令
load/store指令用来从内存中读写入内。通常会有多个版本的实现,助记符是:
load类:lw,lb,lh、store类:sw、sb、sh
数学运算指令
立即寻址 addi、subi、divi、multi 如:addi $sp, $sp, 4
寄存器寻址 add、sub、div、mult 如:add $d, $rs, $rt
位运算指令
and、or、xor等
条件跳转
相对寻址j LABLE
寄存器间接寻址 jr $a0
多合一 jal LABLE ,将当前PC指针 + 4(对于32位机器来说)存入$ra寄存器,再执行j LABLE,函数调用就是这样实现的
opcode代表指令的类型; opcode也决定寻址模式
直接寻址、间接寻址、偏移量寻址不要死记硬背,要理解。
MIPS的32个寄存器
MIPS有32个通用寄存器($0-$31),各寄存器的功能及汇编程序中使用约定如下,下表描述32个通用寄存器的别名和用途:
| REGISTER | NAME | USAGE |
|---|---|---|
$0 | $zero | 常量0 (constant value 0) |
$1 | $at | 保留给汇编器(Reserved for assembler) |
$2-$3 | $v0-$v1 | 函数调用返回值(values for results and expression evaluation) |
$4-$7 | $a0-$a3 | 函数调用参数(arguments) |
$8-$15 | $t0-$t7 | 暂时的(或随便用的) |
$16-$23 | $s0-$s7 | 保存的(或如果用,需要SAVE/RESTORE的)(saved) |
$24-$25 | $t8-$t9 | 暂时的(或随便用的) |
$28 | $gp | 全局指针(Global Pointer) |
$29 | $sp | 堆栈指针(Stack Pointer) |
$30 | $fp | 帧指针(Frame Pointer) |
$31 | $ra | 返回地址(return address) |
$0:即$zero,该寄存器总是返回零,为0这个有用常数提供了一个简洁的编码形式。move $t0,$t1实际为add $t0,$0,$t1,使用伪指令可以简化任务,汇编程序提供了比硬件更丰富的指令集。
$1:即$at,该寄存器为汇编保留 ,由于I型指令的立即数字段只有16位,在加载大常数时,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。比如加载一个32位立即数需要 lui(装入高位立即数)和addi两条指令。像MIPS程序拆散和重装大常数由汇编程序来完成,汇编程序必需一个临时寄存器来重组大常数,这也是为汇编 保留$at的原因之一。
$2..$3:($v0-$v1)用于子程序的非浮点结果或返回值, 对于子程序如何传递参数及如何返回,MIPS范围有一套约定,堆栈中少数几个位置处的内容装入CPU寄存器,其相应内存位置保留未做定义,当这两个寄存器不够存放返回值时,编译器通过内存来完成。
$4..$7:($a0-$a3)用来传递前四个参数给子程序,不够的用堆栈。a0-a3和v0-v1以及ra一起来支持子程序/过程调用,分别用以传递参数,返回结果和存放返回地址。当需要使用更多的寄存器时,就需要堆栈(stack)了,MIPS编译器总是为参数在堆栈中留有空间以防有参数需要存储。
$8..$15:($t0-$t7)临时寄存器,子程序可以使用它们而不用保留。
$16..$23:($s0-$s7)保存寄存器,在过程调用过程中需要保留(被调用者保存和恢复,还包括$fp和$ra),MIPS提供了临时寄存器和保存寄存器,这样就减少了寄存器溢出(spilling,即将不常用的变量放到存储器的过程),编译器在编译一个叶(leaf)过程(不调用其它过程的过程)的时候,总是在临时寄存器分配完了才使用需要保存的寄存器。
$24..$25:($t8-$t9)同($t0-$t7)
$26..$27:($k0,$k1)为操作系统/异常处理保留,至少要预留一个。异常(或中断)是一种不需要在程序中显示调用的过程。MIPS有个叫异常程序计数器(exception program counter,EPC)的寄存器,属于CP0寄存器,用于保存造成异常的那条指令的地址。查看控制寄存器的唯一方法是把它复制到通用寄存器里,指令mfc0(move from system control)可以将EPC中的地址复制到某个通用寄存器中,通过跳转语句(jr),程序可以返回到造成异常的那条指令处继续执行。MIPS程序员都必须保留两个寄存器$k0和$k1,供操作系统使用。发生异常时,这两个寄存器的值不会被恢复,编译器也不使用k0和k1, 异常处理函数可以将返回地址放到这两个中的任何一个,然后使用jr跳转到造成异常的指令处继续执行。
$28:($gp) 为了简化静态数据的访问,MIPS软件保留了一个寄存器:全局指针gp(global pointer, $gp),全局指针只想静态数据区中的运行时决定的地址,在存取位于gp值上下32KB范围内的数据时,只需要一条以gp为基指针的指令即可。在编译时,数据须在以gp为基指针的64KB范围内。
$29:($sp)MIPS硬件并不直接支持堆栈 ,你可以把它用于别的目的,但为了使用别人的程序或让别人使用你的程序,还是要遵守这个约定的,但这和硬件没有关系。
$30:($fp) GNU MIPS C编译器使用了帧指针(frame pointer), 而SGI的C编译器没有使用, 而把这个寄存器当作保存寄存器使用($s8), 这节省了调用和返回开销,但增加了代码生成的复杂性。
$31:($ra)存放返回地址, MIPS有个jal (jump-and-link,跳转并链接)指令,在跳转到某个地址时,把下一条指令的地址放到$ra中。用于支持子程序,例如调用程序把参数放到$a0~$a3,然后jal X跳到X过程,被调过程完成后把结果放到$v0,$v1,然后使用jr $ra返回。
MIPS体系结构中寄存器大小为32位,32位一组称为字(word),MIPS以#作为注释开头:
| 名字 | 示例 | 备注 |
|---|---|---|
| 32个寄存器 | 以$开头, s0 - s7, t0 - t9, zero, a0 -a3, v0, v1, k0, k1, gp, fp, sp, ra, at | 寄存器用于数据的快速存取。$zero的值恒为0,$at被汇编器保留用于处理大的常数 |
| $2^{30}个存储器字$ | Memory[0], Memory[4], …, Memory[4294967292] | 存储器只能通过数据传输指令访问。字地址相差4,储存器用于保存数据结构、数组、溢出的寄存器。 |
算术指令:
| 指令 | 备注 |
|---|---|
add $s1, $s2, $s3 | 加法,$s1 = $s2 + $s3 |
sub $s1, $s2, $s3 | 减法,$s1 = $s2 - $s3 |
addi $s1, $s2, 20 | 立即数加法,用于加常数数据,$s1 = $s2 + 20 |
数据传输:
| 指令 | 备注 |
|---|---|
lw $s1, 20($s2) | 取字,$s1 = Memory[$s2 + 20] |
sw $s1, 20($s2) | 存字,Memory[$s2 + 20] = $s1 |
lh $s1, 20($s2) | 取半字 |
lhu $s1, 20($s2) | 取无符号半字 |
sh $s1, 20($s2) | 存半字 |
lb $s1, 20($s2) | 取字节 |
lbu $s1, 20($s2) | 取无符号字节 |
sb $s1, 20($s2) | 存字节 |
ll $s1, 20($s2) | 取链接字(链接加载),取字作为原子交换(atomic swap)的前半部(1st half) |
sc $s1, 20($s2) | 存条件字(条件存储),存字作为原子交换的后半部,Memory[$s2 + 20] = $s1; $s1 = 0 or 1 |
lui $s1, 20 | 取立即数的高位(load upper immediate),$s1 = 20 * 2 ^ 16,取立即数并放到高16位 |
MIPS的字是4个字节,并不是x86里面的word才2个字节。
逻辑:
| 指令 | 备注 |
|---|---|
and $s1, $s2, $s3 | 与,$s1 = $s2 & $s3 |
or $s1, $s2, $s3 | 或,`$s1 = $s2 |
nor $s1, $s2, $s3 | 或非,`$s1 = ~($s2 |
andi $s1, $s2, 20 | 立即数与 |
ori $s1, $s2, 20 | 立即数或 |
sll $s1, $s2, 10 | 逻辑左移(shift left logical),$s1 = $s2 << 10 |
srl $s1, $s2, 10 | 逻辑右移(shift right logical),$s1 = $s2 >> 10 |
条件分支:
| 指令 | 备注 |
|---|---|
beq $s1, $s2, 25 | 相等时跳转(branch on equal),goto PC + 4 + 100 |
bne $s1, $s2, 25 | 不相等时跳转(branch on not equal),goto PC + 4 + 100 |
slt $s1, $s2, $s3 | 小于时置位(set on less than),$s1 = ($s2 < $s3 ? 1 : 0) |
sltu $s1, $s2, $s3 | 无符号数比较小于时置位(set on less than unsigned) |
slti $s1, $s2, 20 | 小于立即数时置位 |
sltiu $s1, $s2, 20 | 无符号数比较小于立即数时置位 |
无条件跳转:
| 指令 | 备注 |
|---|---|
j 2500 | 跳转(jump),goto 10000 |
jr $ra | 跳转至寄存器所指位置(jump register),goto $ra,用于switch和过程调用 |
jal 2500 | 跳转并链接(jump and link),$ra = PC + 4; goto 10000,用于过程调用 |
函数递归求阶乘
func fact(int i){
if(i == 0){
return 1;
}
return fact(i - 1);
}
下面会把这个递归函数使用MIPS汇编来实现:
对于if-else结构:

bne指令会比较r3寄存器和r4寄存器中的内容,如果相等则继续执行,不相等会跳转到ELSE标识处
对于for-loop结构:
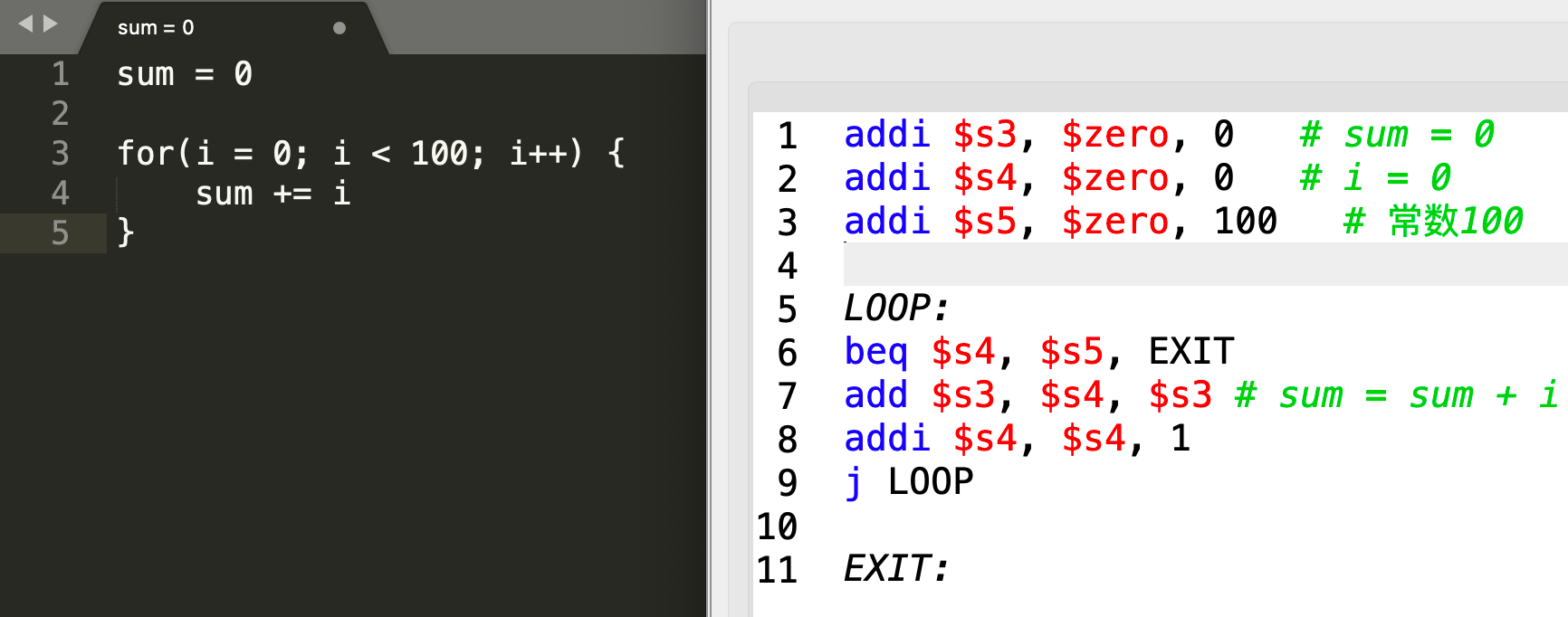
我们主要比较关心的就是参数传递、返回值的获取:

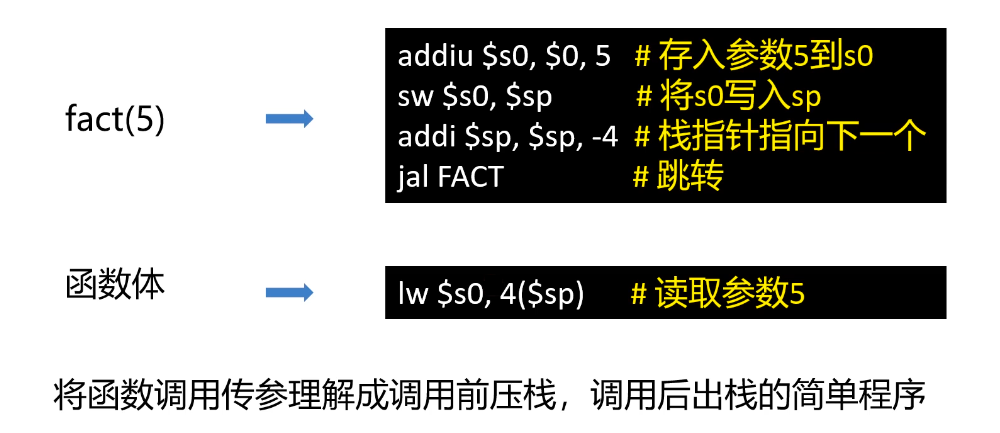
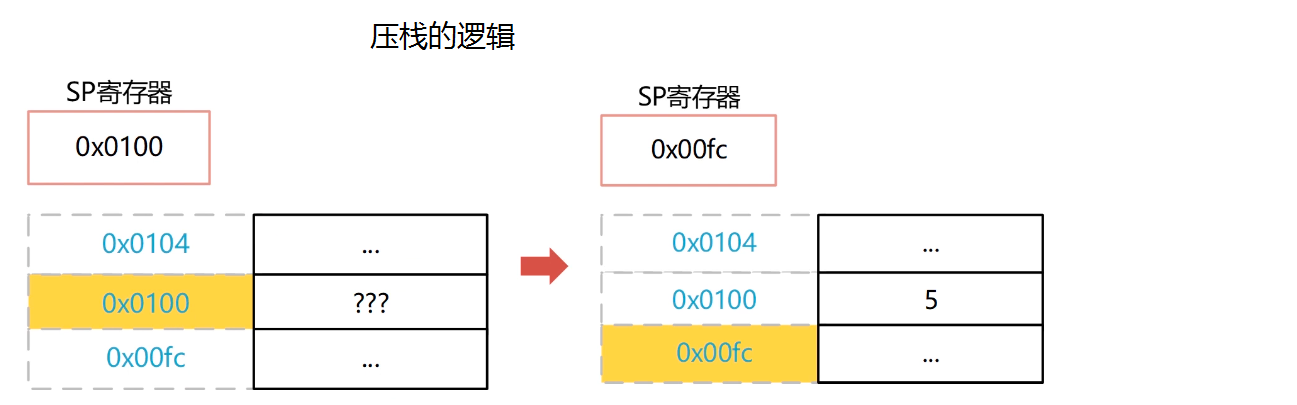


注意我们理解的递归调用与真正的控制过程的关系:
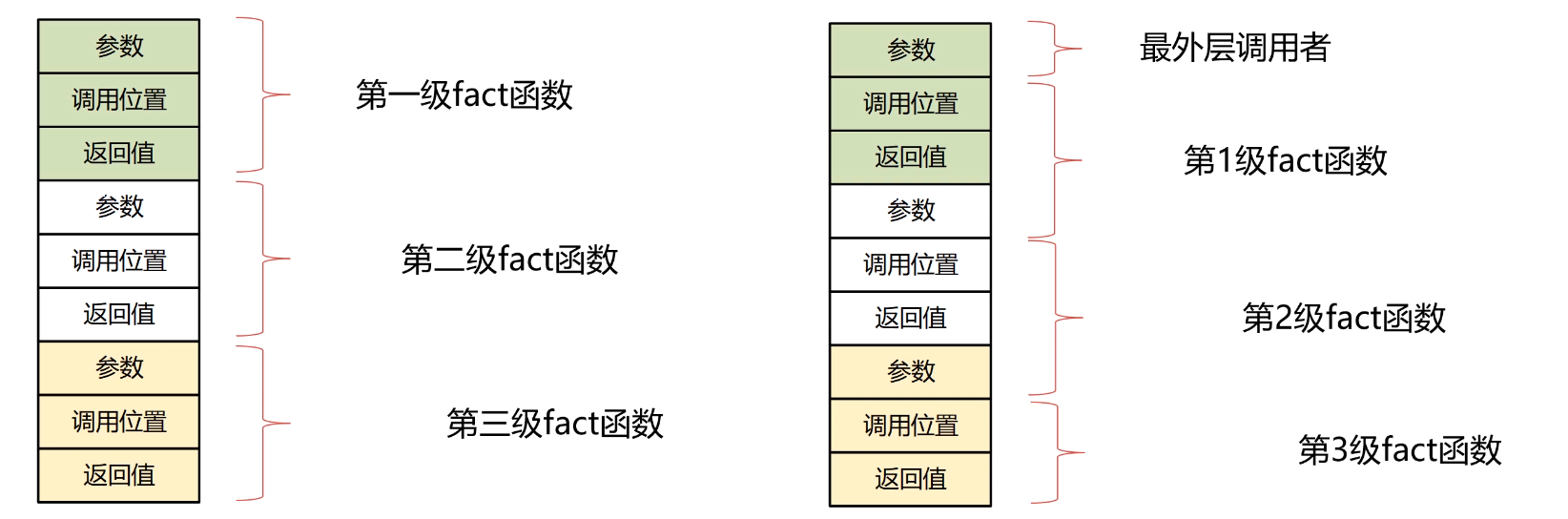
下面是完整的汇编代码:
# 开始递归函数调用
addiu $sp, $0, 0x10010080
# 压栈入参
addiu $s0, $0, 5 # n=5
sw $s0, 0($sp)
addiu $sp, $sp, -4
jal FACT
nop
j END
nop
FACT:
# 压栈返回地址
sw $ra, 0($sp)
addiu $sp, $sp, -4
# 读取入参
lw $s0, 8($sp)
# 压栈返回值
sw $0, 0($sp)
addiu $sp, $sp, -4
# 递归base条件
# if (n == 0) { return 1}
bne $s0, $0, RECURSION
nop
# 读取下返回地址
lw $t1, 8($sp)
# 出栈:返回值,返回地址
addiu $sp, $sp, 8
# 压栈返回值
addiu $s0, $zero, 1
sw $s0, 0($sp)
addiu $sp, $sp, -4
jr $t1
nop
RECURSION : # recursion
# return fact(n-1) * n
#压栈参数
addiu $s1, $s0, -1
sw $s1, 0($sp)
addiu $sp, $sp, -4
jal FACT
nop
# 现在的栈是什么样子的? 参数 | 返回地址 | 返回值 | 子函数的参数 | 子函数的返回值 | 当前SP
# 当前参数
lw $s0, 20($sp)
# 子函数返回值
lw $s1, 4($sp)
# 返回地址
lw $t1, 16($sp)
mult $s1, $s0
mflo $s2
# 出栈:
addiu $sp, $sp, 16
# 返回值压栈
sw $s2, 0($sp)
addiu $sp, $sp, -4
jr $t1
nop
END:
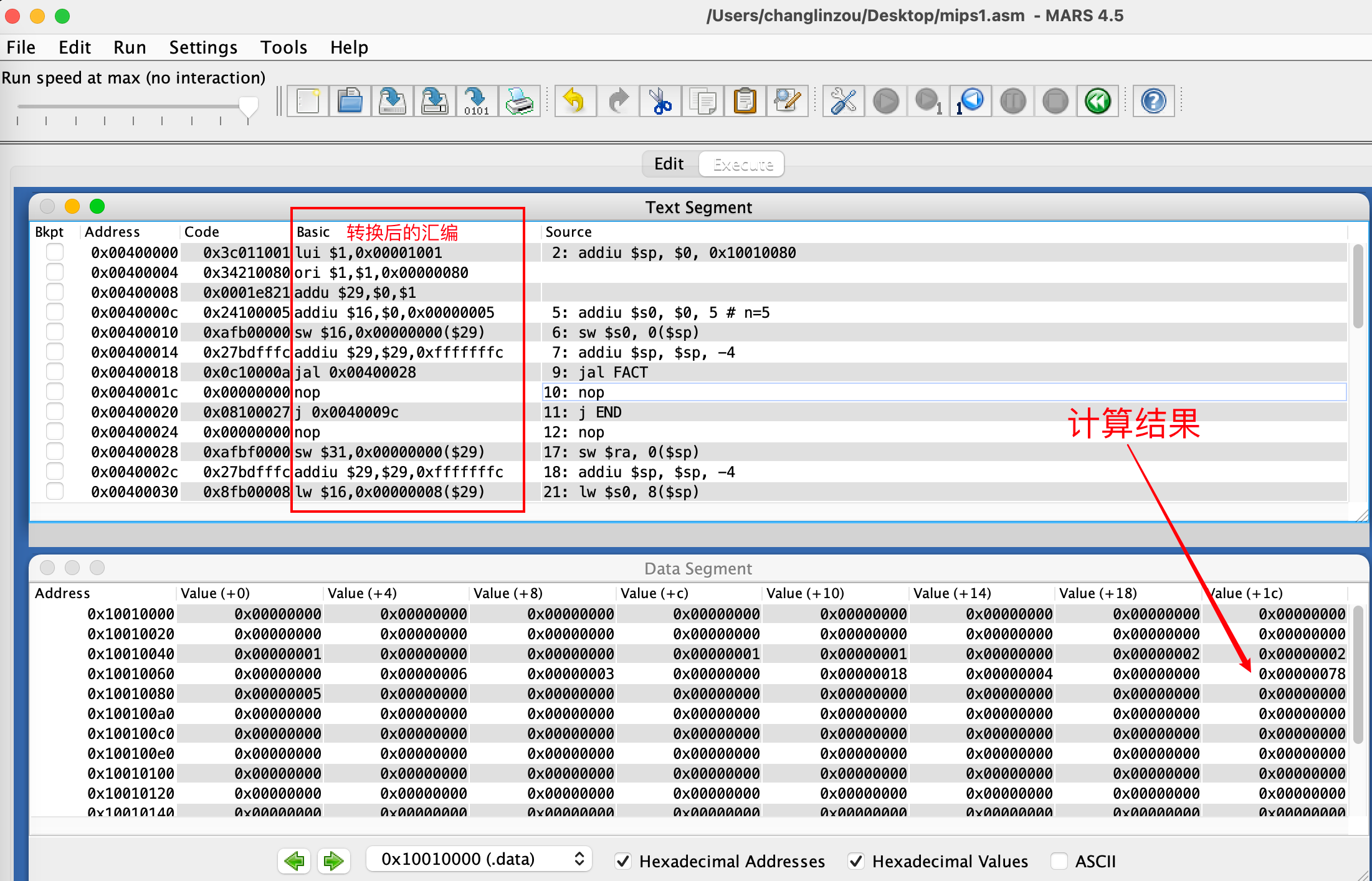
运行代码可以看到,计算结果已经在$sp寄存器中了:
MIPS的其它示例
如果上面的递归调用过程太复杂,也可以先看看这几个例子:
$sp:栈指针(stack pointer)寄存器,第29号寄存器,以字为单位进行调整。按照历史惯例,栈“增长”是按照地址从高到低的顺序进行。数据压栈时,栈指针值减小。
int leaf_example(int g, int h, int i, int j) {
return (g + h) - (i + j);
}
我们可以写出如下的代码:
leaf_example:
# 分配3个空间储存寄存器旧值
addi $sp, $sp, -12
sw $t1, 8($sp)
sw $t0, 4($sp)
sw $s0, 0($sp)
# 函数体
add $t0, $a0, $a1
add $t1, $a2, $a3
sub $s0, $t0, $t1
add $v0, $s0, $zero
# 恢复寄存器旧值
lw $s0, 0($sp)
lw $t0, 4($sp)
lw $t1, 8($sp)
addi $sp, $sp, 12
jr $ra
nop
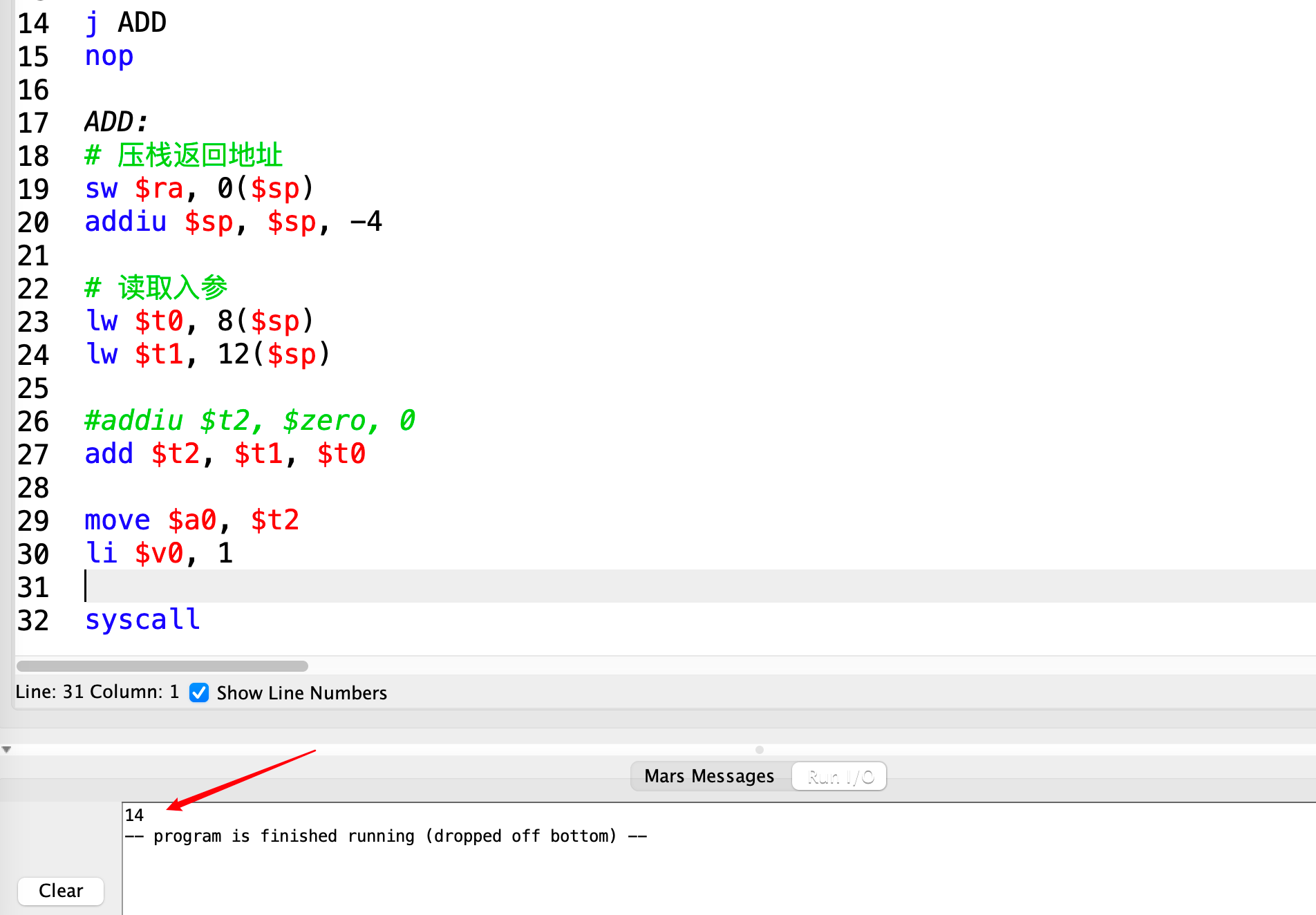
对于一个简单的求和函数
# add(5 + 9)
# 开始函数调用
addiu $sp, $0, 0x10010080
# 压栈入参
addiu $s0, $0, 5 # a = 5
sw $s0, 0($sp)
addiu $sp, $sp, -4
addiu $s1, $zero, 9 # b = 9
sw $s1, 0($sp)
addiu $sp, $sp, -4
j ADD
nop
ADD:
# 压栈返回地址
sw $ra, 0($sp)
addiu $sp, $sp, -4
# 读取入参
lw $t0, 8($sp)
lw $t1, 12($sp)
#addiu $t2, $zero, 0
add $t2, $t1, $t0
move $a0, $t2
li $v0, 1
syscall
中断与中断向量
当外界发生变化时,通过中断通知CPU应该去注意某个信号(事件)。这个时候,CPU当前执行的程序会被中断,当前的执行状态会被保存,中断响应程序会被执行。
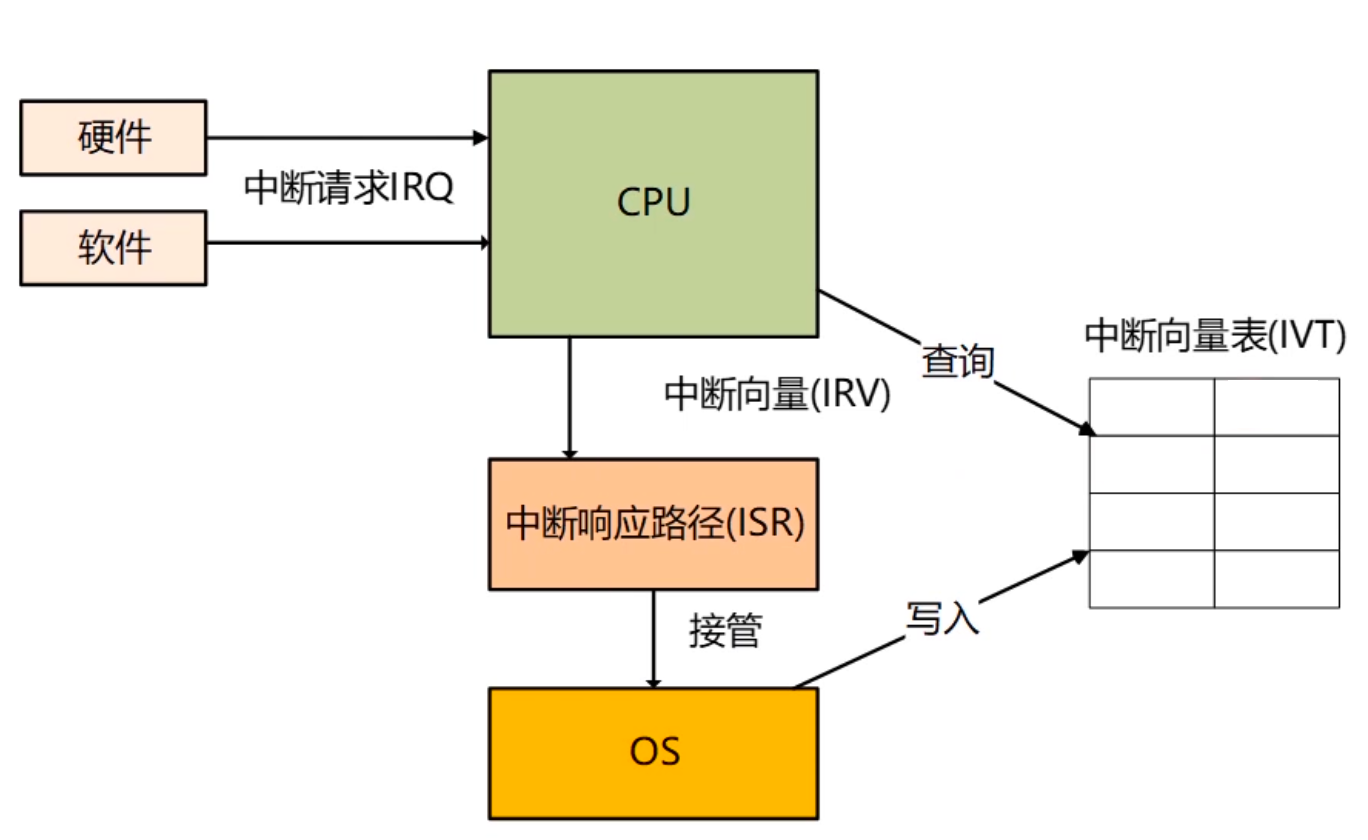
中断触发与处理的简要过程:
1、(OS加载时)写入中断向量表
2、产生中断请求,发送给CPU
3、查询中断向量表( Interrupt Vector Table)确定中断向量(Interrupt Vector)
4、根据中断向量定位中断响应程序
5、OS接管中断
中断请求( (Interrupt Request)
硬件设备发给主板(打印机、键盘、鼠标等)
硬件中断:CPU异常(除以0),时钟信号等
软件中断:发出(异常、切换到内核态等)
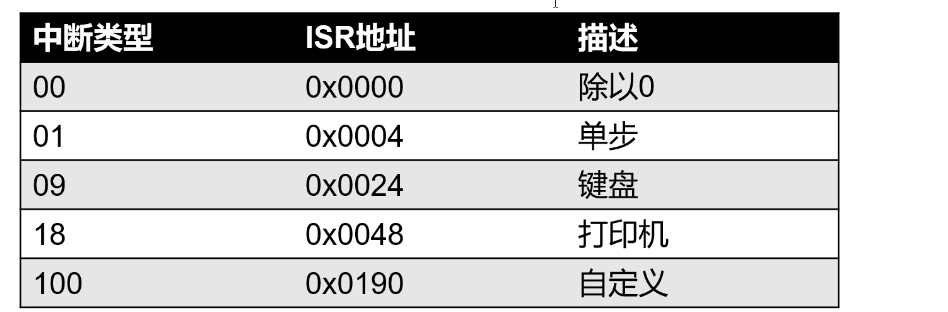
中断向量表(Interrupt Vector Table): (一般在内存中)一块区域,存储了中断类型和中断响应程序的对应
关系,每一行叫做一个中断向量。如下表中的01中断通常用于调试程序,逐步执行。
中断的意义:
1、提高工作效率(回忆 polling的问题)
2、故障恢复(异常处理、紧急事件等)
3、简化编程模型(try-cache,计时器等)