海量数据序列化协议Protobuf应用及核心源码分析
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。这里是Protobuf的官方手册 https://developers.google.cn/protocol-buffers/docs/overview
序列化协议考虑哪些点
为什么很多RPC框架底层会使用Protobuf协议作为序列化协议呢?我们不难想到,对于一个PRC框架来说,如果能以比较少的数据传输量传达更多的信息,并且序列化和反序列化的速度肯定是越快越好,而且如果具备跨语言的特性就更好,所以总结一下:
1、序列化之后的码流大小(占用网络带宽)字节长度 2、序列化和反序列化的性能(CPU资源占用) 3、是否支持跨语言
Protobuf相对于其他格式,Protobuf解析速度快(即序列化反序列化速度快),占用空间小,以及兼容性好,很适合做数据存储或网络通讯间的数据传输。
其他的一些序列化协议
- JSON
- XML
- Hessian
- Thrift
- Kryo
- protostuff
- ….
- Protobuf-google开源的
Java原生的序列化操作
先通过一个示例来看看Java的原生序列化是如何使用的:
1public class Teacher implements Serializable {
2 private static final long serialVersionUID = 8619259453444471644L;
3
4 private long teacherId;
5 private String name;
6 private int age;
7 private List<String> courses = new ArrayList<>();
8
9 public Teacher(long teacherId, String name, int age) {
10 this.teacherId = teacherId;
11 this.name = name;
12 this.age = age;
13 }
14
15 // getter and setter...
16
17 @Override
18 public String toString() {
19 return "Teacher{" +
20 "teacherId=" + teacherId +
21 ", name='" + name + '\'' +
22 ", age=" + age +
23 ", courses=" + courses +
24 '}';
25 }
26}
现在来测试一下Java的原生序列化:
1public class SerialTest {
2 public static void main(String[] args) throws Exception {
3 Teacher tim = new Teacher(1L, "Tim", 34);
4 tim.getCourses().add("Java");
5
6 // 序列化
7 byte[] byteArray = serialize(tim);
8 System.out.println(Arrays.toString(byteArray));
9
10 // 反序列化
11 Teacher teacher = deserialize(byteArray);
12 System.out.println(teacher);
13 }
14
15 // 序列化
16 private static byte[] serialize(Teacher tim) throws IOException {
17 ByteArrayOutputStream bos = new ByteArrayOutputStream();
18 ObjectOutputStream oos = new ObjectOutputStream(bos);
19 oos.writeObject(tim);
20 return bos.toByteArray();
21 }
22
23 // 反序列化
24 private static Teacher deserialize(byte[] bytes) throws Exception {
25 ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
26 return (Teacher)ois.readObject();
27 }
28}

通过测试我们可以看到,对于这样一个Teacher类,通过Java原生序列化方式序列化出来的byteArray结果是
1[-84, -19, 0, 5, 115, 114, 0, 23, 100, 97, 121, 95, 48, 53, 46, 112, 114,
2 111, 116, 111, 98, 117, 102, 46, 84, 101, 97, 99, 104, 101, 114, 119,
3 -99, -62, -50, 93, 124, 59, 92, 2, 0, 4, 73, 0, 3, 97, 103, 101, 74, 0,
4 9, 116, 101, 97, 99, 104, 101, 114, 73, 100, 76, 0, 7, 99, 111, 117,
5 114, 115, 101, 115, 116, 0, 16, 76, 106, 97, 118, 97, 47, 117, 116,
6 105, 108, 47, 76, 105, 115, 116, 59, 76, 0, 4, 110, 97, 109, 101, 116,
7 0, 18, 76, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 116, 114,
8 105, 110, 103, 59, 120, 112, 0, 0, 0, 34, 0, 0, 0, 0, 0, 0, 0, 1, 115,
9 114, 0, 19, 106, 97, 118, 97, 46, 117, 116, 105, 108, 46, 65, 114, 114,
10 97, 121, 76, 105, 115, 116, 120, -127, -46, 29, -103, -57, 97, -99, 3,
11 0, 1, 73, 0, 4, 115, 105, 122, 101, 120, 112, 0, 0, 0, 1, 119, 4, 0, 0,
12 0, 1, 116, 0, 4, 74, 97, 118, 97, 120, 116, 0, 3, 84, 105, 109]
通过Protobuf进行序列化
首先下载:
1https://github.com/protocolbuffers/protobuf/releases/download/v3.7.0/protobuf-java-3.7.0.zip
2
3https://github.com/protocolbuffers/protobuf/releases/download/v3.7.0/protoc-3.7.0-win64.zip
需要定义一个teacher.proto
1syntax = "proto2";
2option java_package = "edu.xpu";
3option java_outer_classname = "TeacherSerializer";
4
5message Teacher{
6 required int64 teacherId = 1;
7 required int32 age = 2;
8 required string name = 3;
9 repeated string courses = 4;
10}
上面这些字段的解释如下:
1message xxx {
2 // 字段规则:required -> 字段只能也必须出现 1 次
3 // 字段规则:optional -> 字段可出现 0 次或1次
4 // 字段规则:repeated -> 字段可出现任意多次(包括 0)
5 // 类型:int32、int64、sint32、sint64、string、32-bit ....
6 // 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字)
7 字段规则 类型 名称 = 字段编号;
8}

当前生成的Java文件中用到的类还需要我们引入Protobuf的依赖:
1<dependency>
2 <groupId>com.google.protobuf</groupId>
3 <artifactId>protobuf-java</artifactId>
4 <version>3.13.0</version>
5</dependency>
把生成的Java文件给复制到工程当中,然后测试一下序列化和反序列化
1import java.util.Arrays;
2
3public class ProtobufTest {
4 public static void main(String[] args) throws Exception {
5 byte[] bytes = serialize();
6 System.out.println(Arrays.toString(bytes));
7
8 TeacherSerializer.Teacher teacher = deserialize(bytes);
9 System.out.println(teacher);
10 }
11
12 // 序列化
13 private static byte[] serialize(){
14 // 构造器,构造Teacher
15 TeacherSerializer.Teacher.Builder builder = TeacherSerializer.Teacher.newBuilder();
16 builder.setName("Tim")
17 .setAge(34)
18 .setTeacherId(1L)
19 .addCourses("Java");
20 TeacherSerializer.Teacher teacher = builder.build();
21 return teacher.toByteArray();
22 }
23
24 // 反序列化
25 private static TeacherSerializer.Teacher deserialize(byte[] bytes) throws Exception {
26 return TeacherSerializer.Teacher.parseFrom(bytes);
27 }
28}
同样属性的JavaBean对象,但是通过Protobuf序列化和反序列化的代价却小很多,和Java原生序列化的大小产生了鲜明对比:
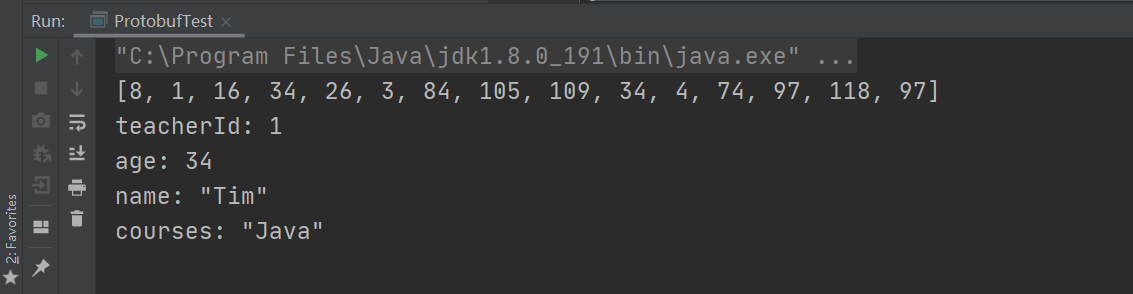
那么为什么Java序列化出的对象这么大呢?其实其中还包含了Class信息,就拿上面的Teacher对象来说,Java原生序列化方式实际上是包含了Teacher这个类的信息(导包、类型、方法等等)和数据本身相关的信息。但是Protobuf是如何保存的呢?其实Protobuf通过辅助类来保存了类信息,也就是我们在命令行里面生成的类,该类就已经存储了类相关信息。
Protobuf特性与基本原理
1、生成的序列化器(辅助类)中保存了需要序列化的对象的类信息
2、动态伸缩性,int(1-5字节),long(1-9字节) 例如: age = 34 只占了1个字节大小,只动态分配1个字节存储
下面先主要看看Protobuf是如何实现动态伸缩性的,我们以无符号int类型举个例子:
1public void writeVarint32(int value) throws IOException{
2 while(true){
3 if((value & ~0x7F) == 0){
4 writeRawByte(value);
5 return;
6 }else{
7 writeRawByte(value & 0x7F | 0x80);
8 value >>>= 7;
9 }
10 }
11}
那么这段代码的意义何在呢?这就是Protobuf动态伸缩性的精髓所在了:

Protobuf原理深入剖析
下面会介绍ProtoBuf是如何尽可能的压榨编码性能和效率的, Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数,这能减少用来表示数字的字节数,这也就是我在上面分析动态伸缩无符号int类型的示例。不妨先看看ProtoBuf的编码结构:
Protobuf编码结构采用了Tag - Length - Value格式。Tag 作为该字段的唯一标识,Length 代表 Value 数据域的长度,最后的Value便是数据本身ProtoBuf 编码采用类似的结构,但是实际上又有较大区别,其编码结构可见下图:
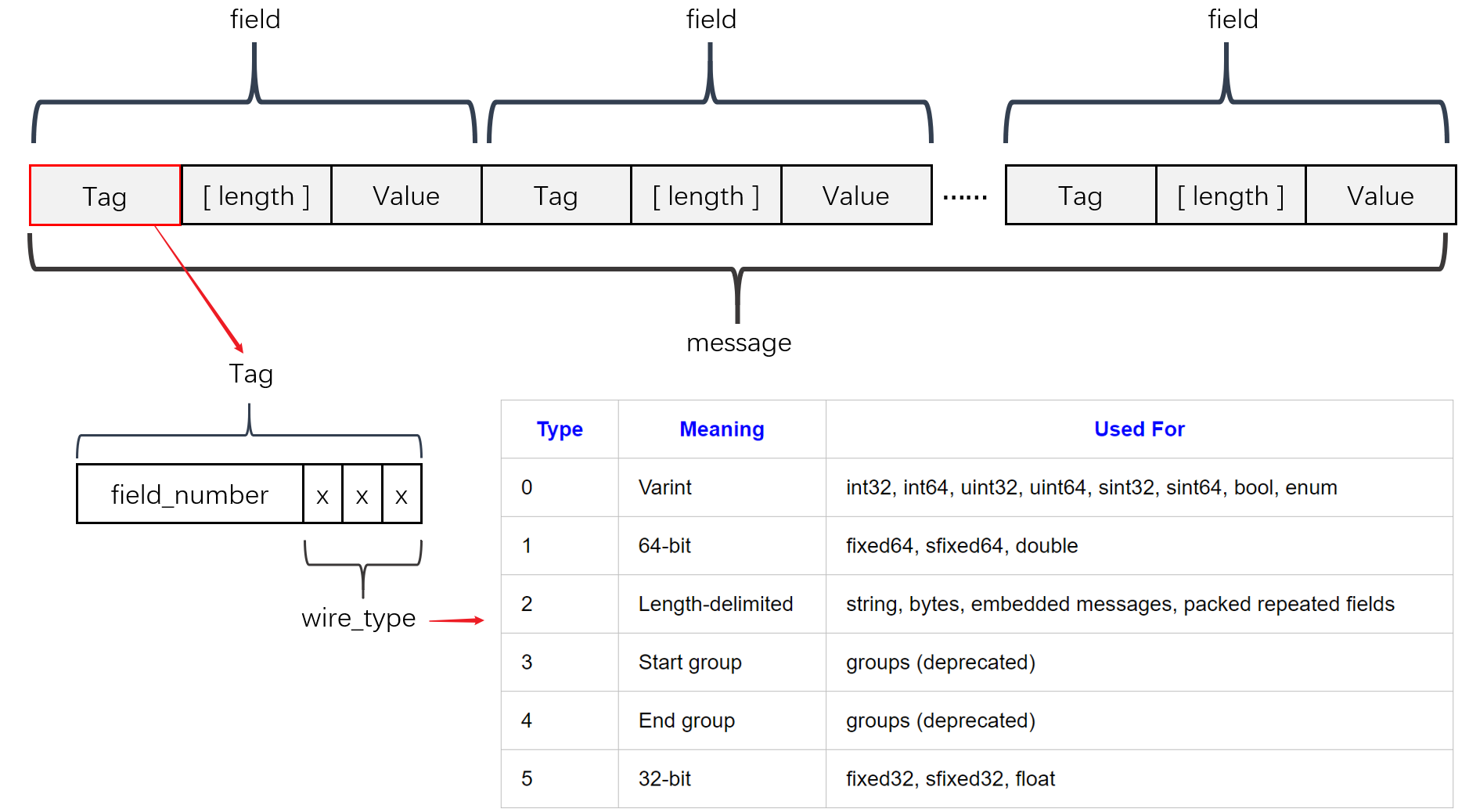
在上图中的Tag的wire_type字段中, Start group 和 End group 两种类型已被遗弃。这些类型在各大编程语言中的对应关系可以在官网查得:
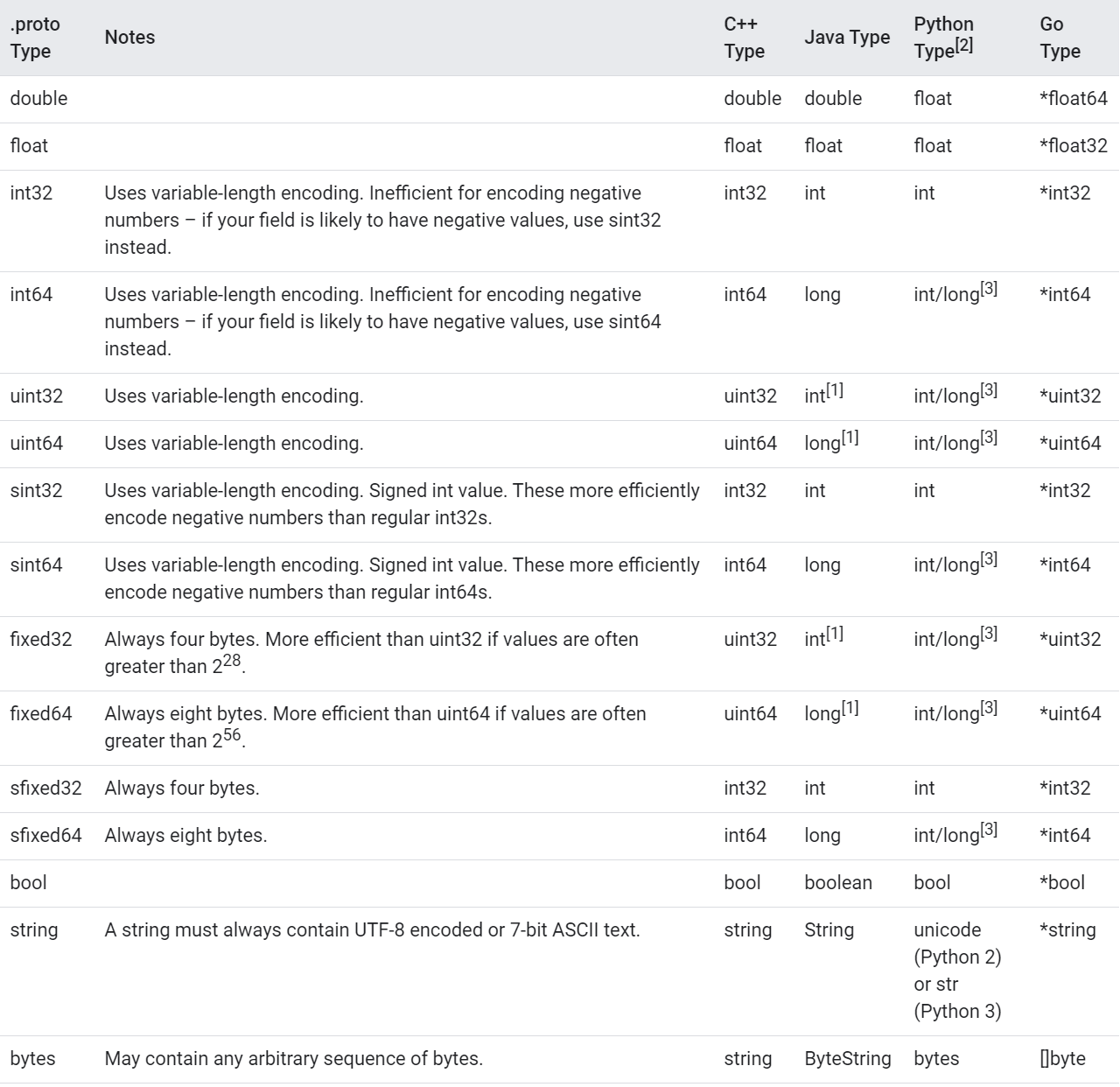
对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用Varint后,可以用更少的字节数来表示数字信息。Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010。
在Type为0所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 byte。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,关于zigzag的详细内容可以参考 《小而巧的数字压缩算法:zigzag》 。
Protobuf的优缺点
Protobuf 的优点
Protobuf 有如 XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。只需对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
它有一个非常棒的特性,即“向后”兼容性好,人们不必破坏已部署的、依靠“老”数据格式的程序就可以对数据结构进行升级。这样您的程序就可以不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。因为添加新的消息中的 field 并不会引起已经发布的程序的任何改变。
Protobuf 语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据访问类以对 Protobuf 数据进行序列化、反序列化操作)。
使用 Protobuf 无需学习复杂的文档对象模型,Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言,Protobuf 比其他的技术更加有吸引力。
Protobuf 的不足
Protobuf 与 XML 相比也有不足之处。它功能简单,无法用来表示复杂的概念。
XML 已经成为多种行业标准的编写工具,Protobuf 只是 Google 公司内部使用的工具,在通用性上还差很多。
由于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容。
参考资料:https://www.cnblogs.com/onlysun/p/4569595.html