分析事务隔离的实现
关于MySQL的锁机制问题,在之前的博客中有谈到 《探究MySQL锁机制》 ,里面对锁的讲解比较详细,现在是在原来的基础上谈谈数据库事务相关的问题。简单来说事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在MySQL中,事务支持是在引擎层实现的。你现在知道,MySQL是一个支持多引擎的系统,但并不是所有的引|擎都支持事务。比如MySQL原生的MyISAM引擎就不支持事务,这也是MyISAM被InnoDB取代的重要原因之一。首先要知道的是数据库事务四大特性:ACID
事务四大特性ACID
- 原子性 Atomic:事务是一个原子操作单元, 其对数据的修改,要么全都执行,要么全都不执行。
- 一致性 Consistency:在事务开始和完成时, 数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性 Isolation:数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性 Durability:事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务处理的问题
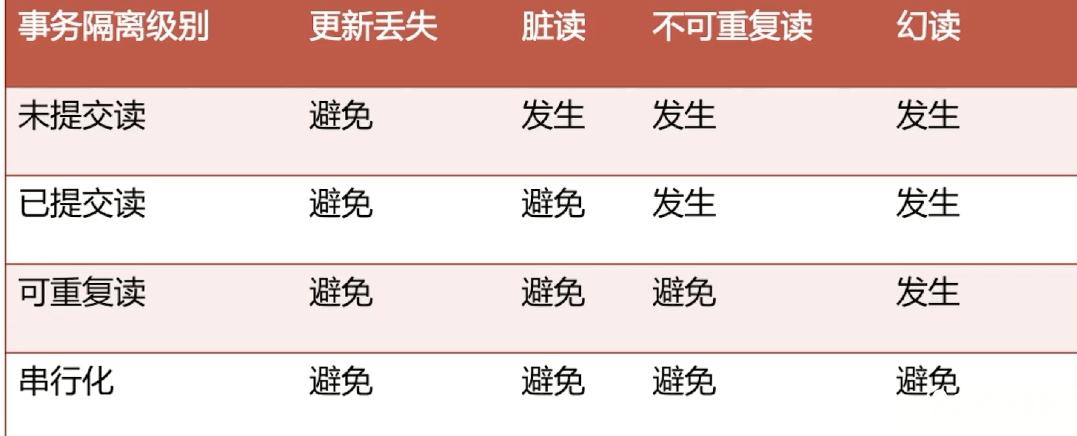
1、更新丢失
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题,这就是最后的更新覆盖了由其他事务所做的更新。
例如,两个程序员修改同一个Java文件。每程序员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖前一个程序员所做的更改。如果在一个程序员完成并提交事务之前,另一个程序员不能访问同一文件,则可避免此问题。
2、脏读
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态,这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些 “脏” 数据,并据此做进一步的处理, 就会产生未提交的数据依赖关系。这种现象被形象地叫做”脏读”。
一句话:事务A读取到了事务B已修改但尚未提交的的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。
3、不可重复读
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。 一句话:事务A读取到了事务B已经提交的修改数据,不符合隔离性
4、幻读
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
一句话:事务A读取到了事务B体提交的新增数据,不符合隔离性
注意:幻读和脏读有点类似,脏读是事务B里面修改了数据,幻读是事务B里面新增了数据。
四种事务隔离级别
-
读未提交:一个事务还没提交时,它做的变更就能被别的事务看到。
-
读提交:一个事务提交之后,它做的变更才会被其他事务看到。
-
可重复读: 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。 当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
-
串行化:顾名思义是对于同一行记录,“写” 会加
写锁,“读” 会加读锁。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
这4种隔离级别,并行性能依次降低,安全性依次提高
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在可重复读隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。
在读提交隔离级别下,这个视图是在每个SQL语句开始执行的时候创建的。这里需要注意的是,读未提交隔离级别下直接返回记录上的最新值,没有视图概念;而串行化隔离级别下直接用加锁的方式来避免并行访问。
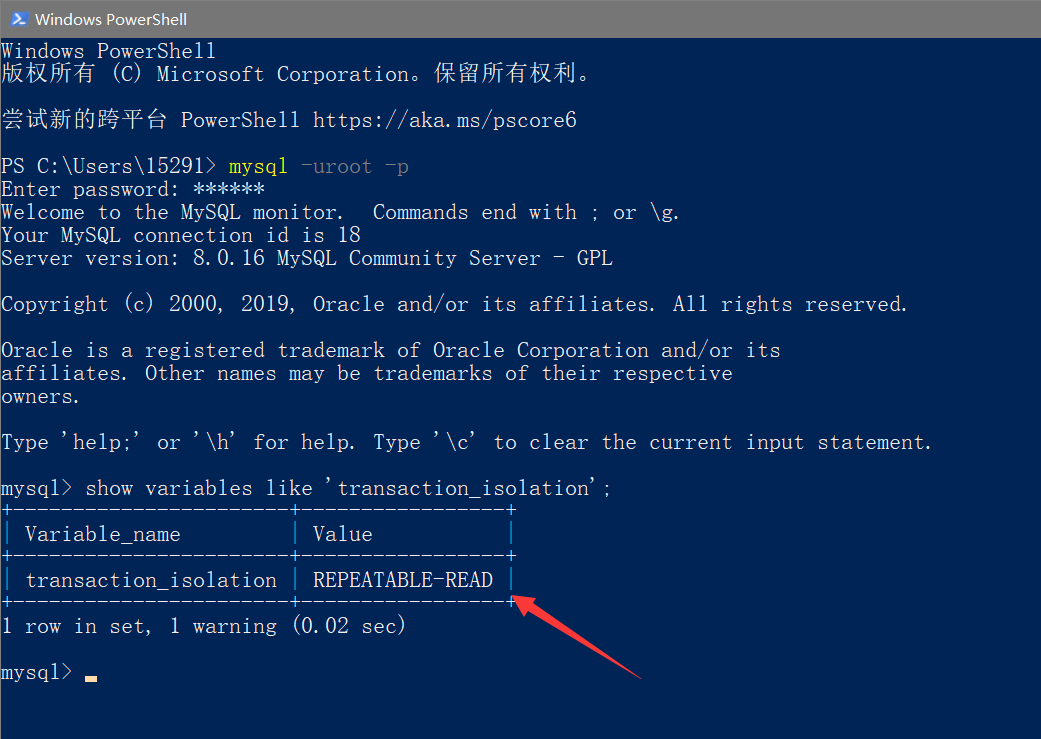
在不同的隔离级别下,数据库行为是有所不同的。Oracle 数据库的默认隔离级别其实就是读提交,因此对于一些从Oracle迁移到MySQL的应用为保证数据库隔离级别的一致,一定要记得将MySQL的隔离级别设置为读提交
配置的方式是,将启动参数 transaction-isolation 的值设置成 READ-COMMITTED。你可以用 show variables 来查看当前的值:
事务隔离的实现原理
接下来我们看看事务隔离的实现原理,在这里我们可以简单说一下可重复读
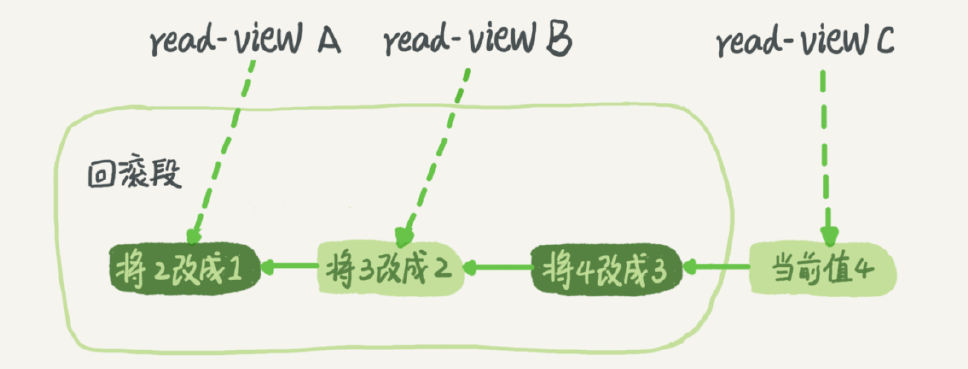
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值,假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录:
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的,回滚日志总不能一直保留吧,什么时候删除呢?
答案是,在不需要的时候才删除。也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除,什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的 read-view 的时候。
通过上面的例子我们发现,尽量不要使用长事务,这是一条必须遵守的法则
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导占用大量的存储空间!
这4种隔离级别,并行性能依次降低,安全性依次提高 总结如下表: