服务拆分方法论
微服务是当下非常热门的话题,微服务发展到现在,已经不再单单局限于微服务架构本身,还与容器化、DevOps等新的理念相结合,成为当前移动互联网时代最先进的业务架构解决方案,能更好地迎合移动互联网业务快速迭代的要求。 本篇文章中我主要探讨的是什么时候适合微服务改造,如何做服务拆分等问题。
微服务适用场景
这些年关于服务拆分的理论层出不穷,在我看来我们首先需要搞明白起点和终点,然后还需要考虑的因素与坚持的原则。什么是起点和终点呢?第一种由于历史原因,公司的产品不得不从传统应用架构转为微服务架构,第二种原因呢就是马上开发一个全新的系统,需要用上微服务架构(当然不排除是BOSS装B,要追求新技术,因为微服务比较潮流嘛)。我们自己无论如何还是需要审视一下起点,也就是现有的架构是个什么样子,要考虑是否真的需要转成为微服务架构。至于终点呢,以一言蔽之:好的架构不是设计出来的,而是进化出来的,而且是一直在演进,生命不息,进化不止。吾生也有涯,而知也无涯。
我们可以看看Dubbo架构路线图:从单一应用架构 -> 垂直应用架构 -> 分布式服务架构 -> 流动计算架构
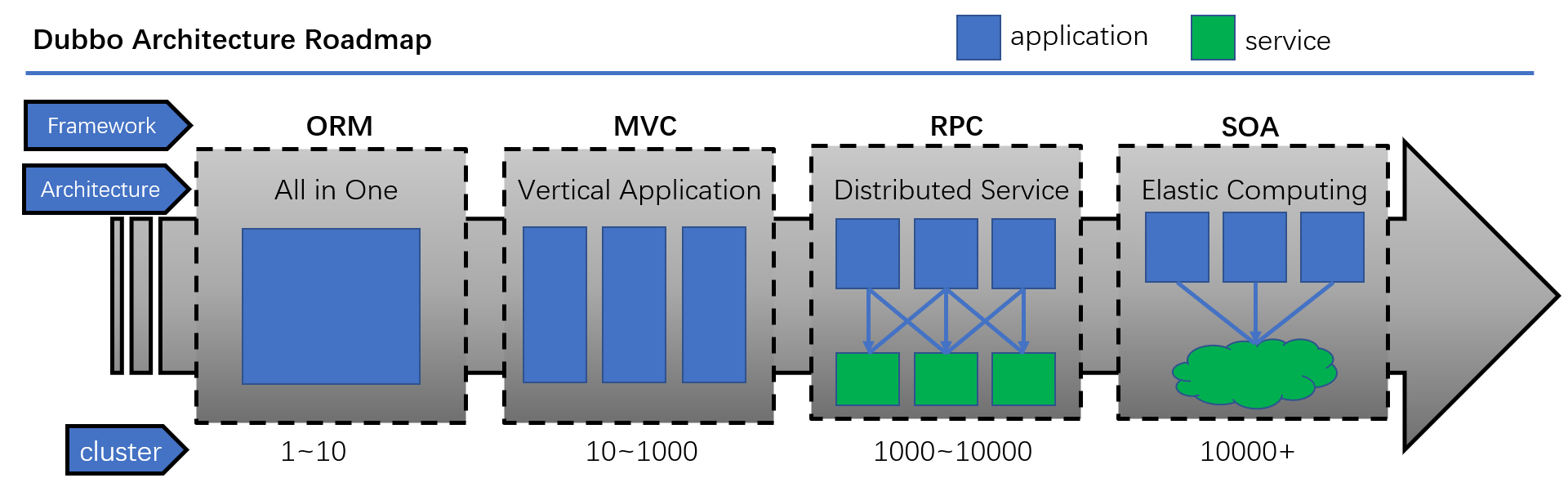
微服务与SOA之间就只是差了个ESB企业服务总线,如果此时的已经是SOA的架构,那么此时需要关心的也就是ESB了。从单体应用迁移到微服务架构的过程中,需要关注的重点是不一样的。微服务系统很可能是异构的,那么当前Java在整个系统中的占比是多少呢,有没有已经包含了服务注册与发现相关的组件呢,负载均衡的组件是弃用还是保留,如何以最小的代价切换过去。不过我们最需要优先考虑的就是,这个系统是否真的那么适合用微服务架构呢?在我看来,下列业务形态是不适合使用微服务架构的:
1、系统中包含很多很多强事务场景的不适合使用微服务架构。因为微服务是分布式的,如果是强事务场景,是不适合用微服务架构的。 2、业务相对稳定,迭代周期长。比如系统本来就是一个非常稳定的系统,几乎也没什么变更迭代,几个月代码都不会更新一次,如果一定要切换到微服务的话代价还是比较大的。 3、访问压力不高,可用性要求不高。比如中小型企业的内部OA系统,没啥访问量,偶尔出问题挂了个把小时其实也所谓,这样的项目如果用微服务架构岂不是杀鸡用牛刀。
所以微服务也不是放之四海而皆准的。
服务拆分方法论
我们可以先看看什么是扩展立方模型 (Scale Cube),Scale Cube是用于定义微服务和扩展技术产品的模型。AKF Partners于2007年发明了Scale Cube,最初于2017年在博客上发布 《SPLITTING APPLICATIONS OR SERVICES FOR SCALE》 ,在《可扩展的艺术》一书中也出现过扩展立方模型:
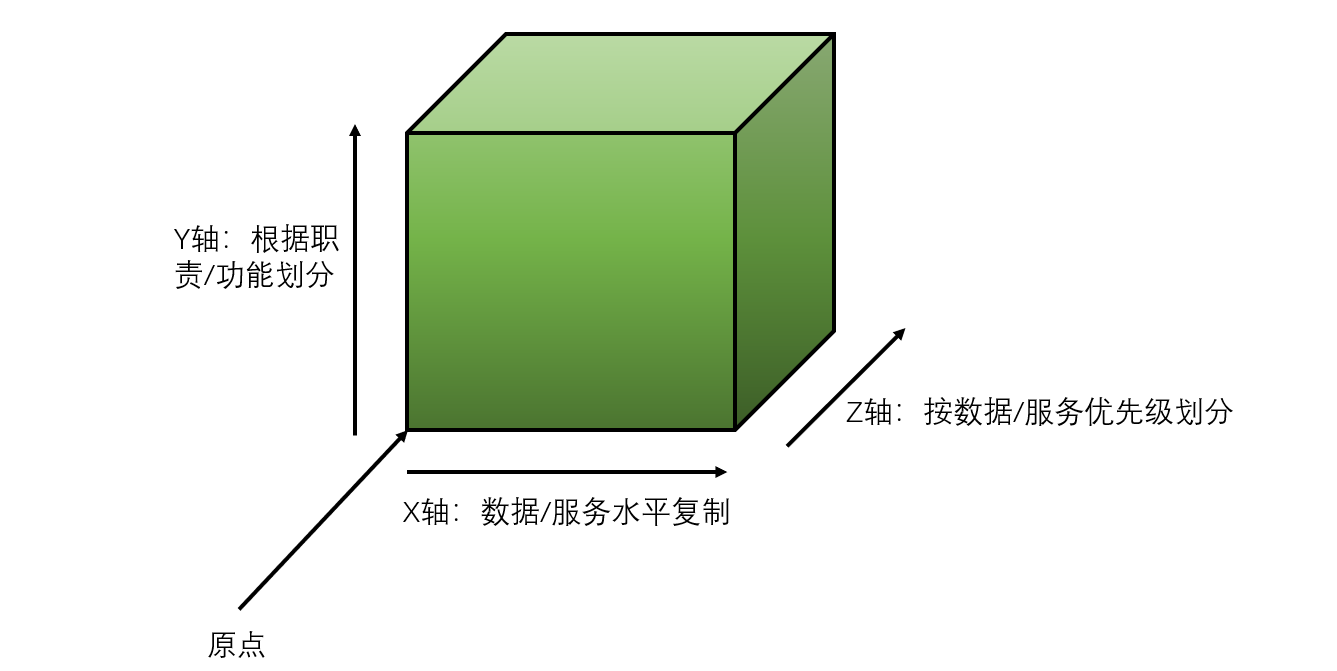
立方体有三个轴线,每个轴线描述扩展性的一个维度! X轴:代表无差别的克隆服务和数据,通过负载均衡工作可以很均匀的分散在不同的服务实例上; Y轴:关注应用中职责的划分,比如数据类型,交易执行类型的划分; Z轴:关注服务和数据的优先级划分,如分地域划分。
通过这三个维度上的扩展,可以快速提高产品的扩展能力,适应不同场景下产品的快速增长。不同维度上的扩展,有着不同的优缺点:
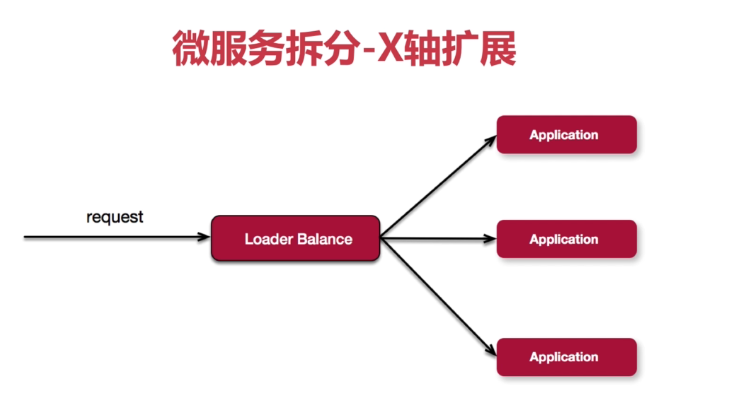
1、X轴扩展
- 优点:成本最低,实施简单;
- 缺点:受指令集多少和数据集大小的约束。当单个产品或应用过大时,服务响应变慢,无法通过X轴的水平扩展提高速度;
- 场景:发展初期,业务复杂度低,需要增加系统容量。
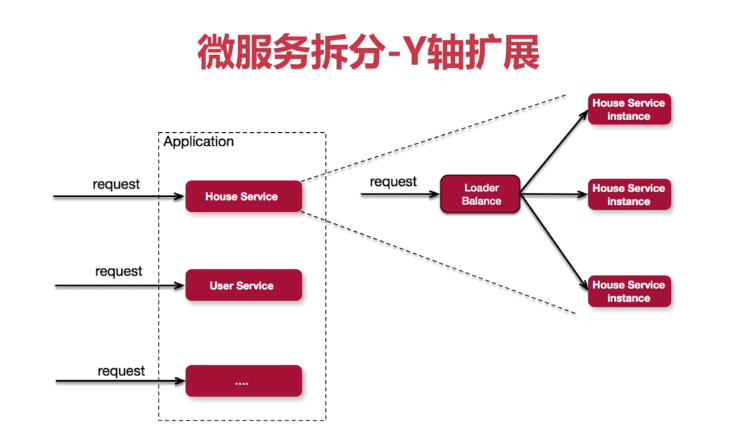
2、Y轴扩展
- 优点:可以解决指令集和数据集的约束,解决代码复杂度问题,可以实现隔离故障,可以提高响应时间,可以使团队聚焦更利于团队成长;
- 缺点:成本相对较高;
- 场景:业务复杂,数据量大,代码耦合度高,团队规模大。
3、Z轴扩展
- 优点:能解决数据集的约束,降低故障风险,实现渐进交付,可以带来最大的扩展性。
- 缺点:成本最昂贵,且不一定能解决指令集的问题;
- 场景:用户指数级快速增长。
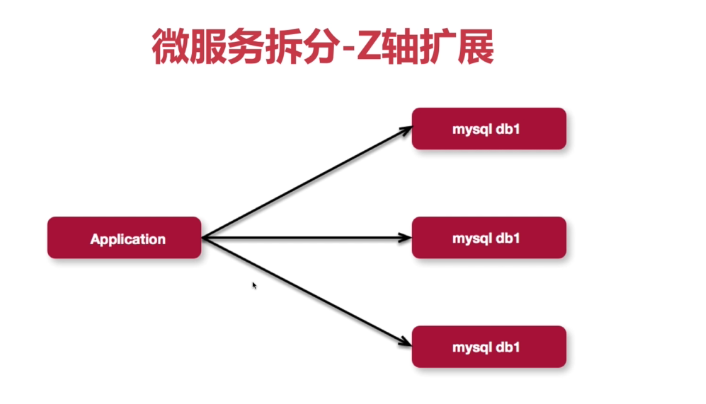
三个维度拆分后,微服务的架构图就如下图所示:
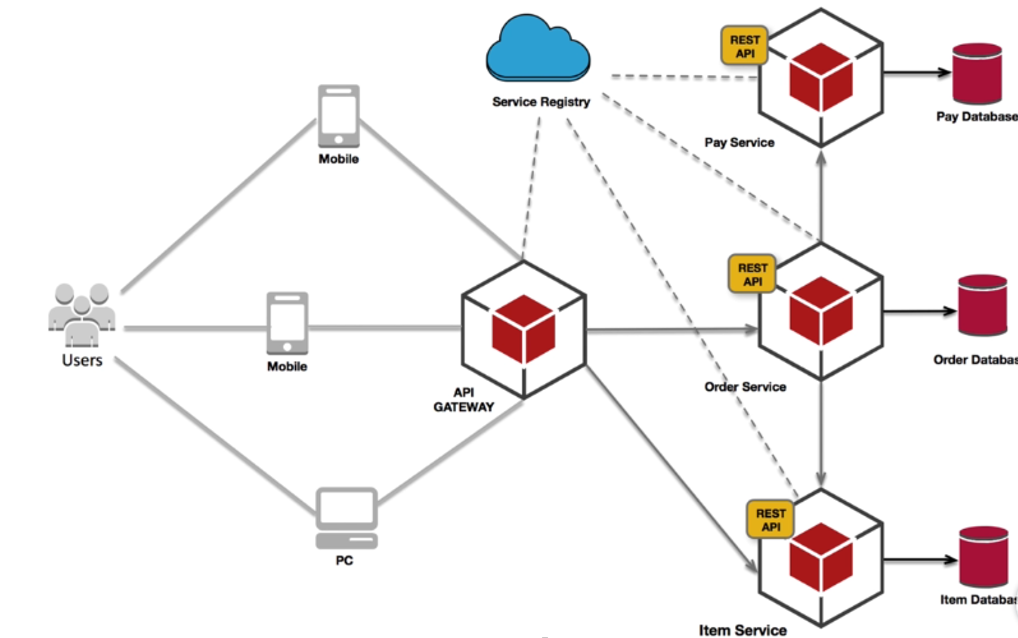
功能拆分的角度
1、单一职责、松耦合、高内聚
2、关注点分离
- 按职责分离
- 按通用性分离
- 按粒度级别
将理论付诸实践
1、为扩展分割应用
- X轴:从单体系统或服务,水平克隆出许多系统,通过负载均衡平均分配请求;
- Y轴 :面向服务分割,基于功能或者服务分割,例如电商网站可以将登陆、搜索、下单等服务进行Y轴的拆分,每一组服务再进行X轴的扩展;
- Z轴 :面向查找分割,基于用户、请求或者数据分割,例如可以将不同产品的SKU分到不同的搜索服务,可以将用户哈希到不同的服务等。
2、为扩展分割数据库
- X轴:从单库,水平克隆为多个库上读,一个库写,通过数据库的自我复制实现,要允许一定的读写时延;
- Y轴 :根据不同的信息类型,分割为不同的数据库,即分库,例如产品库,用户库等;
- Z轴 :按照一定算法,进行分片,例如将搜索按照MapReduce的原理进行分片,把SKU的数据按照不同的哈希值进行分片存储,每个分片再进行X轴冗余。
3、为扩展而缓存 在理想情况下,处理大流量最好的方法是通过高速缓存来避免处理它。从架构层面看,我们能控制的主要有以下三个层次的缓存: ① 对象缓存:对象缓存用来存储应用的对象以供重复使用,一般在系统内部,通过使用应用缓存可以帮助数据库和应用层卸载负载。
② 应用缓存:应用缓存包括代理缓存和反向代理缓存,一个在用户端,一个在服务端,目标是提高性能或减少资源的使用量。
③ 内容交付网络缓存:CDN的总原则是将内容推送到尽可能接近用户终端的地方,通过不同地区使用不同ISP的网关缓存,达到更快的响应时间和对源服务的更少请求。
4、为扩展而异步 同步改异步:同步调用,由于调用间的同步依赖关系,有可能会导致雪崩效应,出现一系列的连锁故障,进而导致整个系统出现问题,所以在进行系统设计时,要尽可能的考虑异步调用方式,邮件系统就是一个非常好的异步调用例子。
应用无状态:当进行AKF扩展立方体的任何一个轴上的扩展时,都要首先解决应用的状态问题,即会话的管理,可以通过避免、集中和分散的方式进行解决。
AKF扩展立方体是一套通用的扩展性理论,它不仅可以应用到系统的架构扩展上,也可以应用到人员的组织架构扩展上甚至其他相关的工业领域。当然并不是所有公司都需要同时在XYZ三个方向上进行扩展,并且每个方向上的扩展都有它的利弊,我们不可避免的要进行适当的权衡。