ESP32-S3 IDF开发入门指南
ESP32-S3 是乐鑫推出的一款高性能 Wi-Fi + Bluetooth 5 (LE) SoC,搭载双核 Xtensa LX7 处理器,主频高达 240 MHz,内置 512 KB SRAM,支持 USB OTG 和 USB-JTAG 调试接口。相比经典的 ESP32,S3 增强了 AI 加速指令集(向量指令),非常适合 AIoT 边缘计算场景。
ESP-IDF(Espressif IoT Development Framework)是乐鑫官方提供的开发框架,基于 FreeRTOS 实时操作系统,提供了完整的 Wi-Fi、蓝牙、外设驱动、电源管理等组件。本文将从零开始,记录使用 ESP-IDF 进行 ESP32-S3 开发的完整过程,包括环境搭建、项目创建、编译烧录、串口监视以及断点调试配置,特别是调试环节踩过的坑。
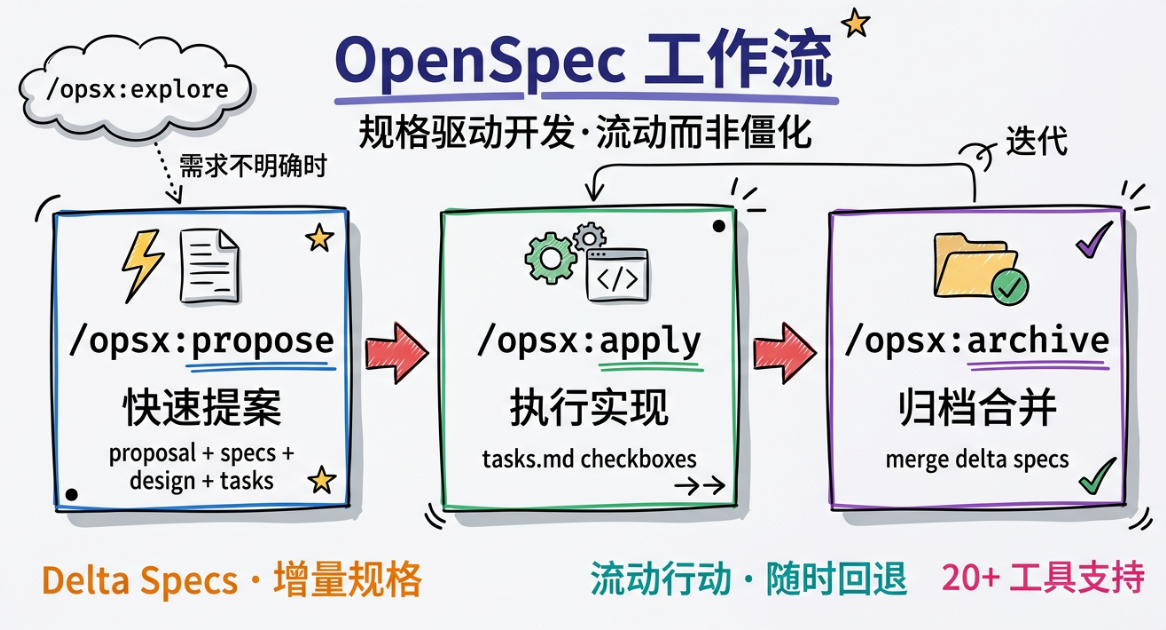 在 AI 辅助编程时代,我们见证了代码生成效率的惊人提升,但也面临着一个新的挑战:当 AI 能够快速生成大量代码时,如何确保系统的一致性、可维护性和演进方向?在上一篇文章《
在 AI 辅助编程时代,我们见证了代码生成效率的惊人提升,但也面临着一个新的挑战:当 AI 能够快速生成大量代码时,如何确保系统的一致性、可维护性和演进方向?在上一篇文章《