一元线性回归的梯度下降算法实现
一元线性回归算法是机器学习部分接触的第一个算法,更重要的通过一元线性回归足以了解监督学习过程完整的流程,之所以称为监督学习是因为对于每个数据来说,已经存在了正确的答案。本文所有的内容都只是在学习Andrew Ng老师的机器学习课程中记的笔记,并且自己用Ocatve实现了一元线性回归的梯度下降算法。
其实例子是预测住房价格的场景,数据集就包含已知的房屋面积与房屋价格,可以做的一件事就是构建一个模型,近似看成一条直线,从这个数据模型来预测房子的售卖价格。
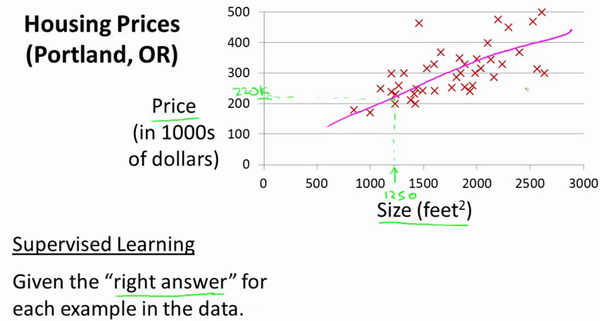
我们将要用来描述这个回归问题的标记如下:
$m$ 代表训练集中实例的数量
$x$ 代表特征/输入变量,房子面积
$y$ 代表目标变量/输出变量,房价
$(x, y)$ 代表训练集中的实例,一组已知面积和价格的数据
$\left(x^{(i)}, y^{(i)}\right)$ 代表第 个观察实例,第 $i$ 组已知面积和价格的数据
$h$ 代表学习算法的解决方案或函数也称为假设,面积和价格的关系
$$ h_{\theta}(x)=\theta_{0}+\theta_{1} x $$ 因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
代价函数
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数,说白了就是尽可能的让直线与数据拟合,所以关于此例的代价函数被定义为: $$ J\left(\theta_{0}, \theta_{1}\right)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} $$ 简单理解,代价函数越小,证明所选的参数构成的算法或者函数拟合性越好。
我们需要做的是编写程序来找出这些最小化代价函数的和的值,所以需要一种算法能够自动地找出能使代价函数最小化的参数和的值,那么这个算法就是梯度下降算法。
结合图形不难发现,线性回归的代价函数是一个凸函数,注意:边缘凸,中间凹的叫凸函数。边缘凹,中间凸的叫凹函数。对于凸函数,随便选区一个初始值,使用梯度下降法,肯定会逐步得到一个全局最小值。
梯度下降算法
开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值,因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。
但是由于线性回归的代价函数是凸函数,所以肯定只有一个全局最小值,非常适合用梯度下降法。
梯度下降算法的公式为: $$ \theta_{j}:=\theta_{j}-\alpha \frac{\partial}{\partial \theta_{j}} J\left(\theta_{0}, \theta_{1}\right) \quad $$ 对 $\theta_{}$ 赋值,使得$J(\theta_{})$按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。
其中 $\alpha$ 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,如果太大可能会直接越过最低点,甚至可能无法收敛。
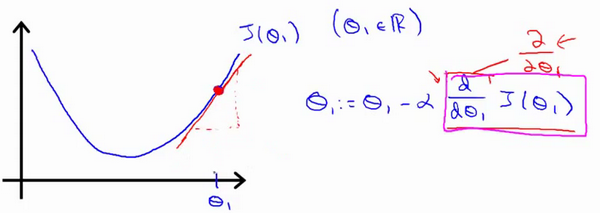
对这个线性回归问题运用梯度下降法,关键在于求出代价函数的导数,存在多个变量时,即就是单个变量的偏导数而已,所以我们关心的是这两个微分项: $ \alpha \frac{\partial}{\partial \theta_{0}} J\left(\theta_{0}, \theta_{1}\right), \quad \alpha \frac{\partial}{\partial \theta_{1}} J\left(\theta_{0}, \theta_{1}\right) 。 $
$$ \begin{array}{l} \frac{\partial}{\partial \theta_{j}} J\left(\theta_{0}, \theta_{1}\right)=\frac{\partial}{\partial \theta_{j}} \frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} \\ \\ j=0 \text { 时: } \frac{\partial}{\partial \theta_{0}} J\left(\theta_{0}, \theta_{1}\right)=\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \\ \\ j=1 \text { 时: } \frac{\partial}{\partial \theta_{1}} J\left(\theta_{0}, \theta_{1}\right)=\frac{1}{m} \sum_{i=1}^{m}\left(\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \cdot x^{(i)}\right) \end{array} $$ 所以,$\theta_{0}$ 和 $\theta_{1}$ 的更新规则就变成了: $$ \begin{aligned} \theta_{0} &:=\theta_{0}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \\ \theta_{1} &:=\theta_{1}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \cdot x^{(i)} \end{aligned} $$ 那么还存在一个问题,如果我将 $\theta_{0} 、\theta_{1}$ 参数初始化的时候已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率保持不变时,梯度下降也可以收敛到局部最低点。
代码实现
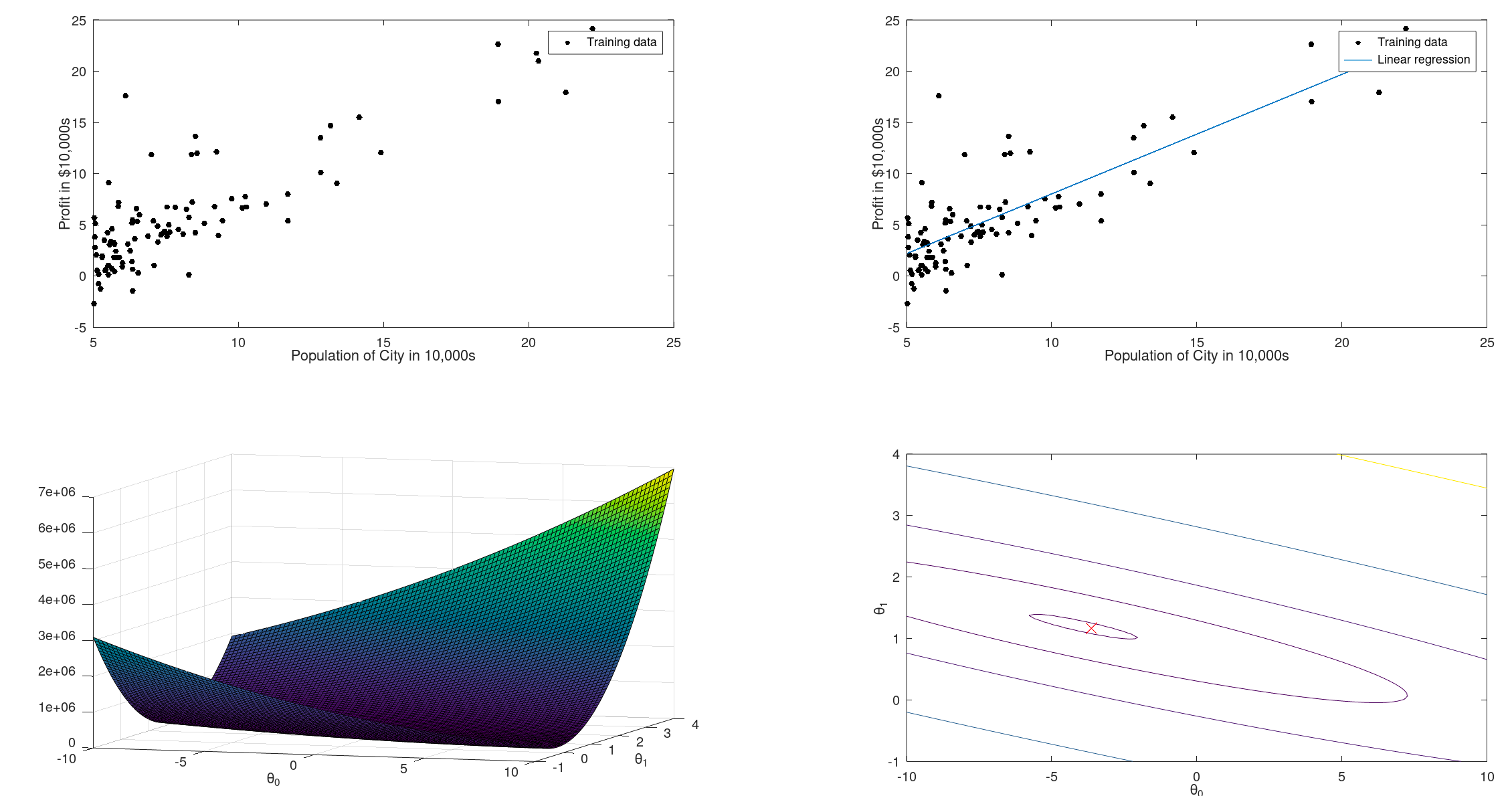
数据集我会放到末尾 data.txt 中,现在先通过离散图展示出来目前的数据集:
代价函数:
function J = calc_costs (x, y, theta)
% costs function
m = length(y);
J = 0;
J = 0.5 * m * sum((x * theta - y).^2);
endfunction
梯度下降函数
function [theta, J_history] = gradient_descent(x, y, theta, alpha, num_iters)
% Gradient descent function
m = length(y);
J_history = zeros(num_iters, 1);
theta_save = theta;
for i = 1:num_iters
% Be sure to update at the same time
theta(1) = theta(1) - alpha / m * sum(x * theta_save - y);
theta(2) = theta(2) - alpha / m * sum((x * theta_save - y) .* x(:,2));
theta_save = theta;
J_history(i) = calc_costs(x, y, theta);
endfor
J_history
endfunction
绘图函数(房价-面积数据)
function plot_data(x, y)
plot(x, y, 'k.', 'MarkerSize', 10);
ylabel('Profit in $10,000s');
xlabel('Population of City in 10,000s');
legend('Training data');
hold
end
开始进行梯度下降,得到最优参数
# load data
data = load('train_data.txt');
x = data(:, 1);
y = data(:, 2);
m = length(y);
# show data
subplot(2, 2, 1)
plot_data(x, y);
X = [ones(m, 1), data(:,1)];
theta = zeros(2, 1);
iterations = 1500; %迭代次数设为1500,学习速率为0.01
alpha = 0.01;
calc_costs(X, y, theta);
theta = gradient_descent(X, y, theta, alpha, iterations);
fprintf('gradient descent ret: %f %f \n', theta(1), theta(2));
hold on;
subplot(2, 2, 2)
plot_data(x, y);
plot(X(:,2), X*theta, '-')
legend('Training data', 'Linear regression')
theta0_vals = linspace(-10, 10, 100);
theta1_vals = linspace(-1, 4, 100);
% initialize J_vals to a matrix of 0's
J_vals = zeros(length(theta0_vals), length(theta1_vals)); %构造n*n的0矩阵
% Fill out J_vals
for i = 1:length(theta0_vals)
for j = 1:length(theta1_vals)
t = [theta0_vals(i); theta1_vals(j)]; %构造列向量
J_vals(i,j) = calc_costs(X, y, t);
end
end
J_vals = J_vals';
% Surface plot
subplot(2, 2, 3)
surf(theta0_vals, theta1_vals, J_vals) %画图,J由theta0和theta1确定
xlabel('\theta_0'); ylabel('\theta_1');
% Contour plot 轮廓图
subplot(2, 2, 4)
% Plot J_vals as 15 contours spaced logarithmically between 0.01 and 100
contour(theta0_vals, theta1_vals, J_vals, logspace(0, 15, 30))
xlabel('\theta_0'); ylabel('\theta_1');
hold on;
plot(theta(1), theta(2), 'rx');
得到拟合结果图:
线性代数不仅仅在线性回归中应用广泛,它其中的矩阵和向量将有助于帮助我们实现之后更多的机器学习模型,并在计算上更有效率。正是因为这些矩阵和向量提供了一种有效的方式来组织大量的数据,为了实现机器学习算法,基础的线性代数知识必不可少。