MyBatis(二)

作用域(Scope)和生命周期
SqlSessionFactoryBuilder这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但是最好还是不要让其一直存在以保证所有的 XML 解析资源开放给更重要的事情。
SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由对它进行清除或重建。使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,多次重建 SqlSessionFactory 被视为一种代码“坏味道(bad smell)”。因此 SqlSessionFactory 的最佳作用域是应用作用域。有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式。
每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行。也绝不能将 SqlSession 实例的引用放在任何类型的管理作用域中,比如 Servlet 架构中的 HttpSession。如果你现在正在使用一种 Web 框架,要考虑 SqlSession 放在一个和 HTTP 请求对象相似的作用域中。换句话说,每次收到的 HTTP 请求,就可以打开一个 SqlSession,返回一个响应,就关闭它。这个关闭操作是很重要的,你应该把这个关闭操作放到 finally 块中以确保每次都能执行关闭。下面的示例就是一个确保 SqlSession 关闭的标准模式:
SqlSession session = sqlSessionFactory.openSession();
try {
// do work
} finally {
session.close();
}
所以归纳一下:
| 类名称 | SCOPE |
|---|---|
| SqlSessionFactoryBuilder | method |
| SqlSessionFactory | application |
| SqlSession | request/method (可以认为是线程级) |
Result Maps
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来, 并在一些情形下允许你做一些 JDBC 不支持的事情。 实际上,在对复杂语句进行联合映射的时候,它很可能可以代替数千行的同等功能的代码。 ResultMap 的设计思想是,简单的语句不需要明确的结果映射,而复杂一点的语句只需要描述它们的关系就行了。
下面的示例基于
《MyBatis(一)》
,但是在数据库层面稍有修改,新增department表代表部门和部门id,employee表新增d_id,意思是员工的部门编号:
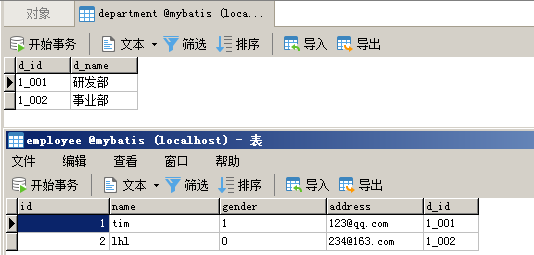 现在假设我们根据employee表设计出来的JavaBean是这样的:
现在假设我们根据employee表设计出来的JavaBean是这样的:
package com.xpu.bean;
import java.io.Serializable;
public class Employee{
private Integer e_id;
private String e_name;
private char e_gender;
private String e_address;
private Department dept;
public Department getDept() {.}
public void setDept(Department dept) {.}
public Employee() {
super();
}
public Employee(Integer e_id, String e_name, char e_gender, String e_address) {
super();
this.e_id = e_id;
this.e_name = e_name;
this.e_gender = e_gender;
this.e_address = e_address;
}
public Integer getE_id() {...}
public void setE_id(Integer e_id) {...}
public String getE_name() {...}
public void setE_name(String e_name) {...}
public char getE_gender() {...}
public void setE_gender(char e_gender) {...}
public String getE_address() {...}
public void setE_address(String e_address) {...}
@Override
public String toString() {...}
}
很明显,我们设计的JavaBean的属性名称和employee表的列并不是对应的,此时我们可以通过在SQL语句给列名起别名的方式来保证正确性,但是一般不着这样做,而是从配置文件下手,应该如何写配置文件呢? 同样这个示例也是一个多表查询的例子:
<resultMap type="com.xpu.bean.Employee" id="resultMap_01">
<id column="id" property="e_id" />
<result column="name" property="e_name" />
<result column="gender" property="e_gender" />
<result column="address" property="e_address" />
<result column="d_id" property="dept.d_id"/>
<result column="d_name" property="dept.d_name"/>
</resultMap>
<!-- 多表查询 -->
<select id="selectAll" resultMap="resultMap_01">
select e.id id, e.name name, e.gender gender, e.address
address, d.d_id d_id, d.d_name d_name
from employee e, department d where e.d_id = d.d_id
</select>
在上述配置文件中,resultMap的id必须和上面配置的id一致,这样就解决了即使JavaBean和表的字段不匹配也可以查询到数据了!还有需要注意的是:resultMap 中的id是主键,需要使用id标签,其他属性或字段都是result标签,在IEmployee.java中写法和以前一致,看看调用测试:
public void fun(){
Reader reader = Resources.getResourceAsReader("resource.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = factory.openSession(true);
IEmployeeDao mapper = session.getMapper(IEmployeeDao.class);
List<Employee> list = mapper.selectAll2();
for (Employee employee : list) {
System.out.println(employee);
}
}
这样就完成了多表查询,而且是一次性完成,下面看看如何分步查询?
分步查询与延迟加载
<!-- association 可以使用分步骤查询 -->
<resultMap type="com.xpu.bean.Employee" id="resultMap_02">
<id column="id" property="e_id" />
<result column="name" property="e_name" />
<result column="gender" property="e_gender" />
<result column="address" property="e_address" />
<association property="dept" javaType="com.xpu.bean.Department">
<id column="d_id" property="d_id"/>
<result column="d_name" property="d_name"/>
</association>
</resultMap>
<select id="selectAll2" resultMap="resultMap_02">
select e.id id, e.name name, e.gender gender, e.address address, d.d_id d_id, d.d_name d_name
from employee e, department d where e.d_id = d.d_id
</select>
通过association 标签制定一个分步查询的下一个步骤,其实总体上来说就是先根据Id找到员工employee,再根据employee的d_id字段查找到对应的部门,所以这个是分步骤的多表查询: Department.xml 和IDpartmentDao.java:
<mapper namespace="com.xpu.dao.IDepartmentDao">
<select id="getDepartmentById" resultType="com.xpu.bean.Department">
select * from department where d_id = #{d_id}
</select>
</mapper>
public interface IDepartmentDao {
public Department getDepartmentById(String id);
}
为什么要分步骤查询呢?假设电商平台,查询订单信息时需要查询部分的用户信息;相对于关联查询来说,分步查询将查询SQL拆分,这里引申出一个问题是:分步查询与关联表查询的不同
关联表查询能够有效的简化代码编写逻辑,减小代码编写难度,同时尽量避免出错,而分步查询则能够增强代码的可用性,关联表查询毕竟只需要查询一次数据库,对于业务量较小的系统来说,效率更高,数据库压 力相对较小;分步查询虽然需要多次查询数据,但是这也意味着能够更好地使用数据缓存服务,且缓存的数据耦合度低,利用率高,而且单次查询效率很高,数据库压力较小(对于业务量较大的系统来说)。还有一点则是数据库锁的问题,毕竟关联查询是多表同时使用,分步查询每次只操作一个表!
分步骤查询很多时候是配合延迟加载使用,下面是一个示例:
<resultMap type="com.xpu.bean.Employee" id="selectByStep">
<id column="id" property="e_id" />
<result column="name" property="e_name" />
<result column="gender" property="e_gender" />
<result column="address" property="e_address" />
<association property="dept" select="com.xpu.dao.IDepartmentDao.getDepartmentById"
column="d_id">
</association>
</resultMap>
<select id="selectStep" resultMap="selectByStep">
select * from employee where id=#{id}
</select>
当在某项业务里需要同时获取两份数据,但是其中份数据又不需要立即使用,当程序需要加载另一份数据时,再去请求数据库来获取那一份数据,而不是一次性将数据全部取出来或者重新发送一份请求,这就是延迟加载。为了节省内存的消耗!
想要使用懒加载,有些配置是默认的,但是由于版本在更替,有些默认设置还是自己指明比较好,如果想单个开启或禁用延迟加载,可以使用fetchType属性来实现,设置延迟加载需要在总体配置文件中配置如下:
<!-- 防止版本更新发生改变 -->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
这个是测试懒加载的代码,需要用的时候再加载:
Employee step = mapper.selectStep("1");
// 这个时候还没有用到d_id、等到用到的时候再加载,节省内存开销
System.out.println(step.getE_name());
//执行下面这句代码的时候才会去查询数据库获得相应的数据
System.out.println(step.getDept().getD_name());
MyBatis的缓存
Mybatis中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存是指SqlSession级别的缓存,当在同一个SqlSession中进行相同的SQL语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存1024条SQL。二级缓存是指可以跨SqlSession的缓存,Mybatis中进行SQL查询是通过org.apache.ibatis.executor.Executor接口进行的,总体来讲,它一共有两类实现,一类是BaseExecutor,一类是CachingExecutor。前者是非启用二级缓存时使用的,而后者是采用的装饰器模式,在启用了二级缓存时使用,当二级缓存没有命中时,底层还是通过BaseExecutor来实现的:
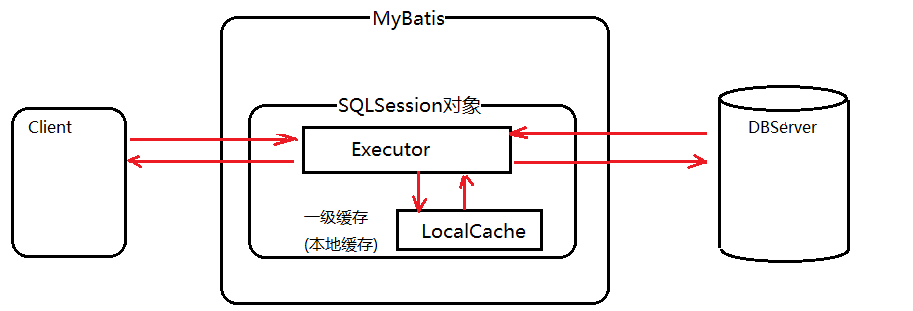
一、一级缓存的有效期是多久呢?
1、当不是同一个SqlSession对象的时候,s1对象的缓存只能s1用 2、当Sqlsession对象调用clearCache()的时候,缓存清除 3、当SqlSession对象close的时候 4、当在两次查询中穿插了add、delete、update的时候,缓存就无效了
二、一级缓存如何实现呢?
1、一级缓存通过简单地Map来实现的,没有对Map集合大小的限制
2、一级缓存是一个粗粒度的缓存,没有办法去精确的控制数据是否过长,以及更新数据
3、多个SqlSession对象缓存的数据无法共享,为了解决这个问题就需要二级缓存
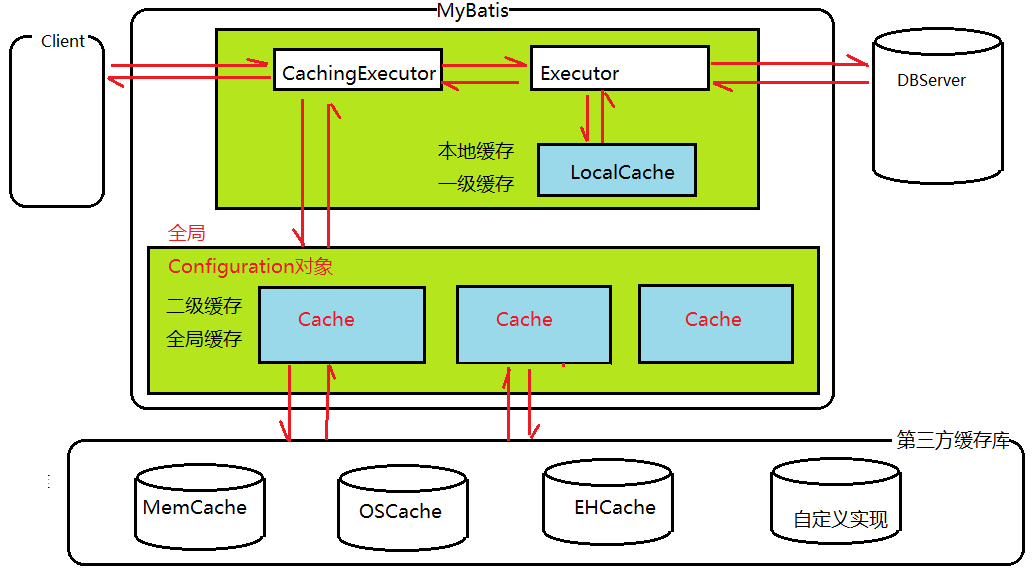 二级缓存属于nameSpace级别(一个xml文件对应一个二级缓存),在一个Web应用中,你可以理解为只有一个二级缓存!二级缓存并没有默认开启,那么如何开启二级缓存呢?通样在全局配置文件中配置如下:
二级缓存属于nameSpace级别(一个xml文件对应一个二级缓存),在一个Web应用中,你可以理解为只有一个二级缓存!二级缓存并没有默认开启,那么如何开启二级缓存呢?通样在全局配置文件中配置如下:
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
注意配置的顺序:
在前面的一定要将标签配置在前面,否则是无法解析导致出错的!
我们要想使用二级缓存,是需要在对应的xml文件中定义其中的查询语句需要使用哪个cache来缓存数据的。这有两种方式可以定义,一种是通过cache元素定义,一种是通过cache-ref元素来定义。但是需要注意的是对于同一个Mapper来讲,它只能使用一个Cache,当同时使用了和时使用定义的优先级更高。Mapper使用的Cache是与我们的Mapper对应的namespace绑定的,一个namespace最多只会有一个Cache与其绑定,所以我配置了一个 useCache="true"
<!-- 多表查询 -->
<select id="selectAll" resultMap="resultMap_01" useCache="true">
select e.id id, e.name name, e.gender gender, e.address address, d.d_id d_id, d.d_name d_name
from employee e, department d where e.d_id = d.d_id
</select>
还有一个问题,在使用缓存的时候需要引入一些Jar包,除了cglib别忘记其他的jar包,并且JavaBean要实现序列化接口:
 好了,MyBatis学习至此就算是入了个门,重点还是以后在实际开发中的应用,以后遇到了问题再慢慢总结(下面的图纯粹是写完娱乐一下,哈哈),如果文中有错误还望及时指出我不胜感激!
好了,MyBatis学习至此就算是入了个门,重点还是以后在实际开发中的应用,以后遇到了问题再慢慢总结(下面的图纯粹是写完娱乐一下,哈哈),如果文中有错误还望及时指出我不胜感激!
