密集索引和稀疏索引
密集索引:文件中的每个搜索码值都对应一个索引值,就是叶子节点保存了整行,比如InnoDB
稀疏索引:文件只为索引码的某些值建立索引项,比如MyISAM
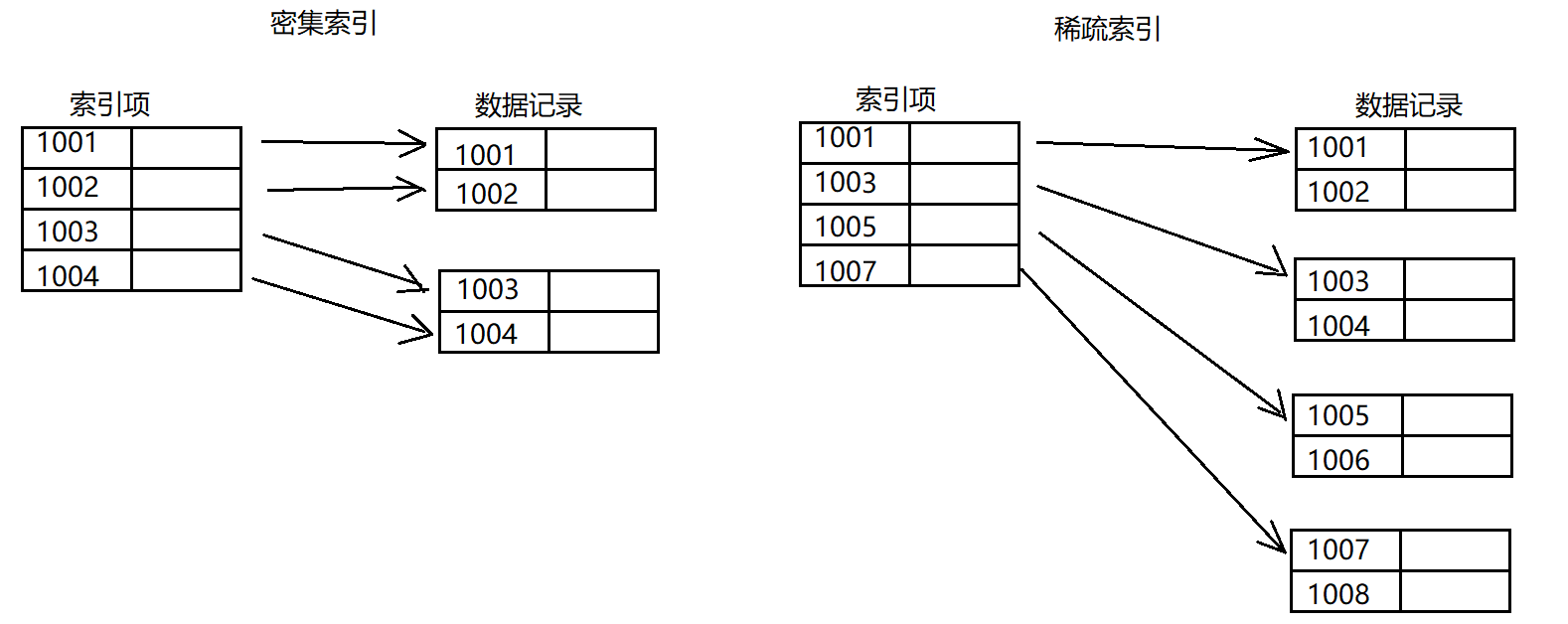
密集索引的表数据按顺序存储,即索引顺序和表记录物理存储顺序一致,所以一个表只能创建一个密集索引
InnoDB的密集索引的选取规则是怎么样的呢?
1、若一个主键被定义,该主键则作为密集索引 2、若没有主键被定义,该表的第一个唯一非空索引则作为密集索引 3、若不满足以上条件,InnoDB内部会生成一个隐藏主键(密集索引) 4、非主键索引存储相关键位和其对应的主键值,包含两次查找
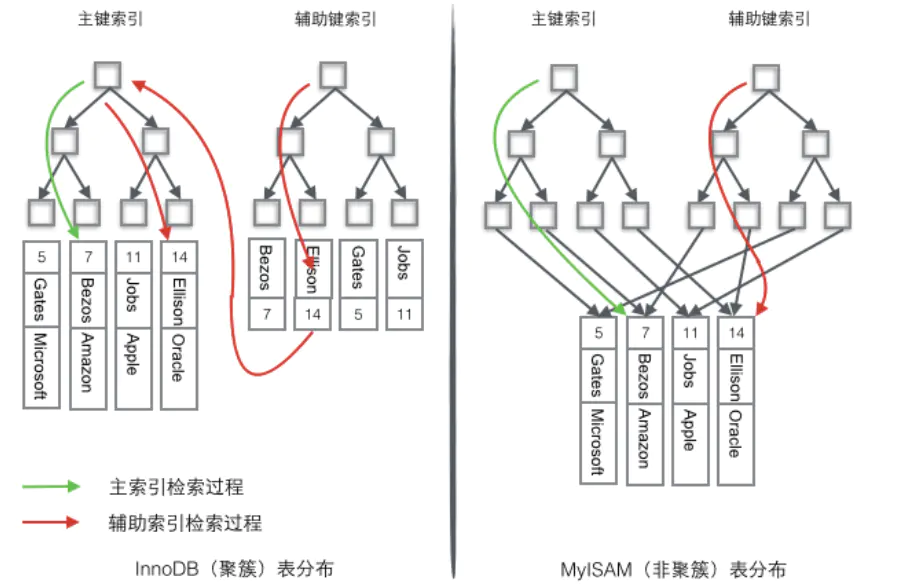
如上图示意:InooDB的主键索引和数据是保存在同一个文件中的,所以在检索的时候,在加载叶子节点的主键进入内存的同时也加载了对应的数据,如果是使用主键查询,只需要根据B+Tree的规则找到主键,就可以获得对应的行数据,如果稀疏索引进行数据筛选就会经历两个步骤,第一个步骤是在稀疏索引B+Tree中检索该键,比如检索Ellison,就会获取到主键信息,获取到主键信息之后,需要经历第二个步骤:在主键的B+Tree中进行查找。
对于MyISAM,使用的均为稀疏索引,稀疏索引的两个B+Tree其实也没有什么不同,结构完全一致,只是存储的内容不一样而已,主键索引的B+Tree存储了主键,辅助键索的B+Tree引存储了辅助键,数据却存储在了独立的地方,也就是索引和数据是分开存储的,这两个B+Tree的叶子节点都存储了指向数据的地址,由于辅助键索是独立的,无需借助主键。
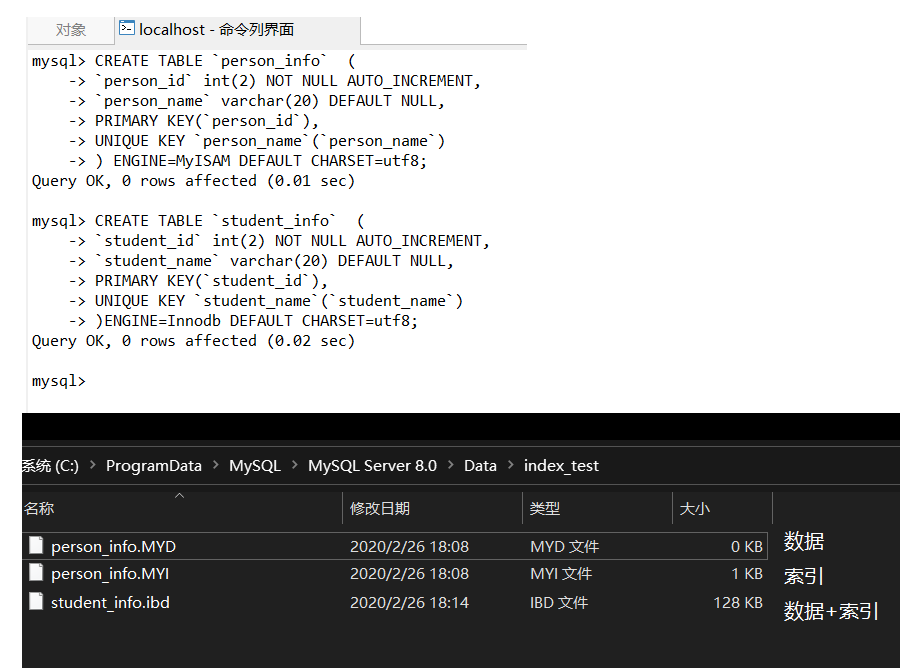
下面我们可以建表验证一下,建表语句如下和效果如下:
上面我们已经弄出清楚了密集索引和稀疏索引的区别,现在来思考一个问题:索引是越多越好吗?
答案是当然是否定的,数据量小的表不需要建立索引,建立会增加额外的索引开销;数据变更需要维护索引,因此更多的索引意味着更多的维护成本,更多的索引意味着也需要更多的空间!