注解的原理与实现
注解这个东西自从SpringBoot以来一直是Java开发者们必备的生存技巧呀,我们平时几乎大部分时间都是面向注解编程,通过注解我们可以节约大量的时间。用过了这么多的注解,那么我们否有关注过注解的实现原理呢?所以本篇文章主要是讲述注解的有关操作,自己实现一个注解来体会注解的实现原理,注解也不是特别高深的东西,掌握了自然就明白了。
注解这个东西自从SpringBoot以来一直是Java开发者们必备的生存技巧呀,我们平时几乎大部分时间都是面向注解编程,通过注解我们可以节约大量的时间。用过了这么多的注解,那么我们否有关注过注解的实现原理呢?所以本篇文章主要是讲述注解的有关操作,自己实现一个注解来体会注解的实现原理,注解也不是特别高深的东西,掌握了自然就明白了。
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此它也没有快排应用广泛。快速排序算法虽然最坏情况下的时间复杂度是 O(n²),但是平均情况下时间复杂度都是 O(nlogn)。且快速排序算法时间复杂度退化到 O(n²) 的概率非常小,我们可以通过合理地选择基准值来避免这种情况。
快速排序(Quick Sort)被称为20世纪对世界影响最大的算法之一,现在我们来看快速排序算法,习惯性把它简称为快排,快排利用的也是分治思想。乍看起来,它有点像归并排序,但是思路其实完全不一样。现在,我们先来看下快排的核心思想,最后将讲述快速排序的两个优化方案,其实还有一种三路快排的优化方案也是可以的,但是本片文章重点在于快速排序的原理和实现,所以三路快排的优化方案不会出现在这篇文章里,以后再详细记录一下。
之前几篇文章我介绍了三种O(n²)的排序算法 《O(n²)的三个排序算法》 (选择排序、插入排序和冒泡排序)以及它们的优化,然后顺便还写了一篇希尔排序的文章 《插入排序的优化之希尔排序》 ,但是其实用的比较多的还是直接插入排序,它们比较适合于小规模数据的排序 。下面我将记录时间复杂度为nlog(n)的几种排序算法之一 —— 归并排序算法,这种排序算法适合大规模的数据排序,比之前的O(n²)的三种排序算法更为常用,在学习之前我们可以先对比一下nlog(n)和n²是什么概念。
希尔排序是插入排序的一种,又称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法,可以说它是插入排序的高级版。我们可以先回顾一下直接插入排序的过程:

排序前将第一个元素看成有序的数列
今天复习下最简单的三个排序算法,一个是选择排序,一个是插入排序,一个是冒泡排序,三者时间复杂度都是O(n²),通过分析来发现三者的优劣,以及对最好的情况和最坏的情况进行分析。 另外,这三中排序算法都是基于比较的排序算法。基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
我们知道SpringBoot的理念就是约定大于配置,这也使得我们在开发应用程序的过程更加便捷,以前的大量XML配置直接是噩梦呀,现在出现了SpringBoot明显降低了开发成本,而且大量的注解的使用帮我们省略掉了很多代码。本篇文章主要探究的是SpringBoot是如何实现自动配置并且如何加载配置Bean的,其实主要就是探究@EnableAutoConfiguration注解究竟发挥了怎样的作用。
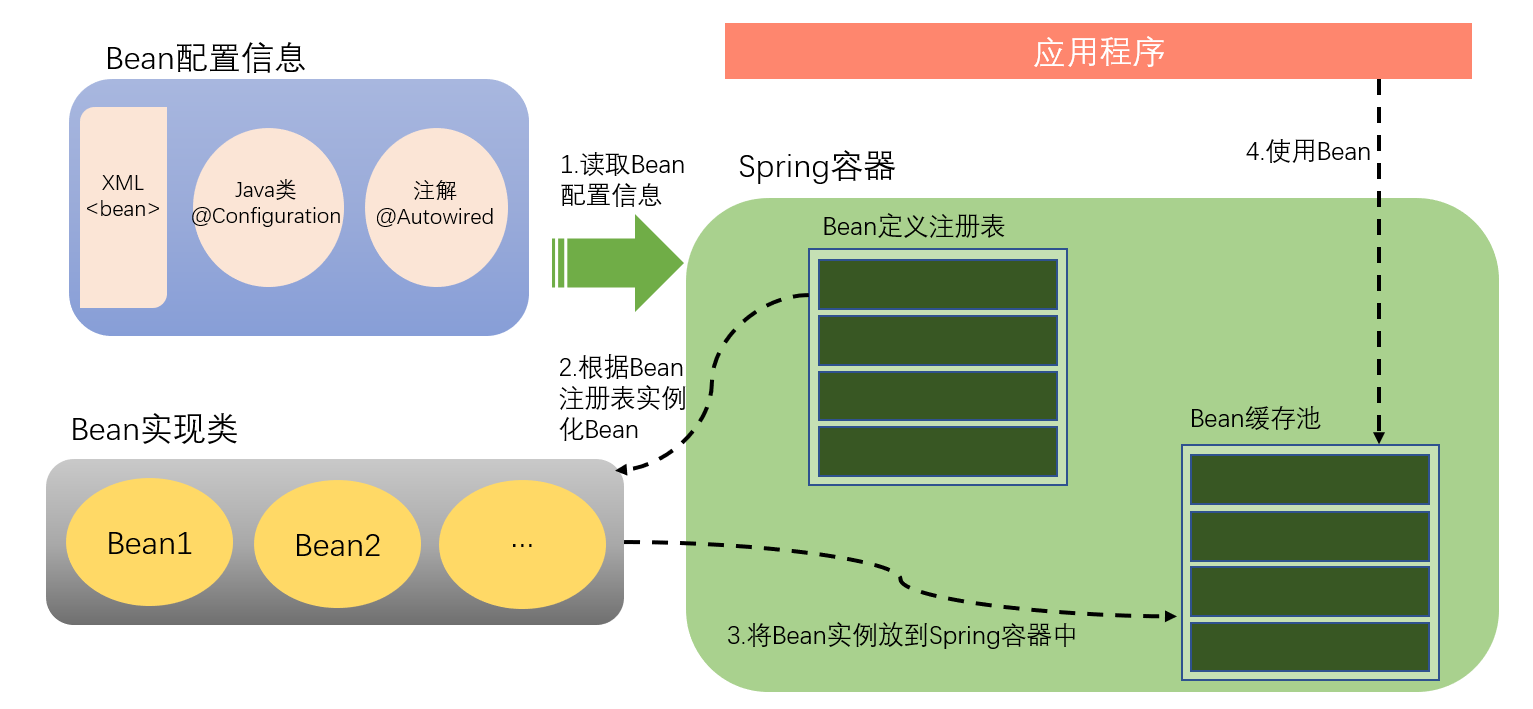
ICO容器的结构如上图所示,首先要让IOC容器去读取Bean的配置信息,并在容器中生成一份相应的Bean定义注册表,根据这张注册表去实例化Bean,装配好Bean之间的依赖关系,为上层提供准备就绪的环境,Spring提供一个配置文件描述Bean还有Bean之间的依赖关系,利用Java语言的反射功能实例化Bean并建立Bean之间的依赖关系。