生成器、迭代器、闭包与装饰器
生成器
创建生成器方法一
要创建⼀个⽣成器,有很多种⽅法。第⼀种⽅法很简单,只要把⼀个列表⽣成式的 [ ] 改成 ( )
In [1]: L = [x*2 for x in range(5)]
In [2]: L
Out[2]: [0, 2, 4, 6, 8]
In [3]: G = (x*2 for x in range(5))
In [4]: G
Out[4]: <generator object <genexpr> at 0x000001B281507A98>
创建 L 和 G 的区别仅在于最外层的 [ ] 和 ( ) , L 是列表,G 是生成器。我们可以直接打印出L的每个元素,但我们怎么打印出G的每个元素呢?使用next函数
In [3]: G = (x*2 for x in range(5))
In [4]: G
Out[4]: <generator object <genexpr> at 0x000001B281507A98>
In [5]: next(G)
Out[5]: 0
In [6]: next(G)
Out[6]: 2
In [7]: next(G)
Out[7]: 4
In [8]: next(G)
Out[8]: 6
In [9]: next(G)
Out[9]: 8
In [10]: next(G)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-10-b4d1fcb0baf1> in <module>()
----> 1 next(G)
⽣成器保存的是算法,每次调⽤ next(G) ,就计算出 G 的下⼀个元素的值,直到计算到最后.个元素,没有更多的元素时,抛出 StopIteration 的异常。当然,这种不断调⽤ next()实在是太变态了,正确的⽅法是使⽤ for 循环,因为⽣成器也是可迭代对象。所以,我们创建了⼀个⽣成器后,基本上永远不会调⽤ next(),而是通过for循环来迭代它,并且不需要关心StopIteration 异常!
创建生成器方法二
先看看这个斐波那契函数的例子:
In [3]: def creatNum():
...: a,b = 0,1
...: for i in range(5): # 生成5个斐波那契数
...: print(b)
...: a,b = b,a+b
...:
In [4]: creatNum()
接下来我们把它改成生成器:
#-*- coding:utf-8 -*-
def creatNum():
print("---start---")
a,b = 0,1
for i in range(5):
print("---1---")
yield b
print("---2---")
a,b = b,a+b
print("---3---")
print("---stop---")
接下来我们将这个模块导入:
In [1]: from test import *
In [2]: a = creatNum()
In [3]: next(a)
---start---
---1---
Out[3]: 1
In [4]: next(a)
---2---
---3---
---1---
Out[4]: 1
In [5]: next(a)
---2---
---3---
---1---
Out[5]: 2
我们在循环过程中不断调⽤ yield ,就会不断中断。当然要给循环设置⼀个条件来退出循环,不然就会产⽣⼀个⽆限数列出来。同样的,把函数改成generator后,我们基本上从来不会⽤ next() 来获取下⼀个返回值,⽽是直接使⽤ for 循环来迭代!
In [1]: from test import *
In [2]: a = creatNum()
In [3]: while True:
...: try:
...: print("value:%d" % next(a))
...: except StopIteration as e:
...: print("生成器返回值:%s" % e.value)
...: break
...:
---start---
---1---
value:1
---2---
---3---
---1---
value:1
---2---
---3---
---1---
value:2
---2---
---3---
---1---
value:3
---2---
---3---
---1---
value:5
---2---
---3---
---stop---
生成器返回值:None
注意:next(a)与a.__next__()是等价的
send
In [1]: def test():
...: i = 0
...: while i<5:
...: tmp = yield i
...: print(tmp)
...: i += 1
...:
In [2]: t = test()
In [3]: t.__next__()
Out[3]: 0
In [4]: t.__next__()
None
Out[4]: 1
In [5]: t.__next__()
None
Out[5]: 2
为什么会打印出None呢?是应为yield i执行完毕之后会把结果直接返回,但是不会赋值给tmp,所以每次打印都是None,此时使用send方法就会在yield i执行完毕之并返回结果之后给yield i赋值:
In [1]: def test():
...: i = 0
...: while i<5:
...: tmp = yield i
...: print(tmp)
...: i += 1
...:
In [2]: t = test()
In [3]: t.__next__()
Out[3]: 0
In [4]: t.__next__()
None
Out[4]: 1
In [5]: t.__next__()
None
Out[5]: 2
In [6]: t.send("Hello")
Hello
Out[6]: 3
In [7]: t.send("HelloWorld")
HelloWorld
Out[7]: 4
send的注意事项
In [8]: def test():
...: ...: i = 0
...: ...: while i<5:
...: ...: tmp = yield i
...: ...: print(tmp)
...: ...: i += 1
...: ...:
...:
In [9]: a = test()
In [10]: a.send("---")
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-dc33d05574fa> in <module>()
----> 1 a.send("---")
TypeError: can't send non-None value to a just-started generator
不能在第一次生成的时候就调用send方法,因为代码还未执行到yield i,所以要先使用__next()__,再使用send()
当然还有一个方法:
In [11]: def test():
...: ...: i = 0
...: ...: while i<5:
...: ...: tmp = yield i
...: ...: print(tmp)
...: ...: i += 1
...: ...:
...:
In [12]: t = test()
In [13]: t.send(None)
Out[13]: 0
总结
生成器是这样一个函数,它记住上一次返回时在函数体中的位置。对生成器函数的第二次(或者第n次)调用跳转至该函数体中间,而上次调用的所有局部变量都保持不变!
⽣成器不仅“记住”了它数据状态;⽣成器还“记住”了它在流控制构造(在命令式编程中,这种构造不只是数据值)中的位置
生成器的特点
- 节约内存,在超大列表的情况下是非常吃内存的!
- 迭代到下⼀次的调⽤时,所使⽤的参数都是第⼀次所保留下的,即是说,在整个所有函数调⽤的参数都是第⼀次所调⽤时保留的,⽽不是新创建的,这样非常高效! 迭代是访问集合元素的⼀种⽅式。迭代器是⼀个可以记住遍历的位置的对象。迭代器对象从集合的第⼀个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退!
可迭代对象
以直接作⽤于 for 循环的数据类型有以下⼏种: ⼀类是集合数据类型,如 list 、 tuple 、 dict 、 set 、 str 等; ⼀类是 generator ,包括⽣成器和带 yield 的generator function。 这些可以直接作⽤于 for 循环的对象统称为可迭代对象: Iterable
In [1]: for s in "Hello":
...: print(s)
...:
H
e
l
l
o
In [2]: b = (x for x in range(5))
In [3]: b
Out[3]: <generator object <genexpr> at 0x0000021FEBC98A40>
In [4]: for tmp in b:
...: print(tmp)
...:
0
1
2
3
4
判断是否可以迭代
可以使⽤isinstance()判断一个对象是否是Iterable (可迭代的)对象:
In [1]: from collections import Iterable
In [2]: isinstance([],Iterable)
Out[2]: True
In [3]: isinstance({},Iterable)
Out[3]: True
In [4]: isinstance('abc',Iterable)
Out[4]: True
In [5]: isinstance((x for x in range(5)),Iterable)
Out[5]: True
⽽⽣成器不但可以作⽤于 for 循环,还可以被 next() 函数不断调⽤并返回下⼀个值,直到最后抛出 StopIteration 错误表示⽆法继续返回下⼀个值了!
迭代器
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance() 判断某个对象是否是 Iterator (迭代器)对象
In [1]: from collections import Iterator
In [2]: isinstance((x for x in range(10)),Iterator)
Out[2]: True
In [3]: isinstance([],Iterator)
Out[3]: False
In [4]: isinstance({},Iterator)
Out[4]: False
In [5]: isinstance("abc",Iterator)
Out[5]: False
In [6]: isinstance(100,Iterator)
Out[6]: False
所以说,生成器也是迭代器的一种!
iter()函数
生成器都是Iterator对象,但是list、dict、str虽然是Iterable,去不是Iterator
In [7]: isinstance(iter("abc"),Iterator)
Out[7]: True
In [8]: isinstance(iter([]),Iterator)
Out[8]: True
总结
- 凡是可作⽤于 for 循环的对象都是 Iterable 类型
- 凡是可作⽤于 next() 函数的对象都是 Iterator 类型
- 集合数据类型如 list 、 dict 、 str 等是 Iterable 但不是 Iterator,不过可以通过 iter() 函数获得⼀个 Iterator 对象。
闭包
内部函数对外部函数作用域变量的引用(非全局变量),则称内部函数为闭包!
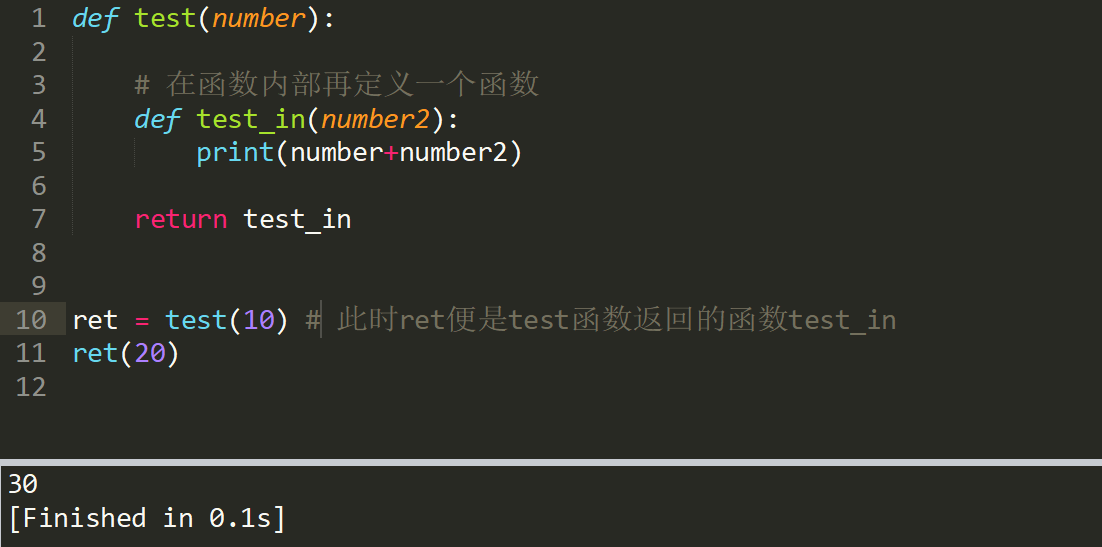
应用实例
def linr_conf(a, b):
def line(x):
return a*x + b
return line
# 相当于通过同一个方法构建了两种直线模型
line1 = linr_conf(1,1)
line2 = linr_conf(4,5)
print(line1(5))
print(line2(5))
这个例子中,函数line与变量a,b构成闭包。在创建闭包的时候,我们通过line_conf的参数a,b说明了这两个变量的取值,这样,我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的直线表达函数。由此,我们可以看到,闭包也具有提高代码可复用性的作用! 如果没有闭包,我们需要每次创建直线函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性!
总结
- 闭包似优化了变量,原来需要类对象完成的工作,闭包也可以完成
- 由于闭包引用了外部函数的局部变量,则外部函数局部变量没有释放,消耗内存
装饰器
装饰器是程序开发中经常会⽤到的⼀个功能,⽤好了装饰器,开发效率如⻁添翼,所以这也是Python⾯试中必问的问题,但对于好多初次接触这个知识的⼈来讲,这个功能有点绕,⾃学时直接绕过去了,然后⾯试问到了就挂了,因为装饰器是程序开发的基础知识,这个都不会,别跟⼈家说你会Python, 看了下⾯的⽂章,保证你学会装饰器!
模拟场景
假设这些都是核心业务方法,但是现在的需求是:不能让每一个人都随意的调用这些方法,为了安全起见,在调用这些方法的时候必须进行权限验证!
def coreCode():
...
def coreCode2():
...
def coreCode3():
...
为了增加权限验证的逻辑,修改后的代码如下:
def coreCode():
# 验证一
# 验证二
...
def coreCode2():
# 验证一
# 验证二
...
def coreCode3():
# 验证一
# 验证二
...
很显然这是极不合理的,代码太过于冗余,修改之后:
def check_call():
# 验证-
# 验证二
def coreCode():
check_call()
...
def coreCode2():
check_call()
...
def coreCode3():
check_call()
...
这回修改之后的代码显得不是很冗余,但是违反了开放封闭原则,这样会修改核心业务代码,也是非常不推荐的做法,接着装饰器就登场了:
def check(func):
def inner():
# 验证1
# 验证2
func()
return inner
@check
def coreCode():
...
@check
def coreCode2():
...
@check
def coreCode3():
...
对于上述代码,也是仅仅对基础平台的代码进行修改,就可以实现在其他人调用coreCode1、coreCode2、coreCode3的时候都进行验证操作!
def check(func):
def inner():
print("验证1...")
print("验证2...")
print("验证3...")
func()
return inner
@check
def coreCode1():
print("coreCode1...")
def coreCode2():
print("coreCode2...")
coreCode1()
print("-"*30)
coreCode2()
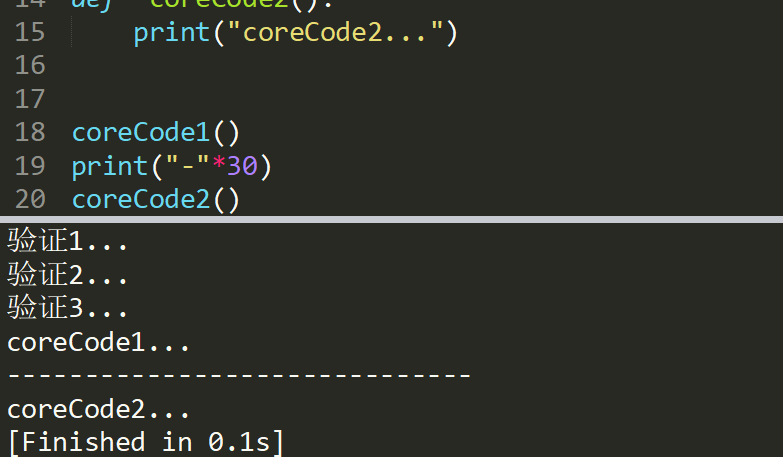 python解释器就会从上到下解释代码,步骤如下:
python解释器就会从上到下解释代码,步骤如下:
- def check(func): ==>将check函数加载到内存
- @check 没错, 从表⾯上看解释器仅仅会解释这两句代码,因为函数在没有被调⽤之前其内部代码不会被执行。从表面上看解释器着实会执行这两句,但是 @check 这⼀句代码里却有大文章, @函数名 是python的⼀种语法糖.
@check到底做了什么
- 执行check函数,并且会把@check下面的函数当做check函数的参数,所以内部就会执行验证的逻辑,执行完毕才去调用参数中的方法!
- check的返回值,将执行完毕的check函数返回值赋值给@check下面的函数名coreCode
- 所以想要执行coreCode 函数时,就会执行新coreCode函数,在新coreCode函数内部先执⾏验证,再执行原来的coreCode函数,然后将原来coreCode函数的返回值返回给了业务调⽤者。
再议装饰器
装饰器的装饰执行时间:并不是在调用的时候才去装饰函数,而是在解释器解释到那一句的时候就已经装饰了函数!