Python语法学习日志
编译器与解释器
将其他语言翻译为机器语言的工具被称为编译器
编译器翻译的方式有两种,一个是编译、另一个是解释。两中方式的区别在于翻译时间的不同,当编译器以解释方式运行的时候,也称之为解释器
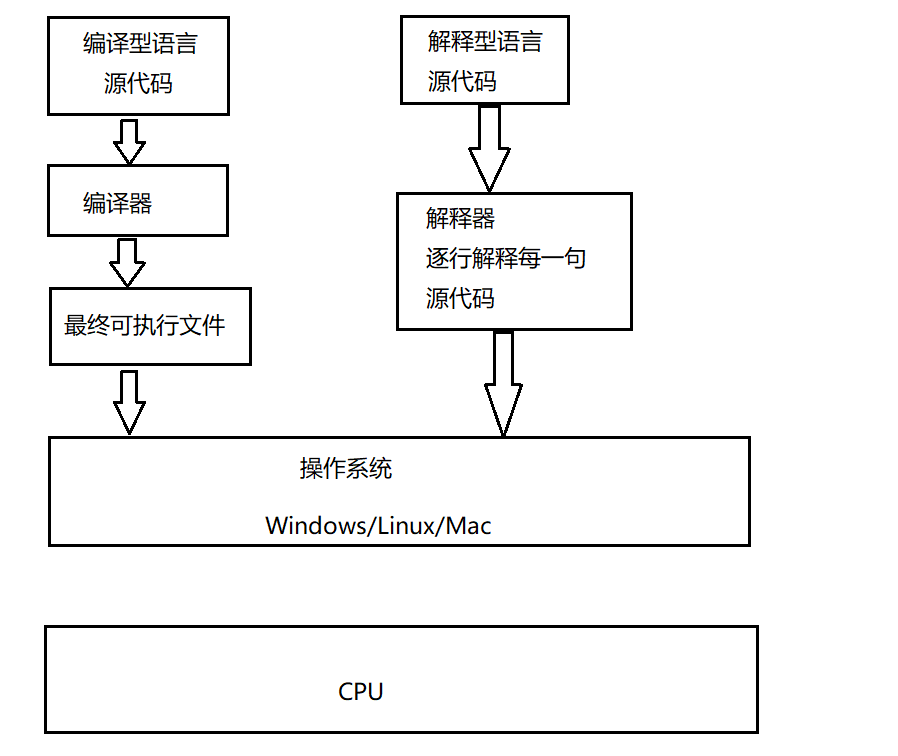
编译型与解释型速度
跨平台:每个操作系统都有对应的解释器,解释型跨平台性很好 速度:解释型速度相对来说较慢
python的设计哲学:最好只有一个方法来做一件事请,越简单越明确越好
Python的特点
- Python是完全面对对象的语言 函数、模块、数字、字符串都是对象,在Python中一切都是对象、完全支持继承、重载、多重继承、支持重载运算符,也支持泛型设计
- Python拥有强大的标准库 Python语言的核心只包括数字、字符串、列表、字典、文件等常见类型和函数,而由Python标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML处理等额外的功能
- Python社区提供了大量的第三方模块,使用方法与标准库类似。它们的功能覆盖科学计算、人工智能、机器学习、Web开发、数据库接口、图形系统多个领域
- Python是个格式非常严格的语言,每行代码完成一个动作、注意缩进错误、
Python解析器对应名称
Python2.X默认不支持中文,主要原因是编码不支持 Python2.X的解释器名称是Python Python3.X的解释器名称是Python3
Python3是主流版本,Python3.0并没有向下兼容,但是语法层面相差并不是很大
执行Python程序的三种方法
- 解释器:python + 文件名
- 交互式:python的shell,exit()函数用来退出shell,Ctrl+d也可以退出(Windows下为Ctrl+Z)
- IPython:是python的一个交互式shell
Python的注释
# 单行注释
"""
这个是多行注释、也叫做块注释
"""
Python的运算符
| 运算符 | 作用 |
|---|---|
/ |
获得高精度结果 |
// |
或者整数除数 |
% |
获取余数 |
** |
幂,二次方 |
* |
此运算符还可以得到指定个数的字符串 |
Python程序的执行原理
(1)CPU会先把Python解释器程序复制到内存中
(2)Python解释器会根据语法规则,从上到下让CPU翻译Python代码
(3)负责执行翻译完成的代码

Python解释器到底有多大? Linux的python2.7版本的解释器只有3.4M
注意:Python变量的定义不需要定义类型,解释器会自动推导数据类型 type函数:查看变量的数据类型 在Python2.x中: type (2 ** 32) int类型 type ( 2 ** 64) long类型 在Python3.x中 type (2 ** 32) int类型 type ( 2 ** 64) int类型 Python3已经将原来的long也认为是int
Python非常适合做数学计算,并且自动处理大数字,例如计算2的10000次方都可以轻松计算出来!
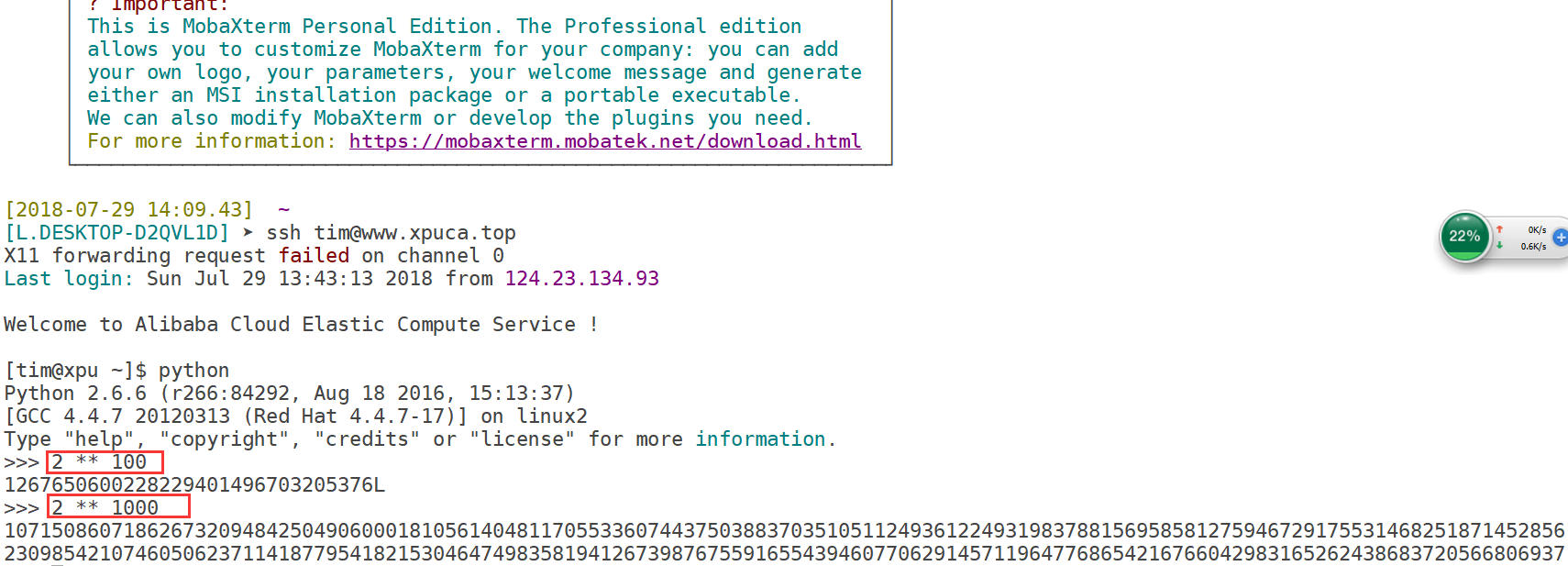
不同变量之间的计算
(1)数字之间可以直接计算,包括double与int等不同类型的数据,只要是数字就可以运算 (2) 如果变量是bool类型,True对应的数字为1,False对应的数字为0 (3)+ 运算符可以拼接字符串 (4)字符串变量可以和数字用*连接 (5)数字型变量和字符型变量之间不能进行其他的计算
Python的输入函数
pwd = input(“请输入密码\n”) 注意:input函数只能得到字符串
类型转换函数
int(x):将x转化为整数 float(x):将x转化为浮点数
print()函数的格式化输出
%s 字符串
%d 有符号十进制整数,%06d表示输出的整数显示位数,不足的地方用0补全
%f 浮点数,%0.2f表示小数点后只显示两位
%% 输出%
注意这与C的printf函数的符号使用区别,这个是直接使用
%链接的
查看python的关键字
import keyword
print(keyword.kwlist)
[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
import 关键字:导入工具包 python中变量名是区分大小写的
关于4空格与tab键
在开发python程序的时候Tab键和4个空格键不要混用,最好是直接用4个空格 if语句与下方的缩进是一个完整的代码块!
注意输入的只能是字符串,需要类型转换
age = int(input("请输入年龄:"))
print("年龄:%d" % age)
python中的逻辑运算符 and、or、not
pycharm使用技巧
Tab键可以统一向右缩进 Shift+Tab可以统一向左缩进
注意:if判断代码过长,可以加小括号换行,换行之后的条件必须加8个空格
##如何产生1-100的随机数? (第一个参数必须小于第二个参数)
import random
print(random.randint(0, 100))
python中的+=、-=、/=、*=、%=与C一样,//=是取整除、**=是幂赋值运算符
python需要注意的地方
- 在循环中如果使用continue这个关键字,需要确认循环的计数是否修改,否则可能导致死循环
- print()函数输出内容之后,会自动增加换行,print("***", end="")
- python的九九乘法表
i = 1
while i <= 9:
j = 1
while j <= i:
print("%d*%d=%d\t"% (i, j, i*j), end = "")
j += 1
i += 1
print()
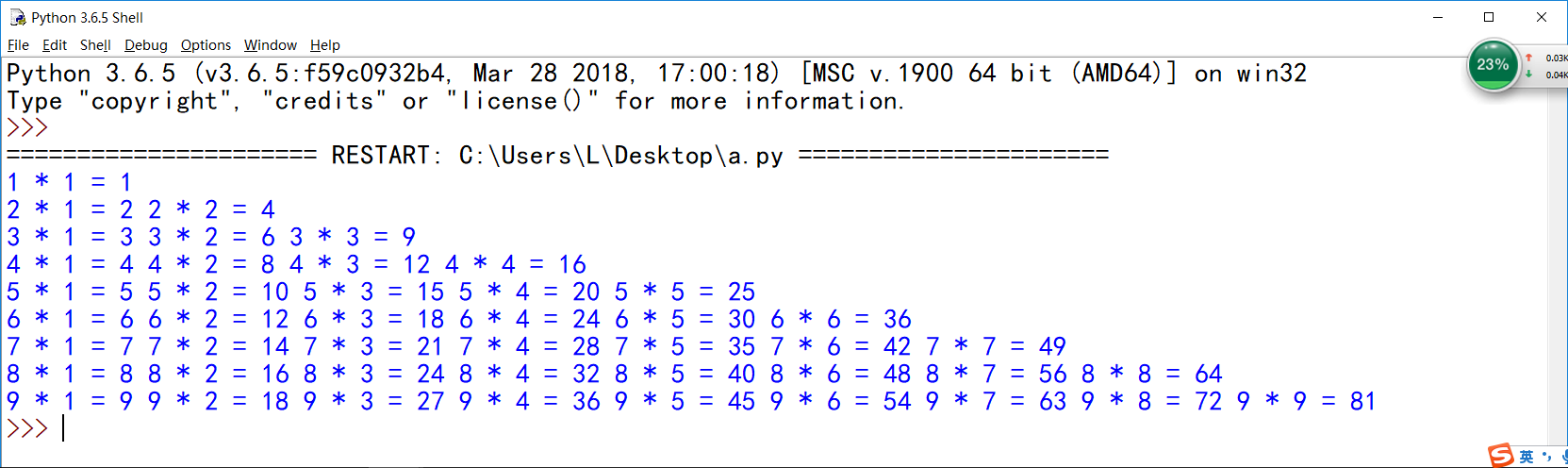
常见转义字符:
| 符号 | 原意 |
|---|---|
\\ |
反斜杠符号 |
\' |
单引号 |
\" |
双引号 |
\n |
换行 |
\t |
横向制表符 |
\r |
回车 |
函数封装
封装函数的格式:注意函数命名应该符合命名规则
def 函数名():
封装的代码
注意:不能在定义函数之前就使用函数,和C语言一致,或者先声明函数
pycharm调试工具
F8 Step Over 可以单步执行代码,会把函数调用看作是一行代码直接执行 F7 Step Into 可以单步执行代码,如果是函数,会进入函数内部
函数的注释方式:
def my_fun():
"""
打印乘法表
:return:无返回值
"""
i = 1
while i <= 9:
j = 1
while j <= i:
print("%d*%d=%d\t"% (i, j, i*j), end = "")
j += 1
print()
i += 1
my_fun()
def 函数名(参数1,参数2,参数3,...):
函数体
模块的概念
模块:以.py结尾的文件就是一个模块,本质就是工具包,里面有工具函数,要使用的时候用import导入即可 模块名也是标识符,必须符合命名规则,比如以数字开头的文件是无法导入的
Pyc文件,c是compiled,即是编译过的意思
python中的数据类型
- 数字型:整型、浮点型、布尔型、复数型(用于科学计算:比如平面场、波形问题)
- 非数字型:字符串、列表、元组、字典、
非数字型都有的特点: 1、都是一个序列(sequence),也可以理解为容器 2、取值[] 3、遍历for in 4、计算长度、最大值、最小值、比较、删除 5、连接 + 和重复 * 6、支持切片
列表:list
在其他的编程语言叫做数组
列表的方法
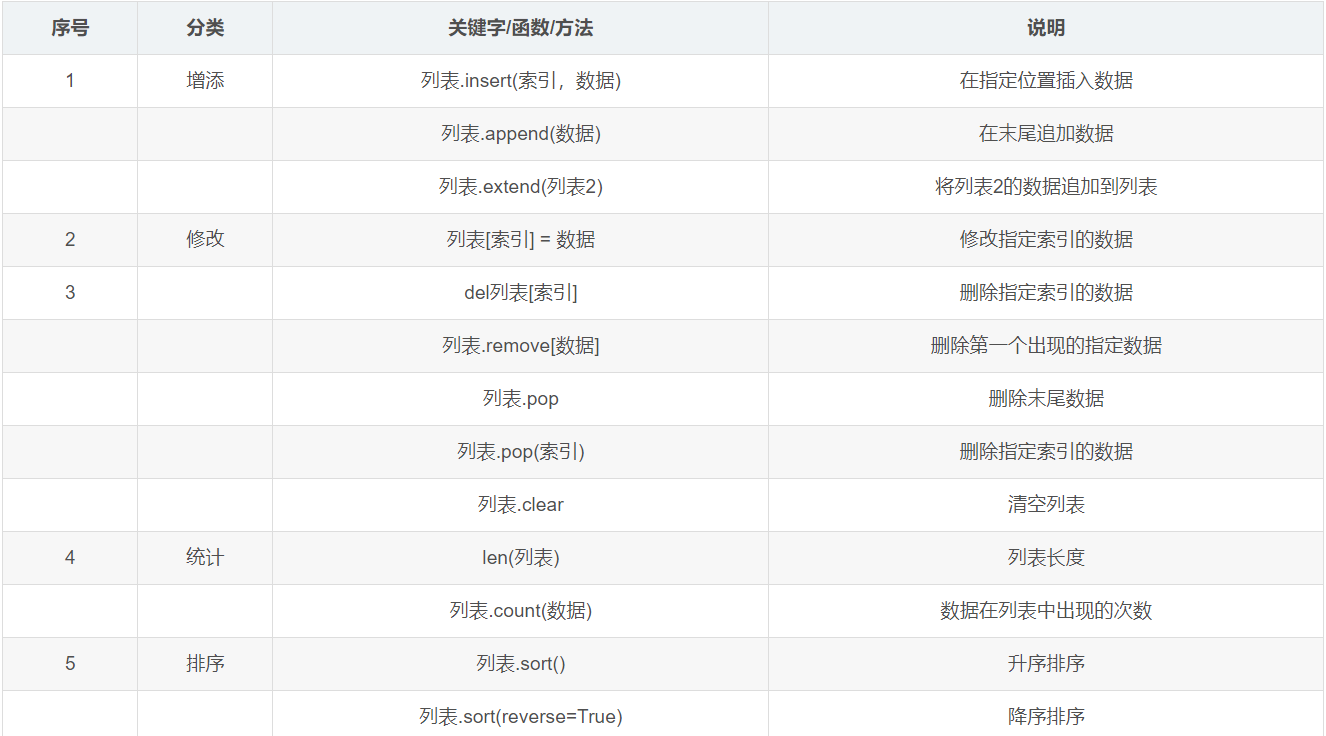
- 列表指定索引值越界,数组越界异常
- extend方法把arr2(其他列表)中的内容追加到arr1里面 arr.extend(arr2)
- 默认删除(弹出)最后一个元素 arr.pop(),pop方法返回被移除的元素
- remove方法可以删除指定内容的元素,但是只能删除第一个符合条件的数据,如果数据不存在就会报错
del关键字:使用delete关键字,简写为del del关键字本质上是用来将一个变量从内存中删除的 注意:如果使用del关键字讲一个变量从内存中删除,后续的代码就不能使用该变量了,在开发中最常用的是使用列表提供的方法去删除元素
元组 :tuple
元组与列表类似,不同之处在于元组的元素不能修改,列表使用 [ ] 定义,二元组使用 ( ) 定义
如果只想定义只有一个元素的元组: single_tuple = (4) # 这种做法是错误的,解释器会误以为是加了括号的int类型 single_tuple = (4,) # 这才是正确的另一方式,需要在后面加逗号
元组只有两个方法:
| 方法 | 作用 |
|---|---|
| 元组.count(数据) | 求该数据在元组中的个数 |
| 元组.index(索引) | 取出元组中的数据 |
元组中通常保存的数据是不同的,实际开发中,除非能确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多,元组的应用场景:
- 函数的参数和返回值,一个函数可以接受任意多个参数,或者一次返回多个数据
- 格式字符串,格式化字符串后面的()本质上就是一个元组
- 让列表不可以被修改,可以转换为元组
列表和元组之间的转换函数
list(元组)、tuple(列表)
字典 dictionary
- 字典是除了列表以外的最灵活的数据类型,字典同样可以用来存储多个数据,通常字典用于存储一个物体的相关信息
- 字典和列表的区别 列表是有序的对象集合、字典是无序的对象集合
- 字典用 { } 定义
- 字典使用键值对存储数据、键值对之间使用 “,”分割 key是索引、value是数据 键和值之间使用“:”分割 键必须是唯一的,值可以取任意数据类型,键只能用字符串、数字或者元组
字典的循环遍历:
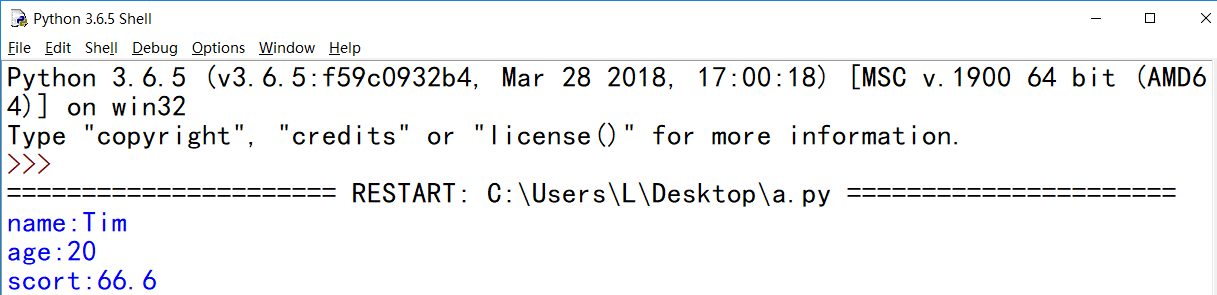
student = {"name": "Tim",
"age": 20,
"scort": 66.6}
for k in student:
print("%s:%s"% (k, student[k]))
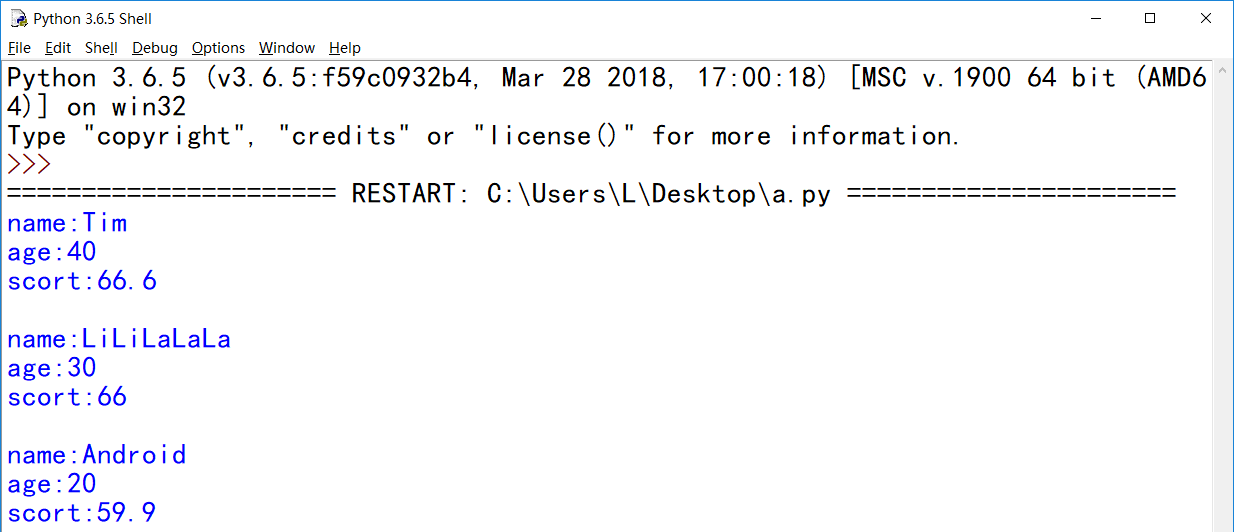
 字典和列表的混合使用
字典和列表的混合使用
students = [{"name": "Tim","age": 40,"scort": 66.6},
{"name": "LiLiLaLaLa","age": 30,"scort": 66},
{"name": "Android","age": 20,"scort": 59.9},
]
for student in students:
for k in student:
print("%s:%s"% (k, student[k]))
print()
字符串
定义字符串使用" "和 ''都是可以的,一般使用" "定义,和其他编程语言一致
注意:
1、虽然可以使用 \”或者 \' 做字符串的转移,但是在实际开发中:
- 如果字符串内部需要使用
",可以使用'定义字符串 - 如果字符串内部需要使用
',可以使用"定义字符串
2、可以使用索引获取一个字符串中指定位置字符,索引计数从0开始 3、也可以使用for循环遍历字符
| 方法 | 功能 |
|---|---|
| len(字符串) | 获取字符串的长度 |
| 字符串.count(字符串) | 小字符串在大字符串中出现的次数 |
| 字符串.index(字符串) | 获得小字符串第一次出现的索引 |
str3 = "hello hello"
print(len(str3)) # 10
print(str3.count("hello")) # 2
print(str3.count("abc")) # 0 查找子串出现次数,传入不存在的子串得到结果为0
print(str3.index("lo")) # 3
print(str3.index("abc")) # 出错,查找子串位置是若传入不存在的子串就会出错
字符串的常见操作
判断类型
| 方法 | 功能 |
|---|---|
| string.isspace() | 如果string中只包含空格则返回True |
| string.isalnum() | 如果string中至少有一个字符并且所有字符都是字母或数字则返回true |
| string.isalpha() | 如果string中至少有一个字符并且所有字符都是字母则返回true |
| string.isdecimal() | 如果string中只包含数字,则返回True,全角数字 |
| string.isdigit() | 如果string中只包含数字,则返回True,全角数字、(1)、\uoob2 |
| string.isnumeric() | 如果string中只包含数字,则返回True,全角数字、汉字数字 |
| string.istitle() | 如果string是标题化的(每个单词首字母大写)则返回True |
| string.islower() | 如果string包含一个区分大小写的字符,并且这些(区分大小写的)字符都是小写,则返回True |
| string.isupper() | 如果string包含一个区分大小写的字符,并且这些(区分大小写的)字符都是大写,则返回True |
查找和替换
| 方法 | 功能 |
|---|---|
| string.startwith(str) | 如果string以str开头则返回True |
| string.endwith() | 如果string以str结尾则返回true |
| string.find(str,start = 0,end = len(string)) | 检测str是否包含在string中,如果start和end指定范围,则只是检查是否在范围内部,若是则返回索引值,不是返回-1 |
| string.rfind(str,start = 0,end = len(string)) | 与find函数类似,只不过是从右边开始查找 |
| string.index(str,start = 0,end = len(string)) | 与find函数类似,只不过str不在string中会报错 |
| string.rindex(str,start = 0,end = len(string)) | 与find函数类似,只不过是从右边开始 |
| string.replace(old_str,new_str,num = string.count(old_str)) | 将string中的old_str替换成new_str,如果num指定,则替换不能超过num次 |
大小写转换
| 方法 | 功能 |
|---|---|
| string.capitalize(str) | 把字符串的第一个字母大写 |
| string.title() | 把字符串的每个单词首字母大写 |
| string.lower() | 转换string中的所有大写字母为小写 |
| string.upper() | 转换string中的所有小写字母为大写 |
| string.swapcase() | 反转string中的大小写 |
文本对齐
| 方法 | 功能 |
|---|---|
| string.ljust(width) | 返回原字符串右对齐,并使用空格填充至长度width的新字符串 |
| string.ritle() | 返回原字符串左对齐,并使用空格填充至长度width的新字符串 |
| string.center() | 返回原字符串居中对齐,并使用空格填充至长度width的新字符串 |
去除空白字符
| 方法 | 功能 |
|---|---|
| string.lstrip() | 截掉string左边的空白字符 |
| string.rstrip() | 截掉string右边的空白字符 |
| string.center() | 截掉string左右两边的空白字符 |
拆分和链接
| 方法 | 功能 |
|---|---|
| string.partition(str) | 把string分成一个3元素的元组(str前面,str, str后面) |
| string.rpartition(str) | 类似于partition函数,只不过是从右边查找 |
| string.split(str="",num) | 以str为分隔符切片string,如果num有指定值,则仅分割num+1个字符串,str默认包含'\r','\t','\n’和空格 |
| string.splitlines() | 按照行('\r','\n','\r\n')分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串 |
字符串中的转义字符
'\t' 在控制台中输出一个制表符,协助在输出文本时垂直方向保持对其
'\n' 在控制台输出一个换行符
**制表符的功能是在不使用表格的情况下在垂直方向按列对齐文本
| 转义字符 | 描述 |
|---|---|
\\ |
反斜杠符号 |
\' |
单引号 |
\" |
双引号 |
\n |
换行 |
\t |
横向制表符 |
\r |
回车 |
判断是否是数字的三种方法:(开发中常用的还是isdecimal方法)
# 都不能判断小数
num_str = "123"
print(num_str.isdecimal())
print(num_str.isdigit())
print(num_str.isnumeric())
# isdigit与isnumeric的强大之处
num_str2 = "⑴"
print(num_str2.isdecimal())
print(num_str2.isdigit())
print(num_str2.isnumeric())
# isnumeric的强大之处
num_str3 = "一千零一"
print(num_str3.isdecimal())
print(num_str3.isdigit())
print(num_str3.isnumeric())
print(str.find("abc")) # 查找不存在的字符串返回-1,index方法则会报错
print(str.replace("world", "python")) # replace方法执行完毕会返回一个字符串,而不会改变源字符串
字符串去除空格、切割字符串、拼接字符串
print(str.strip()) # 去除所有的空格
print(str.lstrip()) # 去除左边的空格
print(str.rstrip()) # 去除右边的空格
str = "hello#world#java#python"
split = str.split("#") # 按照#切割字符串,默认按照不可见字符进行切割
print(split)
join = "#".join(split) # 按照#合并字符串
print(join)
下标和切片 注意可以使用倒序的方式来使用下标
# 将字符串转为列表,再得到逆序的字符串
str = "abcdefg"
str_list = list(str)
str_list.reverse()
print(''.join(str_list))
# 直接使用字符串切片功能逆转字符串
str = "abcdefgh"
print(str[::-1])
print(str[-1::-1])
Python的内置函数
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del有两种方式 |
| max(item) | 返回容器中元素最大值 | 如果是字典、只是针对key比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典、只是针对key比较 |
| cmp(item1,item2) | 比较两个值,-1 小于/ 0相等/ 1大于 | Python3.x取消了cmp函数 |
注意:字符串比较符合以下规则:“0”<“A”<“a”
# 针对列表和元组进行切片
print([1, 2, 3, 4, 5][1:3])
print((1, 2, 3, 4, 5)[1:3])
# 由于字典是一个无序集合,使用键值对的方式保存数据,所以字典是无法切片的
# 列表和元组乘法运算
print([1, 2]*5)
print((1, 2)*5)
# print({"a": "z"}) error,因为key是唯一的
# 列表
l_list = [1, 2]
l_list2 = [3, 4]
print(l_list+l_list2) # 使用加号不会改变原有的列表,而是产生新的列表
l_list.extend(l_list2) # 此方法无返回值,直接改变l_list
l_list.append(5)
l_list.append([6, 7, 8]) # append方法会把列表当成一个元素插入到列表中
print(l_list)
l_list3 = (1, 2)
l_list4 = (3, 4)
print(l_list3+l_list4)
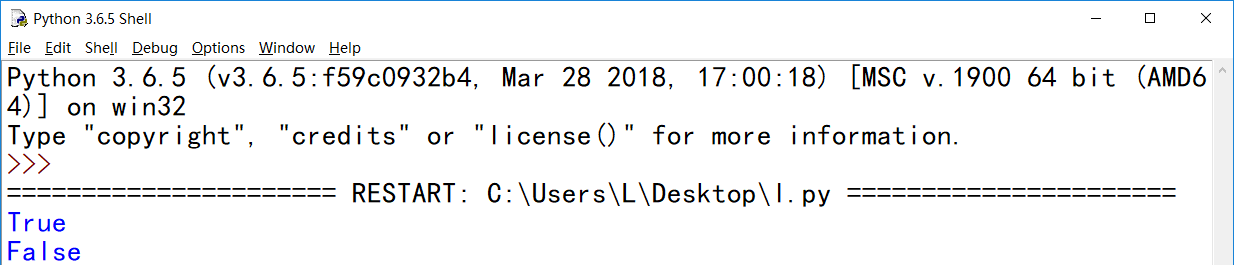
int 与 not in运算符
print("a" in "abcde")
print("a" not in "abcde")
 完整的for循环
完整的for循环
for 变量 in 集合:
循环体代码
else:
没有通过break退出循环,只有当循环结束后才会执行的代码
num = [1, 2, 3, 4, 5]
for n in num:
if n == 3:
break
print(n)
else:
print("完毕")
num = [1, 2, 3, 4, 5]
for n in num:
print(n)
else:
print("完毕")
其他
pass 关键字:pass代表空语句,就和java中的;是一样的 TODO(开发者姓名/开发者邮件) 功能描述 Linux上的Shebang符号(#!) 在要运行的python主文件在第一行加入 #! /usr/bin/python3即可,然后修改python文件权限为可执行!
全局变量
- 在函数内部无法修改全局变量的值
- 即使修改,解释器也会认为是在函数内部定义了一个与全局变量名称一样的局部变量
- 如果在函数内部需要修改全局变量,需要使用global关键字
代码结构的定义规范
- shebang
- import 模块
- 全局变量
- 函数定义
- 执行代码
注意:定义全局变量的时候应该在变量名前面加
g_或者gl_的前缀
函数返回值
- 返回多个值返回元组即可
- 使用多个变量接受返回的元组中的数据,格式
变量一,变量二... = 函数 - 使用多变量接受结果的时候,变量的个数应该和元组中元素的个数保持一致,否则会报错
Python交换数字的特殊方式
a = 10
b = 20
# 方式一
a = a+b
b = a-b
a = a-b
print("a = %d,b = %d" % (a, b))
# 方式二
a, b = (b, a)
print("a = %d,b = %d" % (a, b))
函数的参数
- 无论是可变的还是不可变的参数,针对参数使用
赋值语句,都不会影响到调用函数时传递的实参变量,影响范围只在函数内部 - 如果传递的参数是
可变类型,在函数内部,使用方法修改了数据的内容,这样才会影响到外部数据 - 列表变量使用
+=符号本质是在调用列表的extend方法,所以仍然会修改函数外部的实参
缺省参数
定义
- 定义函数时,可以给某个参数制定一个默认值,具有默认值的参数就叫缺省参数
- 函数缺省参数的作用就是将常见的值设置为参数的缺省值,从而简化函数的调用
使用场景
- 在参数后面使用赋值语句,可以指定参数的缺省值,在指定缺省值的时候需要使用最常见的值作为默认值
- 如果一个参数的值不能确定,这不应该设置默认值
注意点
- 缺省参数的定义位置必须在参数列表末尾
- 调用带有多个缺省参数的函数时,需要指定参数名,这样解释器才能知道参数的对应关系
多值参数
定义支持多值参数的函数
- 有时可能需要一个函数能够处理的参数个数是不确定的,这个时候就可以使用多值参数
python中有两种多值参数:- 参数名前面加一个
*可以接受元组 - 参数名前面加两个
*可以接受字典
- 参数名前面加一个
- 一般给多值参数命名时,习惯使用以下两个名字
*args– 存放元组参数,前面有一个***kwargs– 存放 字典参数,前面有两个*
args是arguments的缩写,有变量的含义kw是keyword的缩写,kwargs可以记忆为键值对参数
多值参数常用于框架当中!
元组的字典的拆包
-
再调用带有多值参数的函数时,如果希望:
- 将一个元组变量,直接传递给
args - 将一个字典变量,直接传递给
kwargs
- 将一个元组变量,直接传递给
-
就可以使用拆包,简化参数的传递,拆包的方式是:
- 在元组变量前,增加一个
* - 在字典变量前,增加两个
*
- 在元组变量前,增加一个
-
使用示例:
def demo(*args, **kwargs): print(args) print(kwargs) gl_nums = (1, 2, 3) gl_dict = {"name": "Tim", "age": 18} demo(gl_nums, gl_dict)
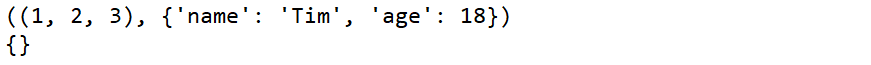
很显然这不是我们所期望看到的结果,因为解释器把字典当做元组的一个元素了,此时便需要拆包
def demo(*args, **kwargs):
print(args)
print(kwargs)
gl_nums = (1, 2, 3)
gl_dict = {"name": "Tim", "age": 18}
# demo(gl_nums, gl_dict)
# 拆包的做法
demo(*gl_nums,**gl_dict)
# 不拆包的做法
demo(1, 2, 3, name="Tim", age=18)

函数递归
- 函数调用自身称为递归,函数内部的代码是相同的,只是针对参数不同处理的结果也不同
- 当参数满足一个条件时,函数不再执行,这是递归的出口
面向对象
dir内置函数
使用内置函数dir传入标识符/数据,可以查看对象内部的所有属性和方法
提示__方法名__格式的方法是python提供的内置方法/属性
| 序号 | 方法名 | 类型 | 作用 |
|---|---|---|---|
| 01 | __new__ | 方法 | 创建对象时,会被自动调用 |
| 02 | __init__ | 方法 | 对象被初始化时,会被自动调用 |
| 03 | __del__ | 方法 | 对象被从内存中销毁前,会被自动调用 |
| 04 | __str__ | 方法 | 返回对象的描述信息,print函数输出使用 |
所以在Python中方法也是对象!!
class MyClass:
def fun(self):
pass
# 创建对象
obj = MyClass()
# print函数会直接打印出对象所属类以及地址
print(obj)
# 使用id函数获取 对象的内存地址
address = id(obj)
print(address)
# 以16进制打印地址
print("%x" % address)
self参数
在python中要给对象设置属性,非常容易,但是不推荐使用,因为对象的属性应该封装在类的内部,设置方法是对象.属性 = 值 ,这种方式虽然简单但是不推荐使用!
哪一个对象调用的方法,self就是哪一个对象的引用
class Student:
def study(self):
print("%s开始学习" % self.name)
self.eat()
def eat(self):
pass
s1 = Student()
s1.name = "Tim"
s1.study()
self参数也可以访问到类中属性和方法,在开发中不推荐在类的外部给类增加属性,如果在运行时没找到属性,程序就会报错。所有属性都应该封装在类的内部
__init__方法
__init__方法相当于Java中的构造方法!
-
当使用
类名()创建对象是,会自动分配空间并执行__init__方法,__init__是对象的内置方法,专门用来定义一个类具有哪些属性的方法,在__init__方法内部使用self.属性名= 初始值就可以定义属性! -
对
__init__方法加上参数,就可以在__init__内部使用self.属性 = 形参接收外部传递的参数 -
在创建对象时,使用
类名(属性1, 属性2...)的形式即可完成对象的构造
__del__方法
__del__方法就相当于C++中的析构函数!
当使用类名()创建对象时,自动调用__init__方法,当对象从内存中销毁之前,会自动调用__del__方法
应用场景
-
__init__改造初始化方法,可以让创建对象更加灵活 -
__del__如果希望在对象被销毁前做些事情,考虑使用__del__方法
生命周期
__init__————–>__del__
__str__方法
相当于Java的toString方法
直接使用print打印对象获得的结果是该对象的所属类和在内存中的地址,如果希望自定义内容,__str__方法是不二之选!
身份运算符
is或is not,注意is与==的区别:
is用来判断两个不舒服引用的对象是否是同一个,相当于Java的==
==用来判断引用变量的值是否相等,相当于Java的equest方法
私有属性和私有方法
定义方式
在定义属性或者方法时,在属性名或者方法名前增加两个下划线,定义的就是私有属性或方法
伪私有属性和私有方法
Python并没有真正意义上的私有
在给属性和方法命名时,实际是对名称做了一些特殊的处理,使的外界无法访问
处理方式:在名称前面加上_类名=>_类名__名称
继承
格式:class 类名(父类名)
子类继承父类的所有属性和方法
方法重写
重写父类方法有两种情况
- 覆盖父类中的方法
- 对父类中的方法进行扩展
- 重写之后只会调用子类中重写的方法,而不会调用父类中封装的方法
关于super
- 在python中super是一个特殊的类
super()就是使用spuer类创建出来的对象- 最常使用的场景就是在重写父类方法时,调用在父类中封装的方法实现
调用父类方法的另一种方式,在Python2.x时,如果需要调用父类的方法,还可以使用
父类名.方法(self),这种方式目前在Python3.x还支持,但是不推荐使用
在开发中父类名和super()两种方式不要混用,如果使用当前子类名调用方法会形成递归调用,出现死循环
父类的私有属性和私有方法
- 子类对象不能在自己的方法内部直接访问父类的私有属性或者私有方法
- 子类对象可以通过父类的公有方法简介访问到私有属性或者私有方法,例如
Java的get和set - 私有属性、方法是对象的隐私,不对外公开,外界及其子类都不能访问
多继承
子类可以有多个父类,并且具有所有父类的属性和方法
格式class 子类名(父类名1,父类名2... )
如果不同的父类中存在同名的方法,子类在调用父类中的方法时会不明确调用哪一个方法,所以开发时应该尽且避免这种容易产生混淆的情况!如果父类之间存在同名的属性或方法.应该尽量避免使用多继承!
Python中的MRO – 方法搜索顺序
- Python中针对类提供了一个内置属性
__mor__可以查看方法搜索顺序 - MRO的全称是
method reslution order,主要是用于在多继承的时候判断方法、属性的调用路径
class A:
pass
class B:
pass
class C(A, B):
pass
print(C.mro())
输出:[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
- 在搜索方法时,时按照
__mro__的输出结果从左至右的顺序查找的 - 如果在当前类中找到方法,就直接执行,不再搜索
- 如果没有找到,就查找下一个类中是否有对应的方法,如果找到,就直接执行,不再搜索
- 如果找到最后一个类买还是没有找到方法,程序报错
新式类与旧式(经典)类
object是python为所有对象提供的基类,提供有一些内置的属性和方法,使用dir函数查看
-
新式类:以object作为基类的类,推荐使用
-
经典类:不以object作为基类的类,不推荐使用
-
Python3.x中所有的类都是新式类
-
Python2.x中如果没有指定父类,则不会以object作为父类
-
新式类和旧式类在多继承时会影响到方法的搜索顺序,建议统一使用新式类
多态
不同的子类对象,调用的相同的父类方法,产生不同的执行结果
-
增加代码的灵活度
-
以继承和重写父类方法为前提
-
是调用方法的技巧,不会影响到类的内部设计
每一个对象都有自己的独立的内存空间,保存各自不同的属性
每个对象的方法在内存中只有一份,在调用方法时,需要把对象的引用传递到方法内部
Python中一切皆对象
class AAA:定义的类属于类对象
obj = AAA()属于实例对象
-
在程序运行时,类同样会被加载到内存,在Python中类是一个特殊的对象
-
在程序运行时,类对象在内存中只有一份
-
除了封装实例的属性和方法外,类对象还可以拥有自己的属性和方法
- 类属性
- 类方法
-
通过
类名.的方式可以访问类的属性或者调用类的方法
类属性和实例属性
- 类似于Java的static成员变量
- 类属性就是给类对象中定义的属性
- 通常用来记录与这个类相关的特征
- 类属性不会用于记录对象的特征
示例需求
- 定义一个工具类
- 每件工具都有自己的name
- 需求 – 直到使用这个类,创建了多少个工具对象?
class Tool:
# 定义类属性
count = 0
def __init__(self, name):
self.name = name
# 让类属性的值加一
Tool.count += 1
t1 = Tool("AAA")
t2 = Tool("BBB")
t3 = Tool("CCC")
t4 = Tool("DDD")
print(t1.count) # 总创建了4个对象
属性的获取机制
在Python中属性的获取存在一个向上查找机制,首先在对象内部查找对象属性,没有的话就会向上查找类属性
所以访问类属性有两种方式:
-
类名.类属性 -
对象.类属性(不推荐使用)
注意如果使用对象.类属性 = 值赋值语句,只会对给对象添加一个属性,而不会影响到类属性的值
类方法与静态方法
类方法与类属性一致,类方法是针对这个类而定义的方法,而不是针对对象定义的方法
类方法
语法如下:
class 类名:
@classmethod
def 类方法名(cls):
pass
-
类方法需要使用
@classmethod来标识,告诉解释器这是一个类方法 -
类方法的第一个参数应该是
cls- 由哪一个类调用的方法,方法内的
cls就是那一个类引用 - 这个参数与实例方法的
self比较相似 - 使用其他名称也可以,不一定非的是cls,不过习惯使用
cls
- 由哪一个类调用的方法,方法内的
-
通过
类名.的方式调用类方法时不需要传递cls参数 -
在方法内部
-
可以通过
cls.访问类属性 -
可以通过
cls.调用类方法
-
静态方法
如果一个方法需要访问实例属性,那么封装为实例方法,如果需要访问类属性,使用类名.访问类属性
如果一个方法需要访问类属性,那么封装为类方法
如果一个方法既不需要访问实例属性,也不需要访问类属性,那么封装为静态方法
语法如下:
@staticmethod
def 静态方法名称():
pass
- 静态方法需要用修饰器
@staticmethod来标识,告诉解释器这是静态方法 - 通过
类名.调用静态方法
单例模式
内存中只有一个该类的实例
- 定义一个类属性,初始值为
None,用来记录单例对象的引用 - 重写
__new__方法 - 如果类属性
is None,调用父类方法并分配空间,并在类属性中记录结果 - 返回类属性中记录的结果
__new__方法
-
使用**类名()**创建对象时,python的解释器会自动调用
__new__方法为对象分配空间 -
__new__是一个由object基类提供的内置静态方法,作用- 在内存中为对象分配空间
- 返回对象的引用
-
python的解释器获取引用后,将引用作为第一个参数,传递给
__init__方法重写
__new__方法的代码非常固定! -
重写
__new__方法一定要return super().__new__(cls) -
否则Python的解释器得不到分配空间的对象引用,就不会调用对象的初始化方法
-
注意:
__new__是一个静态方法,在调用时需要主动传递cls参数
class MusicPlayer(object):
# 记录第一个被创建对象的引用
instance = None
def __new__(cls, *args, **kwargs):
# 判断类属性是否为空对象
if cls.instance is None:
# 调用父类方法,为第一个对象分配空间
cls.instance = super().__new__(cls)
# 返回类属性保存的对象引用
return cls.instance
m1 = MusicPlayer()
m2 = MusicPlayer()
print(m1)
print(m2)
< __main__.MusicPlayer object at 0x000001F9A381F8D0> <__main__.MusicPlayer object at 0x000001F9A381F8D0>
上面的做法虽然可以完成单例,但是初始化方法还是执行了两次,稍加修改让init方法也执行一次
class MusicPlayer(object):
# 记录第一个被创建对象的引用
instance = None
# 初始化方法调用标记
init_flag = False
def __new__(cls, *args, **kwargs):
# 判断类属性是否为空对象
if cls.instance is None:
# 调用父类方法,为第一个对象分配空间
cls.instance = super().__new__(cls)
# 返回类属性保存的对象引用
return cls.instance
def __init__(self):
if MusicPlayer.init_flag is False:
super()
MusicPlayer.init_flag = True
print("init()...")
m1 = MusicPlayer()
m2 = MusicPlayer()
print(m1)
print(m2)
异常
捕获异常
- 简单基本格式
try:
尝试执行的代码
except:
出现错误的处理
- 错误类型捕获,针对不同类型的异常,做出不同的处理
try:
pass
expect 错误类型1:
# 针对错误类型1的处理
pass
expect 错误类型2:
# 针对错误类型2的处理
pass
expect Exception as result:
print("未知错误%s" % result)
捕获异常的完整语法
try:
# 尝试执行的代码
pass
expect 错误类型1:
# 针对错误类型1的处理
pass
expect 错误类型2:
# 针对错误类型2的处理
pass
except(错误类型3,错误类型4):
pass
except Exception as result:
# 打印错误信息
print(result)
else:
# 没有异常才会执行的代码
pass
finally:
# 必须要执行的代码
异常的传递
如果在某个函数中发生异常却未处理,异常会传递给调用方,会层层向上传递直到有遇到处理异常的代码为止,如果都没有处理此异常将会传递至主程序!
手动抛出异常
Python提供了一个Exception异常类,如果希望抛出异常先创建一个Exception的对象,然后使用raise关键字抛出异常对象即可!
模块
import 模块名1,模块名2不推荐使用,每个导入应该独占一行import 模块名 as 名称简写给模块起别名from 模块名 import 工具名从某一个模块中导入部分工具,这种方式导入的话不需要通过模块名.的方式来访问的,导入之后可以直接使用模块提供的工具—–全局变量、函数、类
注意如果两个模块存在同名的函数,那么后导入的模块的函数会覆盖先导入的函数!
from 模块名 import *这样可以一次性把模块中的所有工具全部导入,不推荐使用
模块的搜索顺序
搜索当前目录指定模块名的文件,如果有就直接导入,没有的话再搜索系统目录
注意:在开发时给文件起名不要和系统模块文件重名!
Python中每一个模块都有一个内置属性__file__可以查看模块的完整路径
原则–每一个文件都应该是可以被导入的
在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍
应用场景:模块的开发者通常会在模块下方增加一些测试代码,仅仅在模块内补使用,不会被到导入到其他文件中
__name__属性
-
__name__属性可以做到,测试模块的代码只在测试情况下运行,而被导入时不会被执行 -
__name__时python的一个内置属性,记录着一个字符串 -
如果是被其他文件导入的,
__name__就是模块名 -
如果是当前执行的程序,
__name__是__main__if __name__ == "__main__": # 测试代码 pass
包(Package)
包下必须有一个特殊的文件__init__.py,使用import 包名可以导入包下所有的模块
__init__.py
- 要在外界使用包中的模块,需要在
__init__.py中指定对外提供的模块列表
# 从当前目录导入模块列表
from . import 模块名
发布压缩包的制作
- 创建
setup.py文件,关于字典参数的详细信息,http://docs.python.org/2/distutils/apiref.html - 构建模块
python2 setup.py build - 生成发布压缩包
puthon3 setup.py sdist
安装/卸载模块
- 先解压
tar -zxvf 文件名 - 再安装
sudo python3 setup.py install cd /usr/local/lib/python3.5/dist-packages再sudo rm -f XXX即可卸载
pip安装第三方模块
pip是一个通用的python包管理工具,提供了对Python包的查找、下载、安装、卸载等功能
例如安装pygame这个模块sudo pip install pygame但是这样只能将模块安装到Python2.x环境,如果需要安装到Python3.x的环境,需要使用sudo pip3 install pygame
文件
在Python中操作文件需要记住1个函数3个方法
| 函数/方法 | 说明 |
|---|---|
| open(函数) | 打开文件,并且返回文件操作对象 |
| read | 将文件读取到内存 |
| write | 将指定内容写入文件 |
| close | 关闭文件 |
open函数默认以只读方式打开文件,并且返回文件对象
| 访问方式 | 说明 |
|---|---|
| r | 以只读方式打开,这是默认模式,如果文件不存在则抛出异常 |
| w | 以只写方式打开文件,如果文件存在会被覆盖,如果文件不存在则创建新文件 |
| a | r+以追加方式打开文件,如果文件存在,文件指针将会放到末尾,若不存在创建新文件 |
| r+ | 以读写方式打开文件,文件的指针将会放在文件的开头,如果文件不存在,抛出异常 |
| w+ | 以读写方式打开文件,如果文件存在,文件指针将会放在文件的开头,如果不存在创建新文件 |
| a+ | 以读写方式打开文件,如果文件已经存在,文件指针将会放在文件的结尾,若不存在就创建新文件写入 |
file = open("a.txt", "r")
while True:
text = file.readline()
if not text:
break
print(text, end="")
文件/目录的常用管理操作
创建、重命名、删除、更改路径、查看目录内容…
Python 中如果希望通过程序实现上述功能需要导入os模块
文件操作
| 方法名 | 说明 | 示例 |
|---|---|---|
| rename | 重命名文件 | os.rename(源文件名,目标文件名) |
| remove | 删除文件 | os.remove(文件名) |
目录操作
| 方法名 | 说明 | 示例 |
|---|---|---|
| listdir | 目录列表 | os.listdir(目录名) |
| mkdir | 创建目录 | os.mkdir(目录名) |
| rmdir | 删除目录 | os.rmdir(目录名) |
| getcwd | 获取当前目录 | os.getcwd() |
| chdir | 修改工作目录 | os.chdir(目标目录) |
| path.isdir | 判断是否是文件 | os.psth.isdir(文件路径) |
注意:文件或者目录都支持相对路径和绝对路径
文本文件的编码格式
- 文本文件存储的内容是基于字符编码的文件,常见的编码有
ASCII编码,UNICODE编码 - Python2.x默认使用
ASCII编码 - Python3.x默认使用
UTF-8编码
在Python2.x文件的第一行增加以下注释,解释器会以UTF-8编码来处理文件,这也是官方推荐的方式
# *-* coding:utf8 *-*
Python2.x中使用中文字符串需要在字符串前面加小写u,例如str = u"中文"即可!
eval函数
- 基本的数学计算,与JavaScript中的eval函数一致
In [1]: eval("5-3")
Out[1]: 2
In [2]: eval("'*' * 10")
Out[2]: '**********'
In [3]: type(eval("[1, 2, 3, 4, 5]"))
Out[3]: list
In [4]: type(eval("{'name':'Tim', 'age':20}"))
Out[4]: dict
注意在开发时不要使用eval函数转换input的结果!
一旦用户输入__import__('os').system('终端命令')这样的是非常可怕的!
==、is
is是比较两个引用是否指向了同一个对象,即比较地址是否相同==是比较两个对象的值是否相等
In [1]: a = 10
In [2]: b = 10
In [3]: a == b
Out[3]: True
In [4]: a is b
Out[4]: True
In [5]: a = 257
In [6]: b = 257
In [7]: a == b
Out[7]: True
In [8]: a is b
Out[8]: False
深拷贝与浅拷贝
In [1]: a = [1, 2, 3]
In [2]: b = a
In [3]: id(a)
Out[3]: 3143865105928
In [4]: id(b)
Out[4]: 3143865105928
In [5]: import copy as cp
In [6]: c = cp.deepcopy(a)
In [7]: id(a)
Out[7]: 3143865105928
In [8]: id(c)
Out[8]: 3143864558088
深拷贝是真的深!
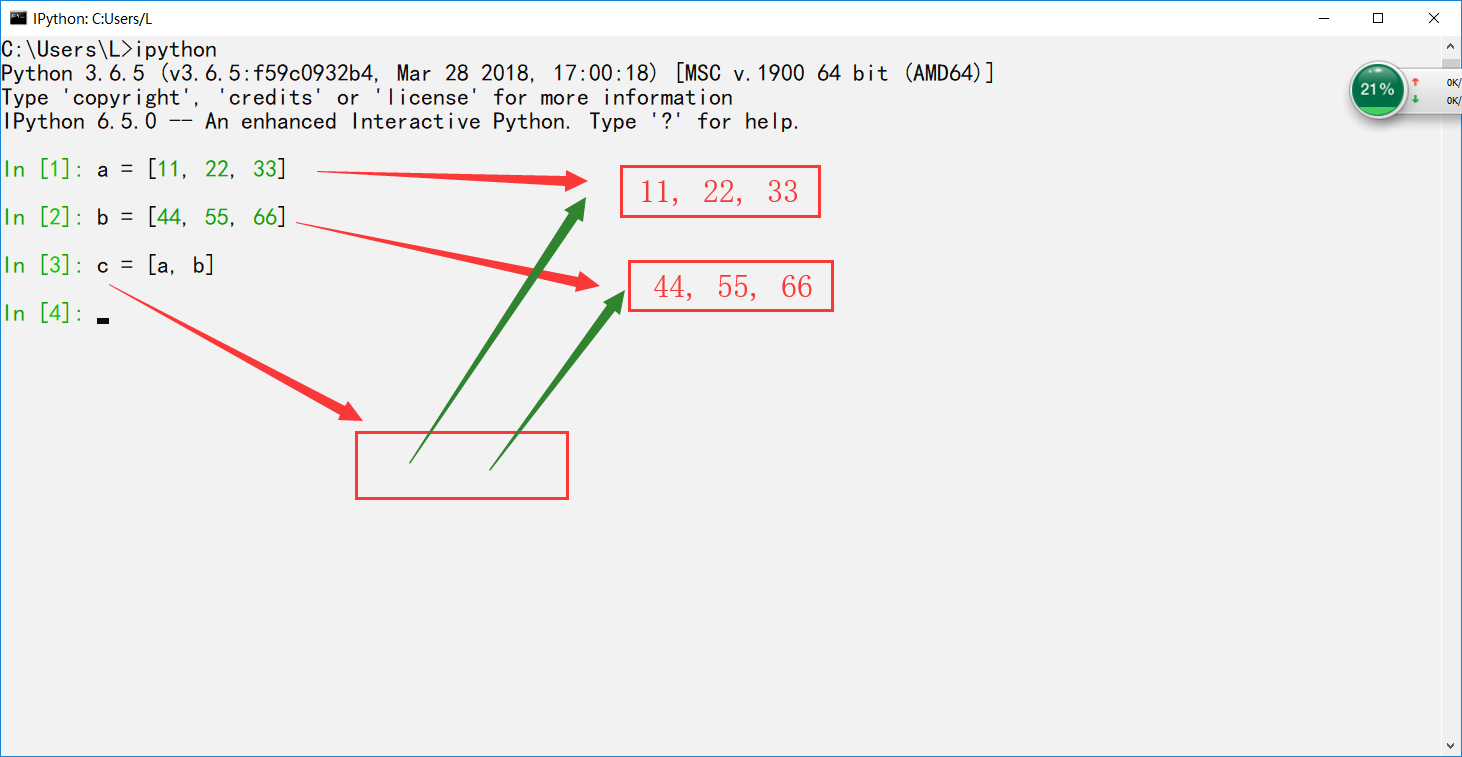
In [1]: a = [11, 22, 33]
In [2]: b = [44, 55, 66]
In [3]: c = [a, b]
In [4]: d = c
In [5]: id(c)
Out[5]: 2236861508936
In [6]: id(d)
Out[6]: 2236861508936
In [7]: import copy as cp
In [8]: e = cp.deepcopy(c)
In [9]: id(e)
Out[9]: 2236861766984
In [10]: a.append(44)
In [11]: e[0]
Out[11]: [11, 22, 33]
拷贝的其他方式
浅拷贝对不可变类型和可变类型的拷贝不同
In [1]: a = [11, 22, 33]
In [2]: import copy as cp
In [3]: b = cp.copy(a)
In [4]: id(a)
Out[4]: 2909126778056
In [5]: id(b)
Out[5]: 2909126747464
In [6]: a.append(44)
In [7]: a
Out[7]: [11, 22, 33, 44]
In [8]: b
Out[8]: [11, 22, 33]
In [9]: a = (11, 22, 33)
In [10]: b = cp.copy(a)
In [11]: id(a)
Out[11]: 2909126674544
In [12]: id(b)
Out[12]: 2909126674544
分片表达式可以构造一个序列
a = "abc"
b = a[:]
字典的copy方法可以拷贝一个字典
In [13]: d = dict(name="Tim", age=10)
In [14]: co = d.copy()
In [15]: id(d)
Out[15]: 2909126284992
In [16]: id(co)
Out[16]: 2909126780176
有些内置函数可以生成拷贝
In [17]: a = list(range(10))
In [18]: b = list(a)
In [19]: b
Out[19]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [20]: id(b)
Out[20]: 2909126777096
In [21]: id(a)
Out[21]: 2909126776456
Python是动态语言
在计算机科学领域已被广泛应用。它是一类在运行时可以改变其结构的语语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言非常具有活力。例如JavaScript便是动态语言,除此之外如PHP 、 Ruby 、 Python 等也都属于动态语言,C 、 C++ 则不属于动态语言!
运行的过程中给对象绑定(添加)属性
这个比较简单,格式:对象.属性 = 值 即可
运行的过程中给类绑定(添加)属性
格式:类名.属性 = 值即可
运行的过程中给类绑定(添加)方法
#-*- coding:utf-8 -*-
import types
class Person(object):
def __init__(self, newName, newAge):
self.name = newName
self.age = newAge
def eat(self):
print("----%s正在吃----" % self.name)
p = Person("老王", 20)
p.eat()
# 给对象绑定方法
def run(self):
print("----%s正在跑----" % self.name)
p.run = types.MethodType(run, p)
p.run()
# 给Person类绑定类方法
@classmethod
def testClassMethod(cls):
print("class method")
Person.testclass = testClassMethod
Person.testclass()
# 给Person类绑定静态方法
@staticmethod
def testStaticMethod():
print("static method")
Person.teststatic = testStaticMethod
Person.teststatic()
__slots__
动态语言:可以在运行的过程中,修改代码
静态语言:编译器时期就已经确定代码,运行过程中不能修改
如果我们想要限制实例的属性怎么办?⽐如,只允许对Person实例添加name和age属性。 为了达到限制的⽬的,Python允许在定义class的时候,定义⼀个特殊的__slots__变量,来限制该class实例能添加的属性:
In [1]: class Person(object):
...: __slots__ = ("name", "age")
...:
In [2]: p = Person()
In [3]: p.name = "XXX"
In [4]: p.age = 20
In [5]: p.other = "---"
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-5-dbbcced1d9ea> in <module>()
----> 1 p.other = "---"
AttributeError: 'Person' object has no attribute 'other'
注意
- 使⽤__slots__要注意,__slots__定义的属性仅对当前类实例起作⽤,对继承的⼦类是不起作⽤的
元类
类也是对象
在⼤多数编程语⾔中,类就是⼀组⽤来描述如何⽣成⼀个对象的代码段。在Python中这⼀点仍然成⽴!
Python中的类还远不⽌如此。类同样也是⼀种对象。是的,没错,就是对象。只要你使⽤关键字class,Python解释器在执⾏的时候就会创建⼀个对象!
In [1]: class Person:
...: pass
...:
...:
In [2]: print(Person)
<class '__main__.Person'>
将在内存中创建⼀个对象,名字就是ObjectCreator。这个对象(类对象ObjectCreator)拥有创建对象(实例对象)的能⼒。但是,它的本质仍然是⼀个对象,于是乎你可以对它做如下的操作:
- 你可以将它赋值给⼀个变量
- 你可以拷⻉它
- 你可以为它增加属性
- 你可以将它作为函数参数进⾏传递
>>> print ObjectCreator # 你可以打印⼀个类,因为它其实也是⼀个对象
<class '__main__.ObjectCreator'>
>>> def echo(o):
… print o
…
>>> echo(ObjectCreator) # 你可以将类做为参数传给函数
<class '__main__.ObjectCreator'>
>>> print hasattr(ObjectCreator, 'new_attribute')
Fasle
>>> ObjectCreator.new_attribute = 'foo' # 你可以为类增加属性
>>> print hasattr(ObjectCreator, 'new_attribute')
True
>>> print ObjectCreator.new_attribute
foo
>>> ObjectCreatorMirror = ObjectCreator # 你可以将类赋值给⼀个变量
>>> print ObjectCreatorMirror()
<__main__.ObjectCreator object at 0x8997b4c>
动态地创建类
因为类也是对象,你可以在运⾏时动态的创建它们,就像其他任何对象⼀样。⾸先,你可以在函数中创建类,使⽤class关键字即可!
In [1]: def chose_class(name):
...: if name == "foo":
...: class Foo(object):
...: pass
...: return Foo # 返回的是类,而不是类的实例
...: else:
...: class Bar(object):
...: pass
...: return Bar
...:
In [2]: MyClass = chose_class("foo")
In [3]: print(MyClass)
<class '__main__.chose_class.<locals>.Foo'>
In [4]:
但这还不够动态,因为你仍然需要..编写整个类的代码。由于类也是对象,所以它们必须是通过什么东.来.成的才对。当你使.class关键字时,Python解释器自动创建这个对象。但就和Python中的大多数事情一样,Python仍然提供给你自动处理的方法。
In [4]: print(type(100))
<class 'int'>
In [5]: print(type("Hello XPU"))
<class 'str'>
In [6]: print(type(MyClass))
<class 'type'>
类对象的类型居然是type!!!
使用type创建类
type还有一种完全不同的功能,动态的创建类。 type可以接受一个类的描述作为参数,然后返回一个类(要知道,根据传入参数的不同,同一个函数拥有两种完全不同的用法是件很傻的事情,但这在Python中是为了保持向后兼容性)
type创建类的格式
type(类名,由父类名称组成的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
In [7]: class Person:
...: nums = 0
...:
In [8]: MyPerson = type("MyPerson",(),{"num":0})
In [9]: p1 = Person()
In [11]: p1.nums
Out[11]: 0
In [12]: p2 = MyPerson()
In [13]: p2.num
Out[13]: 0
使用Type创建带属性的类
In [1]: Foo = type("Foo", (),{"bar":True})
In [2]: class Foo2(object):
...: bar = True
...:
注意
- type的第2个参数,元组中是⽗类的名字,⽽不是字符串
- 添加的属性是类属性,并不是实例属性
使⽤type创建带有⽅法的类
In [1]: Foo = type("Foo", (),{"bar":True})
In [2]: class Foo2(object):
...: bar = True
...:
In [3]: def my_fun(self):
...: print(self.bar)
...:
In [4]: FooChild = type('FoodChild',(Foo,), {'echo_bar':my_fun})
In [5]: my_foo = FooChild()
In [6]: my_foo.echo_bar()
True
添加静态方法
同上,需要在方法上面加注@staticmethod即可
添加类方法
同上,需要在方法上面加注@classmethod即可
元类的概念
在Python中,类也是对象,你可以动态的创建类。这就是当你使⽤关键字class时Python在幕后做的事情,⽽这就是通过元类来实现的!
元类就是⽤来创建类的“东⻄”。你创建类就是为了创建类的实例对象,不是吗?但是我们已经学习到了Python中的类也是对象。
函数type实际上是⼀个元类。type就是Python在背后⽤来创建所有类的元类。现在你想知道那为什么type会全部采⽤⼩写形式⽽不是Type呢? 好吧,我猜这是为了和str保持⼀致性,str是⽤来创建字符串对象的类,⽽int是⽤来创建整数对象的类。type就是创建类对象的类!可以通过检查__class__属性来看到这.点。Python中所有的东西都是对象。这包括整数、字符串、函数以及类。它们全部都是对象,而且它们都是从一个类创建而来,这个类就是type。
__metaclass__属性
定义⼀个类的时候为其添加__metaclass__属性
class Foo(object):
__metaclass__ = something...
如果你这么做了,Python就会⽤元类来创建类Foo。⼩⼼点,这⾥⾯有些技巧。你⾸先写下class Foo(object),但是类Foo还没有在内存中创建。Python会在类的定义中寻找__metaclass__属性,如果找到了,Python就会⽤它来创建类Foo,如果没有找到,就会⽤内建的type来创建这个类。把下⾯这段话反复读⼏次。当你写如下代码时:
class Foo(Bar):
pass
Python做了如下的操作:
-
Foo中有
__metaclass__这个属性吗?如果是,Python会通过__metaclass__创建⼀个名字为Foo的类(对象) -
如果Python没有找到
__metaclass__,它会继续在Bar(⽗类)中寻找__metaclass__属性,并尝试做和前⾯同样的操作 -
如果Python在任何⽗类中都找不到
__metaclass__,它就会在模块层次中去寻找__metaclass__,并尝试做同样的操作 -
如果还是找不到
__metaclass__,Python就会⽤内置的type来创建这个类对象
你可以在__metaclass__中放置些什么代码呢?答案就是:可以创建一个类的东西。那么什么可以用来创建一个类呢?type,或者任何使用到type或者子类化type的东西都可以!
自定义元类
你决定在你的模块⾥所有的类的属性都应该是⼤写形式。有好⼏种⽅法可以办到,但其中⼀种就是通过在模块级别设定__metaclass__采⽤这种⽅法,这个模块中的所有类都会通过这个元类来创建,我们只需要告诉元类把所有的属性都改成⼤写形式就万事⼤吉了!
Python2.x中的写法:
#-*- coding:utf-8 -*-
def upper_attr(future_class_name, future_class_parents, future_class_attr):
# 便利属性字典,将不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
# 调用type来创建一个类
return type(future_class_name,future_class_parents, newAttr)
class Foo(object):
__metaclass__ = upper_attr # 设置Foo类的元类为upper_attr
bar = 'bip'
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
Python3.x的写法
#-*- coding:utf-8 -*-
def upper_attr(future_class_name, future_class_parents, future_class_attr):
# 便利属性字典,将不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
# 调用type来创建一个类
return type(future_class_name,future_class_parents, newAttr)
class Foo(object, metaclass=upper_attr): # 设置Foo类的元类为upper_attr
bar = 'bip'
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
两者的区别只是__metaclass的位置不一样!
就是这样,除此之外,关于元类真的没有别的可说的了。但就元类本身⽽ ⾔,它们其实是很简单的:
- 拦截类的创建
- 修改类
- 返回修改之后的类
“Yuan is the magic of depth, and 99% of households should not have to do so. If you want to find out if you need to go to a meta class, you don’t need it. Those that are actually metaclasses often know exactly what they need to do, and there is no need to explain why they need metaclasses at all. " Tim Peters, the leader of the Python world!
模块重新导入
import XXX是在当前目录找模块,如果需要其他路径的模块:
import sys
sys.path.append("XXX路径")
如果在导入模块之后,模块又发生了修改,此时需要重新导入
reload(模块名)这样便可以重新加载模块,使用此函数的前提是form imp import *
循环导入
循环导入的概念
a.py
from b import b
print '---------this is module a.py----------'
def a():
print("hello, a")
b()
a()
b.py
from a import a
print '----------this is module b.py----------'
def b():
print("hello, b")
def c():
a()
c()
运行a.py发现a和b这两个模块是相互导入的,这样就会出现循环导入的问题!
怎样避免循环导入
- 程序设计上分层,降低耦合
- 导入语句放在后面需要导入时再导入,例如放在函数体内导入
进制与位运算
原码、反码与补码
-
在计算机用一个数的最高位存放符号, 正数为0, 负数为1
-
正数的原反补码都一样
-
负数的反码是在原码的基础上,符号位不变其他位取反
-
负数的补码是在反码的基础上+1
负数从补码转换为原码的规则:补码的符号位不变——>数据位取反——>尾部+1
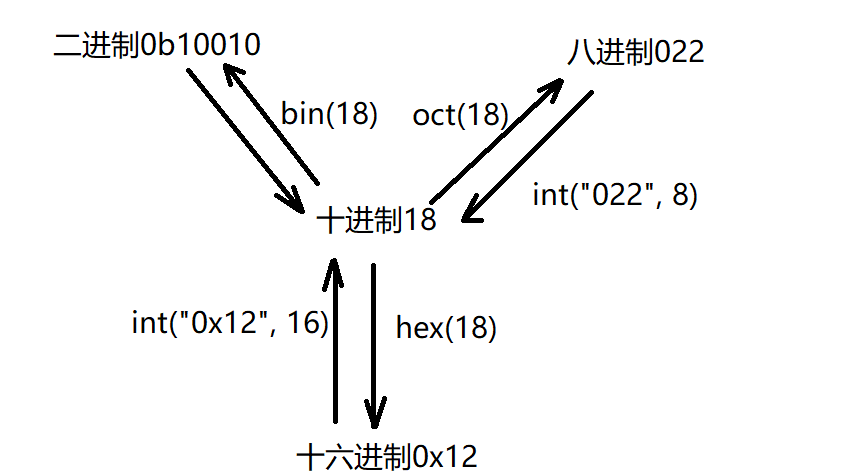
进制转换
二进制是以0b开头,十六进制以0x开头
# 十进制转二进制
In [1]: bin(10)
Out[1]: '0b1010'
# 二进制转十进制
In [2]: int("1001", 2)
Out[2]: 9
# 十进制转十六进制
In [3]: hex(10)
Out[3]: '0xa'
# 十六进制转十进制
In [4]: int("ff",16)
Out[4]: 255
# 十六进制转二进制
In [5]: bin(0xa)
Out[5]: '0b1010'
位运算
- 按位与
&:全为1结果才是1 - 按位或
|:只要有一个为0结果就是1 - 按位异或
^:只要不相同就是1 - 按位取反
~:各个位于原来的相反 - 按位左移
<<:各个二进制位全部左移n位,低位补0 - 按位右移
>>:各个二进制位全部右移n位,保持符号位不变
位运算交换两个数
#-*- coding:utf-8 -*-
a = 10
b = 20
a = a^b
b = a^b
a = a^b
print(a)
print(b)
私有化
- xx: 公有变量
- _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问
- __xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)
- __xx__:双前后下划线,用户名字空间的魔法对象或属性。例如: __init__ , 不要自己发明这样的名字
- xx_:单后置下划线,用于避免与Python关键词的冲突
总结
- 父类中属性名为
__名字的,子类不继承,子类不能访问 - 如果在子类中向 __名字 赋值,那么会在子类中定义的一个与父类相同名字的属性
_名字的变量、函数、类在使用from xxx import *时都不会被导入
属性property
私有属性添加getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
使用property升级getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
money = property(getMoney, setMoney)
使用property取代getter和setter方法
@property成为属性函数。可以对属性赋值时作必要的检查,并且保证代码的清晰短小
- 将方法转换为只读
- 重新实现一个属性的设置和读取方法,可做边界判定
class Money(object):
def __init__(self):
self.__money = 0
@property
def money(self):
return self.__money
@money.setter
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
这样访问是就可以直接使用对象.属性的方式访问,但是本质还是去调用方法!