RNN循环神经网络(二)
无论是随时间波动的股票价格,还是有着前后文逻辑的自然语言,RNN 都能捕捉其中的“时间依赖性”,今天将通过两个经典的入门实战项目:中国平安股价预测 和 字符级文本生成,来揭开 RNN 和 LSTM 的神秘面纱。从数据预处理、模型构建到结果分析,深入浅出地实战 RNN 及其变体 LSTM 的应用。
无论是随时间波动的股票价格,还是有着前后文逻辑的自然语言,RNN 都能捕捉其中的“时间依赖性”,今天将通过两个经典的入门实战项目:中国平安股价预测 和 字符级文本生成,来揭开 RNN 和 LSTM 的神秘面纱。从数据预处理、模型构建到结果分析,深入浅出地实战 RNN 及其变体 LSTM 的应用。
循环神经网络(RNN)是深度学习领域处理序列数据的基础架构,广泛应用于自然语言处理、语音识别、时间序列预测等任务。本文从零开始,深入剖析RNN的核心机制、参数共享原理以及前向传播过程,详细讲解梯度消失问题的数学本质,并系统介绍LSTM如何通过门控机制有效解决长距离依赖。此外,还将探讨双向RNN、深度RNN、GRU等高级架构变体的设计思想与实际应用场景,帮助读者全面掌握RNN及其演进历程。
最近开发OpenAI提供的Assistant功能,其中有个插件叫做Code Interpreter,由于需要把Assistant的分析过程在Vue中展示一下,方便问题定位,所以Code Interpreter生成的代码肯定也是要展示的,其他过程几乎都是Markdown的格式,所以特此记录下在Vue中如何渲染Markdown,在其他场景也会经常遇到渲染Markdown的需求。
随着AI大模型技术的快速发展,其实从今年5月份开始,我也越发觉得LLM在企业中的应用越来越广泛,因此我也开始学习LLM,本文是一些LLM相关的学习笔记,主要记录了LLM的发展历程、应用场景、基本的技术原理等,另外本篇还侧重于介绍NLP中一些常见的概念,这样能快速的切入到大模型的学习中。
OpenAI在2020年5月发布了GPT-3的论文,而在2022年2月1日,GPT3.5也随之问世。国内对大模型的热情似乎从22年的12月开始高涨。对我个人而言,从我首次打开GPT3.5的对话页面到现在,已经过去了九个月。在此,我想分享一下我对大模型的一些想法。
在本节中将继续探讨CNN的核心概念以及一些经典的CNN框架(LeNet、AlexNet、VGG16等),以更好地理解这一强大的图像处理工具。卷积神经网络是一种深度学习模型,广泛应用于图像识别和处理任务。CNN通过卷积层、池化层和全连接层等结构,能够有效提取图像中的特征信息,从而实现分类、检测等任务。
在深度学习的探索旅程中,我们从模拟人类神经网络结构的多层感知器(MLP)开始,逐步探索了非线性预测的实现。通过逻辑回归模型的组合,构建了能够处理复杂预测任务的庞大网络。通过实践我们了解了MLP在图像识别任务中的应用,特别是在处理MNIST数据集时的有效性。但是,面对更高分辨率的图像,MLP模型的局限性就显现出来,因为所需的参数数量巨大,导致计算量大增。为解决这一问题,引入了卷积神经网络(CNN)。
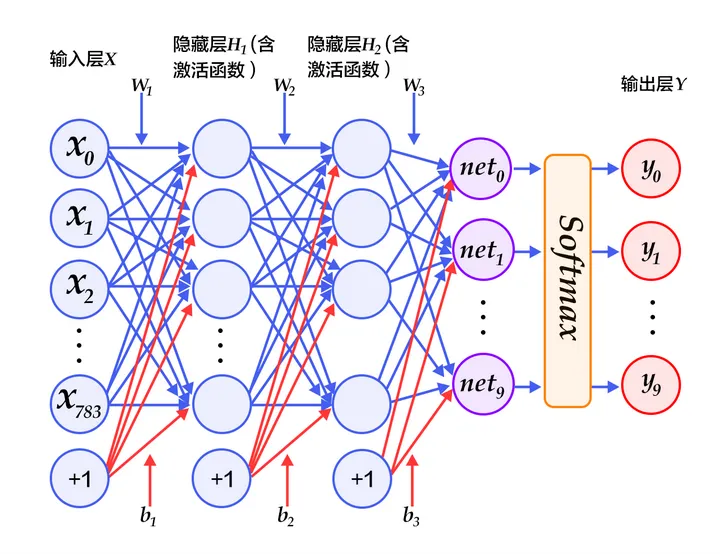
通过MLP实现手写数字识别是一个经典案例,mnist 是keras自带的一个用于手写数字识别的数据集,它的图像的分辨率是 $28 * 28$,也就是有784个像素点,它的训练集是60000个手写体图片及对应标签,测试集是10000个手写体图片及对应标签。本例中:输入层784个单元,两个隐藏层都是392个神经元,最后输出层10个单元: