gitignore与dockerignore文件的用法
在日常开发里,.gitignore 和 .dockerignore 都是“排除文件”的配置,但它们服务的对象并不一样:
.gitignore影响 Git 是否追踪某些文件。.dockerignore影响 Docker 构建镜像时,哪些文件不会被发送到构建上下文。
看起来只是少提交几个文件、少复制几个文件,实际它们会直接影响仓库干净程度、镜像构建速度、镜像安全性,以及多人协作时的稳定性。
在日常开发里,.gitignore 和 .dockerignore 都是“排除文件”的配置,但它们服务的对象并不一样:
.gitignore 影响 Git 是否追踪某些文件。.dockerignore 影响 Docker 构建镜像时,哪些文件不会被发送到构建上下文。看起来只是少提交几个文件、少复制几个文件,实际它们会直接影响仓库干净程度、镜像构建速度、镜像安全性,以及多人协作时的稳定性。
用过JDK9的同学应该发现了,finalize方法在JDK9中已经被标记为deprecated,今天探讨一下finalize方法。如果没有特别的原因,不要实现finalize方法,也不要指望利用它来进行资源回收。因为你无法保证finalize什么时候执行,执行的是否符合预期。使用不当会影响性能,导致程序死锁、挂起等。
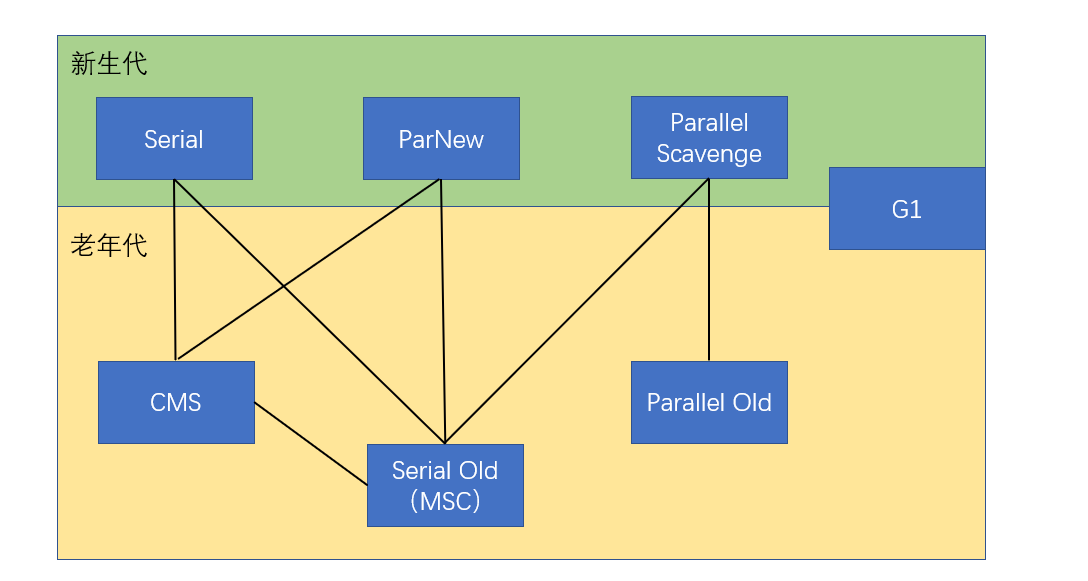
目前的垃圾收集器主要有7种,上图是他们的使用关系,连在一起的就可以配合使用。JDK11出现两种新的垃圾收集器,一个是Epsilon垃圾收集器,一个是ZGC垃圾收集器。垃圾收集器中很重要的两个概念:Stop-The-World和Safepoint。首先说说Stop-The-World:JVM由于要执行GC而停止了应用程序的执行,任何一种GC算法中都会发生。多数GC优化通过减少Stop-the -world发生的时间来提高程序性能。安全点 Safepoint:分析过程中对象引用关系不会发生变化的点,产生Safepoint的地方:方法调用、循环跳转、异常跳转等,安全点数量得适中。
本文主要是以通俗易懂的画图方式解释了标记清除算法和可达性分析算法,以及常用的回收算法(标记清除、标记整理、复制算法)以及整合百家之长的分代回收算法,另外还介绍了触发Full GC的几个场景。

本篇文章主要讲述了Java内存模型中的程序计数器、虚拟机栈、本地方法栈、元空间与堆,以及堆中的常量池。前面通过javap反编译class文件得到int add(int a, int b)函数的栈帧,主要分析了栈帧中JVM指令对应的局部变量表、操作数栈、程序计数器的状态变化。以及JDK7以后出现了替代永久代的元数据区,并分析了元数据区替换了永久代有哪些好处,主要分析了给字符串常量池带来的影响,并通过代码验证了元数据区相比永久代的优越性。学习了JVM性能调优的三个参数的意义和普通用法,最后探讨了并验证了JDK1.6与JDK1.7+的版本String类的intern方法的不同表现结果,分析了出现不同结果的原因,其实主要是JDK1.6的版本是建立副本再放入字符串常量池,而JDK1.7+版本时直接把堆上的对象的引用入池。
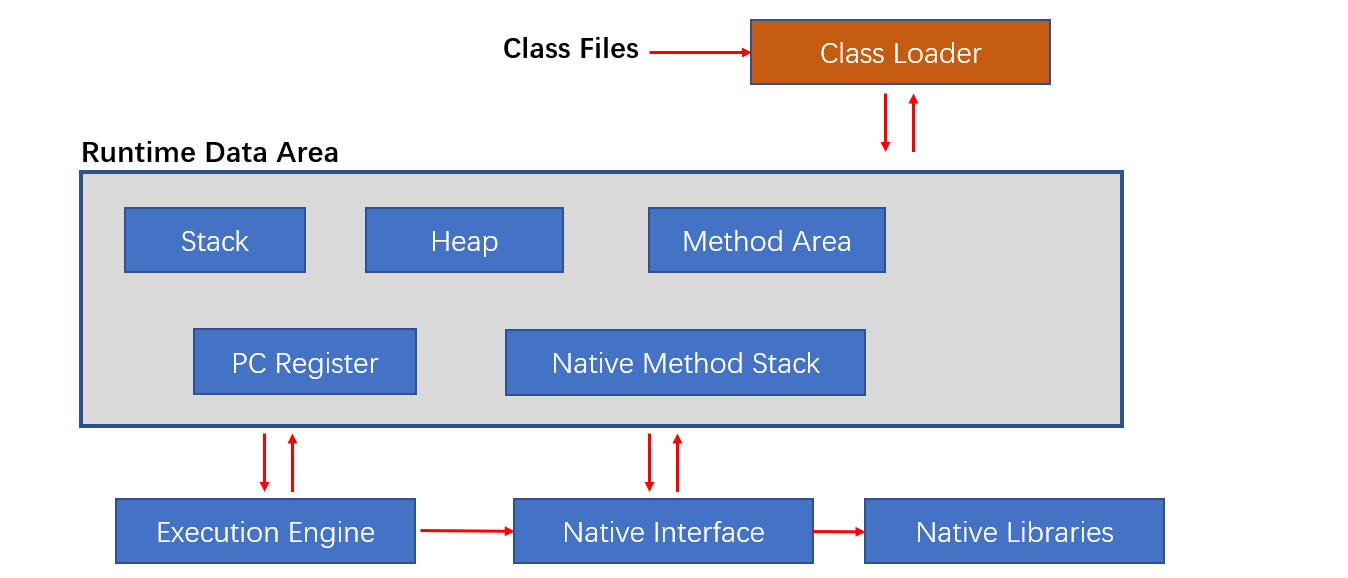
ClassLoader在Java中有着非常重要的作用,它主要工作在Class装载的加载阶段,其主要作用是从系统外部获得Class二进制数据流。它是Java的核心组件。所有的Class都是由ClassLoader 进行加载的。ClassLoader负责通过将Class文件里的二进制数据流装载进系统,然后交给Java虚拟机进行连接、初始化等操作。
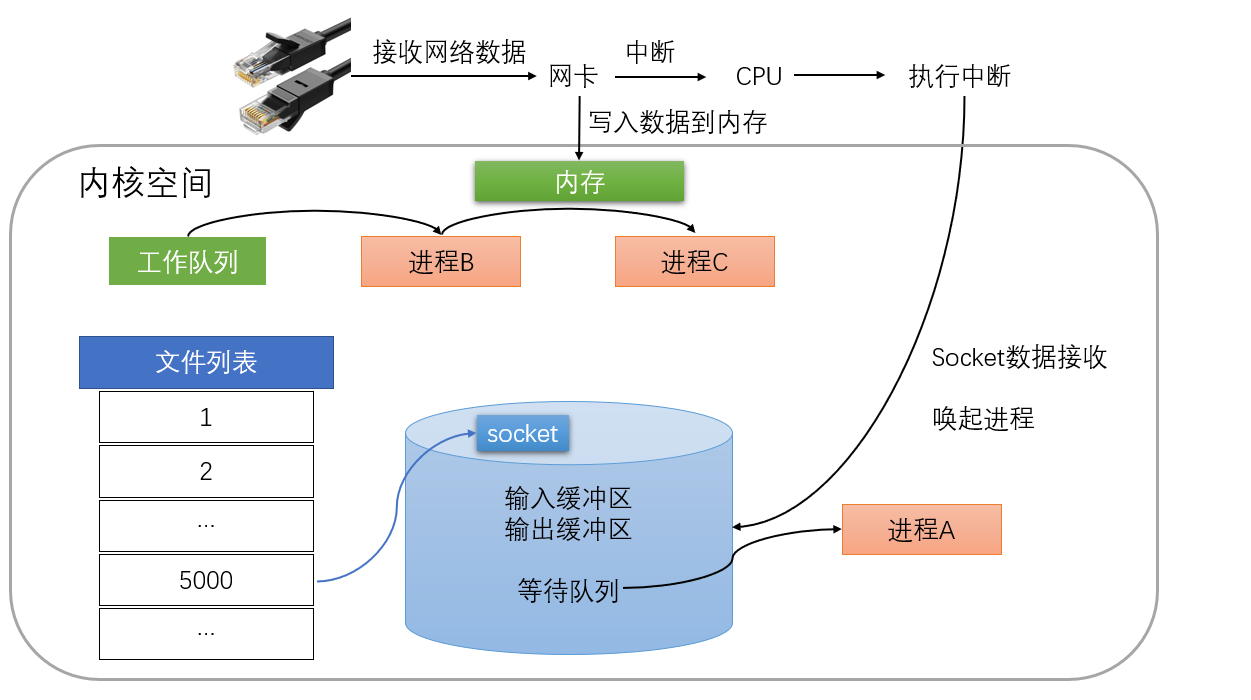
poll翻译过来是轮询的意思, 可以看到poll和epoll都有轮询的过程, 不同点在于:poll轮询的是所有的socket,而epoll只轮询就绪的socket。 epoll是开发linux高性能服务器的必备技术至,epoll本质,是服务端程序员的必须掌握的知识。 本文主要是利用图文讲述了select的原理和epoll相对于做出的优化,以及epoll的部分细节问题。
Nginx和Redis中都用到了epoll多路复用模型,本节将讲述常见的多路复用模型:select、poll和epoll,以及部分示例代码,还是先回顾IO的两个重要过程:
任何IO过程中,都包含两个步骤:第一是等待,第二是拷贝。而且在实际的应用场景中,等待消耗的时间往往都远远高于拷贝的时间。让IO更高效,最核心的办法就是让等待的时间尽量少。
在以前的文章中介绍了五种IO模型,分别是阻塞式IO、非阻塞式IO、信号驱动IO、多路复用IO、异步IO;前四种都属于同步IO。今天重点介绍的是多路复用IO,多路复用IO通俗讲就是一次等待多个文件描述符,减少了等待时间,提高了IO过程的效率(此IO过程并不是只是从内核态到用户态数据的拷贝,而是从发起IO请求直到IO完成的过程),接下来将介绍Linux的三种多路复用模型。